[삼위일체(3조)] 프로젝트로 배우는 데이터 사이언스_2주차
2.1.1 당뇨병 데이터셋 미리보기
- 데이터 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0
EDA (탐색적 데이터 분석) 시작하기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline # 이 설정은 선택사항이지만 구버전 주피터를 사용한다면 필수로 설정해야함우선 라이브러리를 로드한다.
df=pd.read_csv("data/diabetes.csv")
df.shaperead_까지 작성하고 [tab 키]를 눌러 다양한 형식 파일을 가져올 수 있는데, 이 때 data 폴더에 있는 diabetes.csv 파일을 불러온다.
(768, 9) # 출력결과df.head() # 데이터 상위 5개 행 미리보기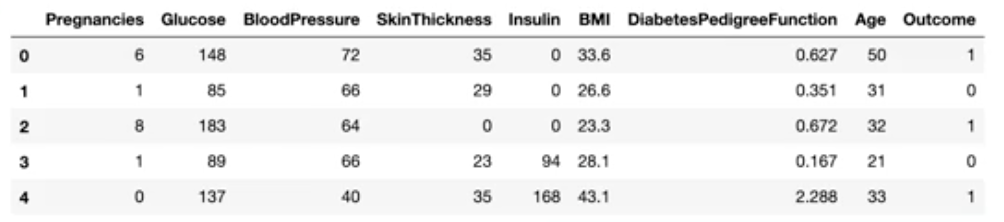
간단한 요약 정보 불러오기
df.info()info(): 데이터의 타입, 결측치, 메모리 사용량
출력 결과:
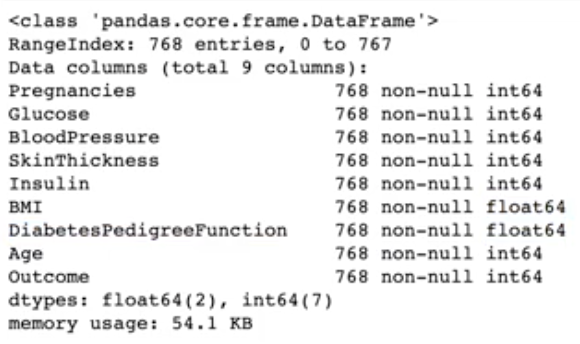
행의 개수 768, 열의 개수는 9개, 결측치가 아닌 값이 768 => 결측치가 없는 데이터셋이라는 것을 알 수 있으며,
모두 수치형으로만 이루어져 있음을 파악할 수 있다.
결측치 확인하기
df_null = df.isnull()
df_null.head()출력 결과 :

결측치가 없는 데이터셋이므로 전부 false 를 출력함.
df_null.sum()결측치의 수를 세어주는 코드인데, 위 데이터셋에는 결측치가 없으므로 전부 0으로 출력될 것을 예상할 수 있다.
출력 결과 :

df.describe(include="number") #수치데이터에 대한 요약값 살펴보기출력 결과 :

1사분위는 25%, 2사분위는 50%, 3사분위수는 75% 이다.
** 여기서 2사분위는 중앙값이다.
평균값이 중위값보다 높다?? >> max 값이 꽤 높다는 뜻!!
min을 보면 최소값이 모두 0인데 글루코스, 혈압, skinthickness(피부주름두께), BMI은 0일 수 없으므로 결측치일 가능성이 높다.
feature_columns = df.columns[0:-1].tolist()
feature_columns처음 시작열부터 마지막에서 2번째 열 [0:-1] 까지 가져와 list 형태로 만드는 코드이다.
출력 결과 :

2.1.2 결측치 보기
결측치 시각화를 해보자.
값을 요약해보면 최솟값이 0으로 나오는 값들이 있었는데, 이 값들 중 인슐린, 혈압 등은 0이 나올 수 없는 값들이므로
결측치라고 본다.
cols = feature_columns[1:]
cols결측치 여부를 나타내는 데이터프레임 (=cols 로 지정) 만들기
df_null = df[cols].replace(0, np.nan)
df_null = df_null.isnull()
df_null.sum()0값을 결측치라고 가정하고 정답 (label, target) 값을 제외한 컬럼에 대해 결측치 여부를 구한 후 df_null 이라는 데이터프레임에 담는다.
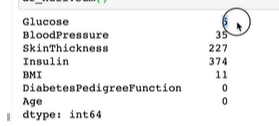
df_null.sum().plot.barh()결측치 수치를 시각화해보자.
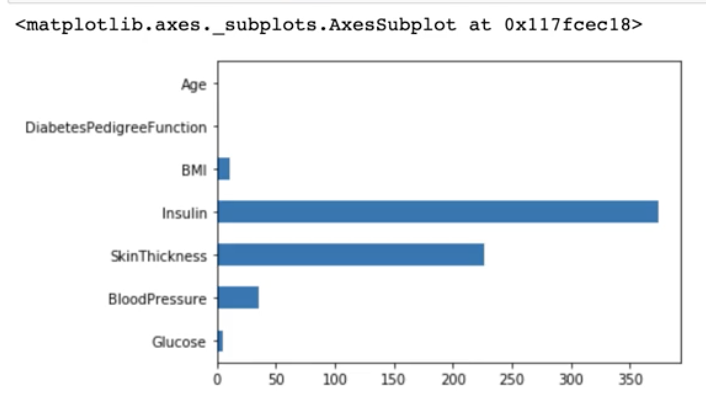
df_null.mean() * 100인슐린의 경우 전체 대비 48%가 결측치이며 skinthickness 의 경우에도 30% 가까이 결측치가 나오는 것을 확인할 수 있다.

plt.figure(figsize=(15, 4))
sns.heatmap(df_null, cmap="Greys_r")위에서 배운 df_null 값을 히트맵으로 그려보자.
plt.figure으로 시각화 그래프의 사이즈를 조절할 수 있고, cmap 옵션을 지정하여 색상을 grayscale로 변경할 수 있다.
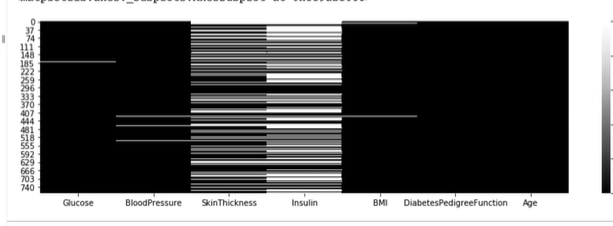
이와 같이 시각화를 하면 true 값(1)은 검정색으로 false 값(0)은 흰색으로 나타낼 수 있다.
part(2)
정답값
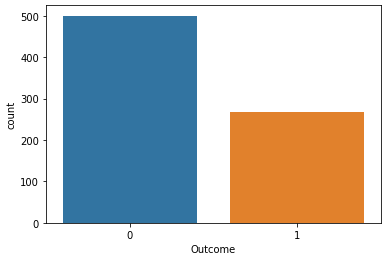
df["Outcome"].value_counts()#결과
0 500
1 268
Name: Outcome, dtype: int64
전체 df에서 Outcome 컬럼의 각 요소의 개수를 확인해보았다. 이를 비율로 바꾸면 아래와 같은 결과가 나온다.
df["Outcome"].value_counts(normalize=True)#결과
0 0.651042
1 0.348958
Name: Outcome, dtype: float64
Outcome의 값이 0인 비율과 1인 비율이 각각 0.651042, 0.348958인 것을 확인할 수 있었다.
아래는 이를 바탕으로 'Pragnancies' 컬럼과 함께 그룹화하여 새로운 변수로 저장한 결과이다. (결과 값이 0, 1밖에 없기 때문에 평균(mean)을 구해도 전체 중에 1에 해당하는 비율을 확인할 수 있다 ㄷㄷ.)
이를 표로 시각화 하면 우상향 경향을 띠는 것을 확인할 수 있다.

countplot
앞에서 확인했던 0, 1 비율을 막대그래프로 시각화 하면 아래와 같다.
그리고 이 둘을 합쳐 '임신횟수'에 따른 당뇨병 발병 빈도수를 하나의 시각자료로 나타낼 수 있다.
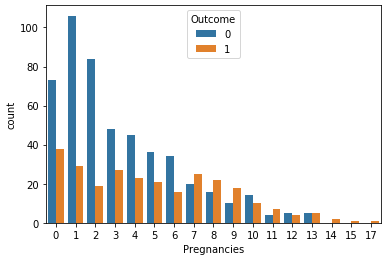
여기서도 마찬가지로 '임신횟수'값이 증가할수록 'Outcome'결과 중에서 '1'의 비율이 커지는 것을 확인할 수 있다. 이 사실을 조금 더 확실하게 확인할 수 있는 시각화를 진행해보았다.
'임신횟수'의 값이 7이상/미만을 기준으로 7이상이면 high 여부의 값을 true로 미만이면 false로 구분하는 새로운 열을 만든다. 그리고 이를 다시 시각화 하면 아래와 같은 결과가 출력된다.
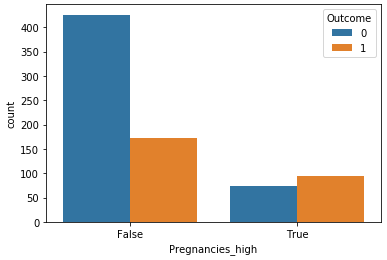
2.1.4 두 개의 변수를 정답값에 따라 시각화 해보기
학습 목표
- 2개의 변수를 시각화할 수 있는 그래프를 이해하고, 사용할 수 있다.
핵심 키워드
- barplot
- boxplot
- violinplot
- swarmplot
barplot
당뇨병 발병에 따른 BMI 수치를 비교합니다.
x축을 "Outcome", y축을 "BMI"로 하는 barplot을 그립니다.
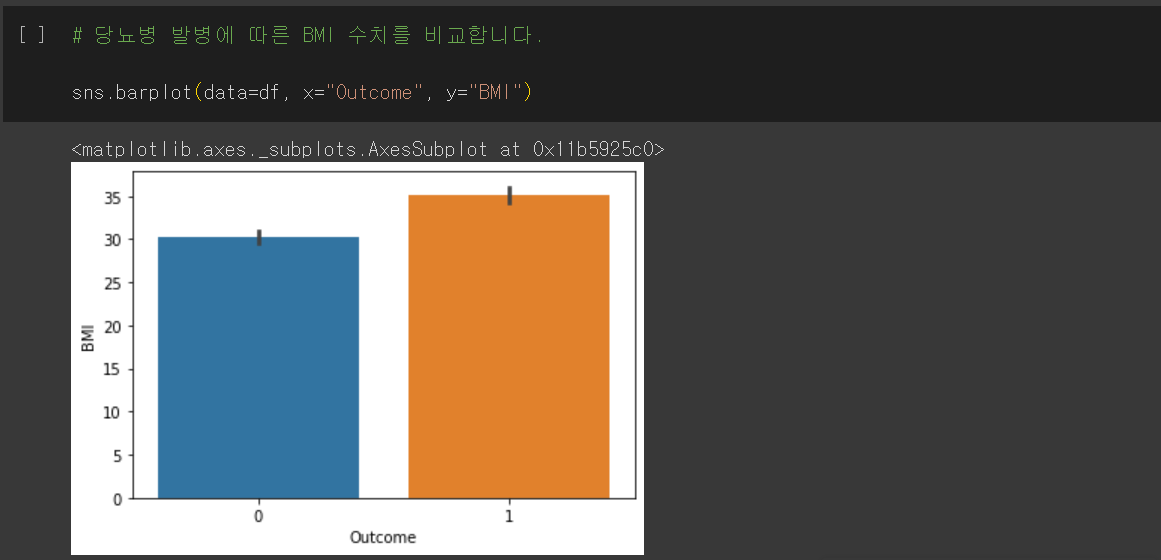
당뇨병이 발병하지 않은 경우의 BMI는 30, 당뇨병이 발병한 경우의 BMI는 35로 수치에 약간 차이가 있습니다.
당뇨병 발병에 따른 포도당(Glucose) 수치도 비교합니다.
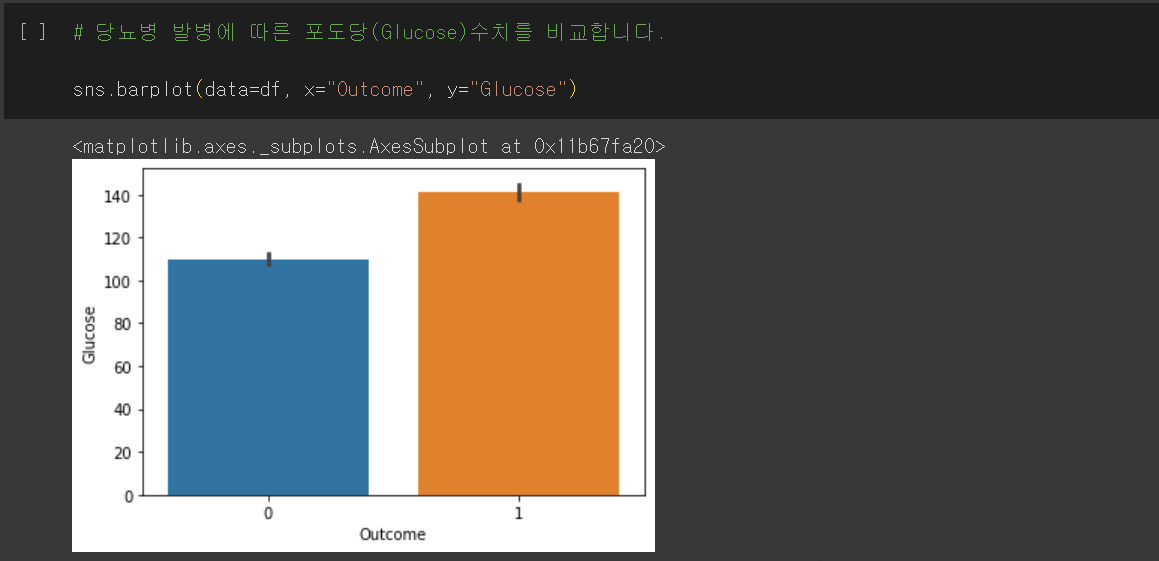
포도당(Glucose) 수치 또한 차이남을 알 수 있습니다.
이번에는 Insulin 수치가 0 이상인 관측치에 대해서 당뇨병 발병을 비교해보겠습니다.
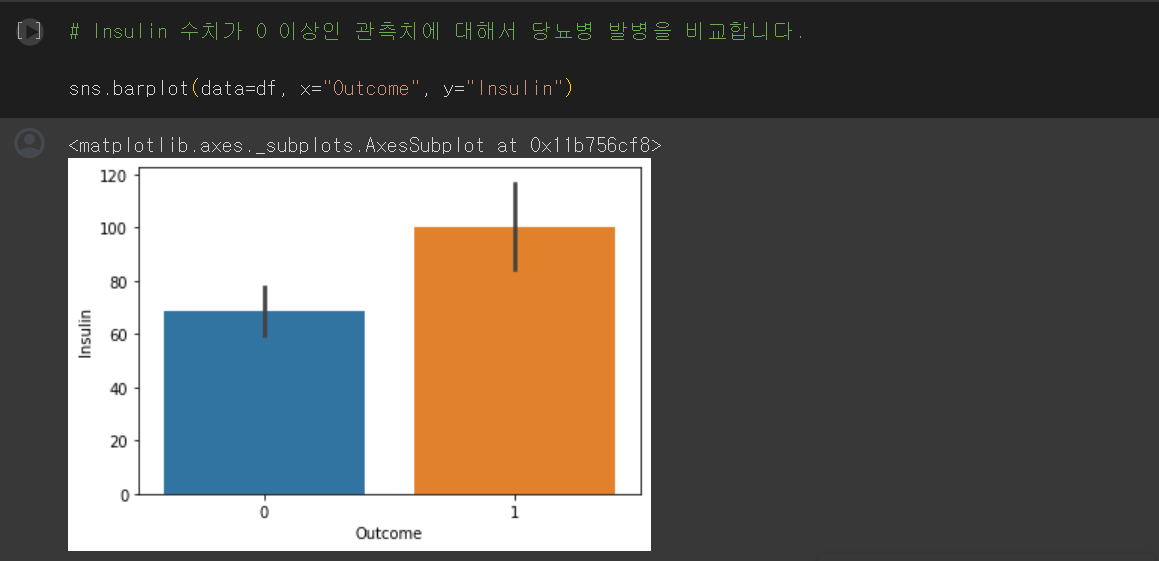
이떄 y축의 수치(0, 20, 40, ..., 120)는 평균값을 나타냅니다.
그래프 위에 세로로 그려진 까만 선은 데이터 일부를 샘플링하여 95%의 신뢰구간을 나타내는데, 이 신뢰구간의 차이가 크다고 볼 수 있습니다.
임신 횟수에 대해서 당뇨병 발병 비율을 비교합니다.
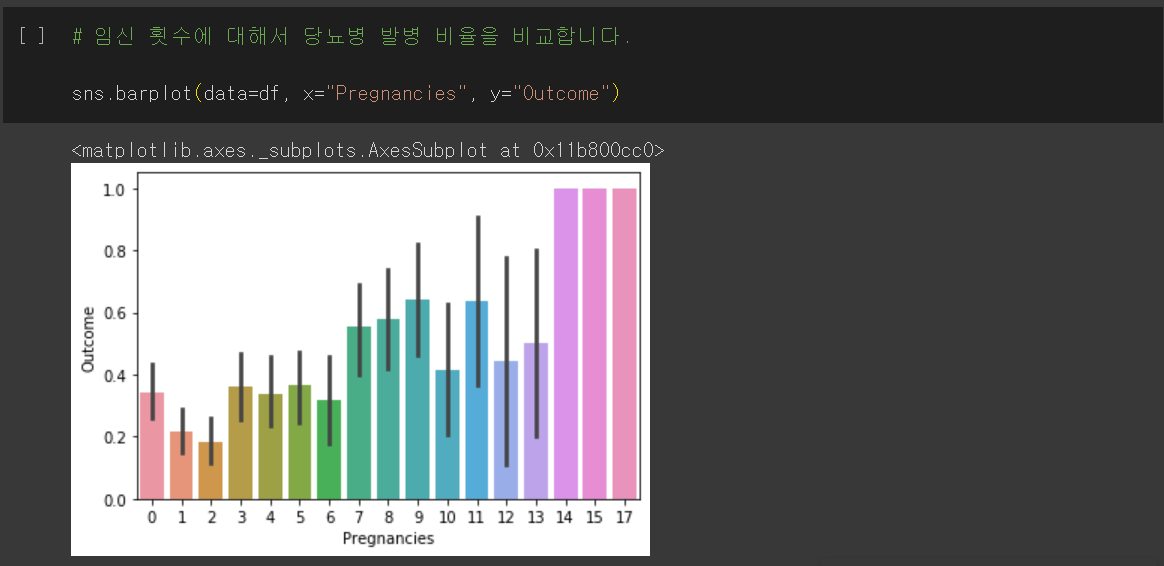
이때 y축(Outcome)은 평균값을 나타내기 때문에 이 수치를 비교하여 당뇨병 발병 비율을 비교할 수 있습니다.
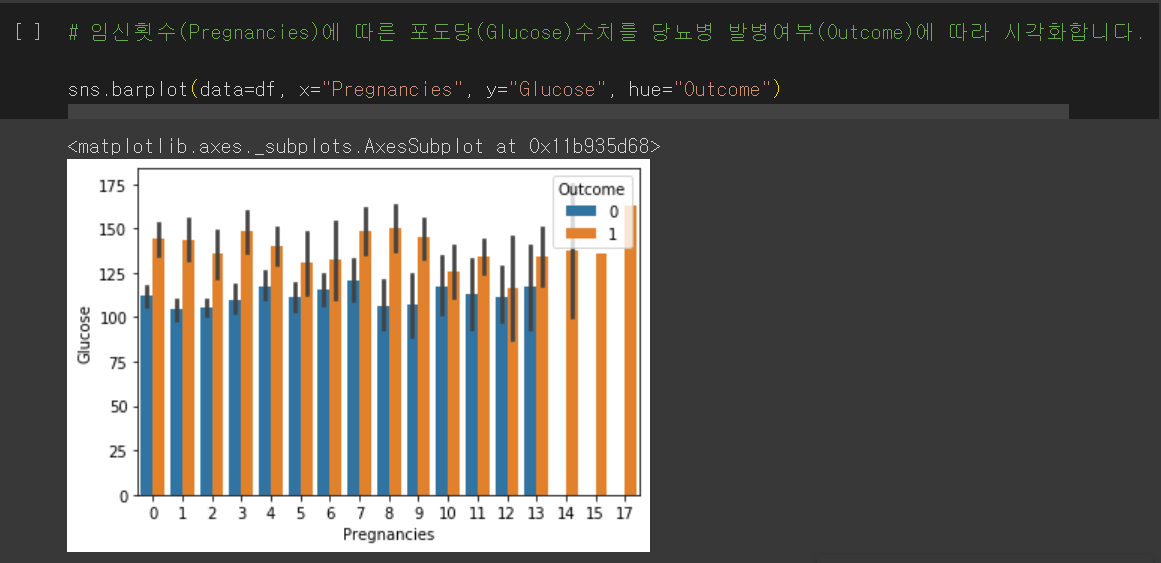
1. 임신 횟수에 따른 포도당(Glucose) 수치를 당뇨병 발병 여부에 따라 시각화
위의 Pregnancies 그래프를 그대로 가져와 Gloucose 그래프를 그려보겠습니다.
임신 횟수(Pregnancies)에 따른 포도당(Gloucose) 수치를 당뇨병 발병 여부(Outcome)에 따라 시각화할 수 있습니다.
x축에는 "Pregnancies", y축에는 "Gloucose", hue 값에는 "Outcome"을 입력해줍니다.
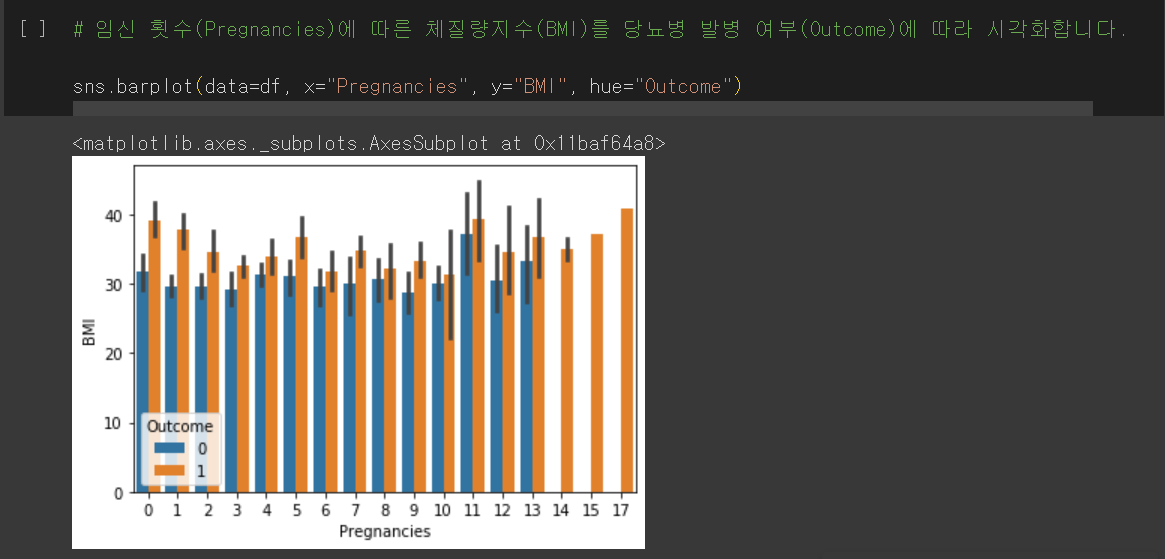
2. 임신 횟수에 따른 체질량지수(BMI)를 당뇨병 발병 여부에 따라 시각화
이번에는 임신 횟수(Pregnancies)에 따른 체질량지수(BMI)를 당뇨병 발병 여부(Outcome)에 따라 시각화합니다.
3. 임신 횟수에 따른 인슐린(Insulin) 수치를 당뇨병 발병 여부에 따라 시각화
마지막으로 임신 횟수(Pregnancies)에 따른 인슐린(Insulin) 수치 또한 당뇨병 발병 여부(Outcome)에 따라 시각화합니다.
이때 인슐린 수치에는 결측치가 많기 때문에 0보다 큰 값에 대해서만 그립니다.
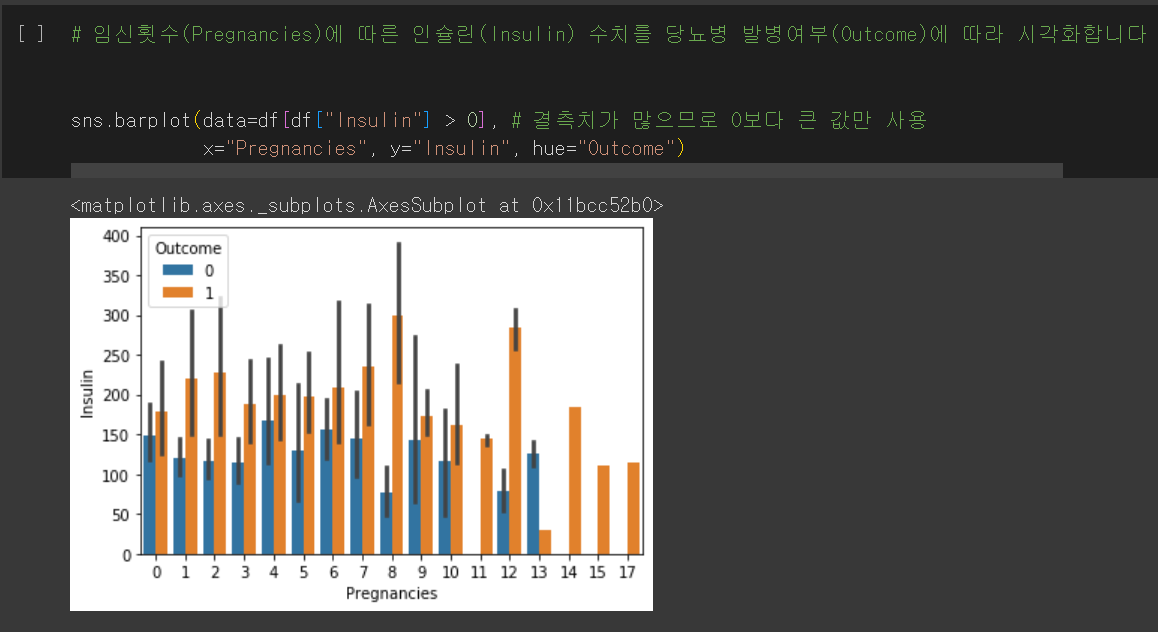
발병하는 사람들의 인슐린 신뢰구간의 차이가 많이 난다는 것을 알 수 있고, 발병하지 않는 경우는 인슐린 수치가 낮음을 알 수 있습니다.
boxplot

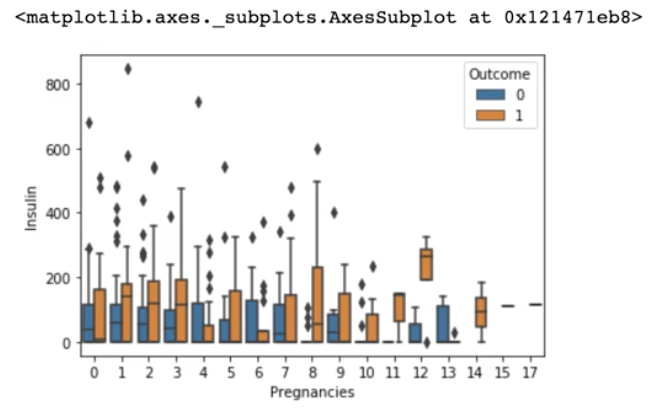
Insulin 수치에 대한 boxplot을 나타낸 것입니다.
box마다 나뉘어진 두 부분이 각각 1사분위수와 3사분위수인데, 이 두 사분위수 값의 차이가 크고, 최댓값과 최솟값의 차이도 큽니다.
또한 Insulin 값으로 0이 많으므로 boxplot이 주저앉은 것을 볼 수 있습니다.
따라서 Insulin 수치가 0보다 큰 값들로만 boxplot을 다시 그립니다.
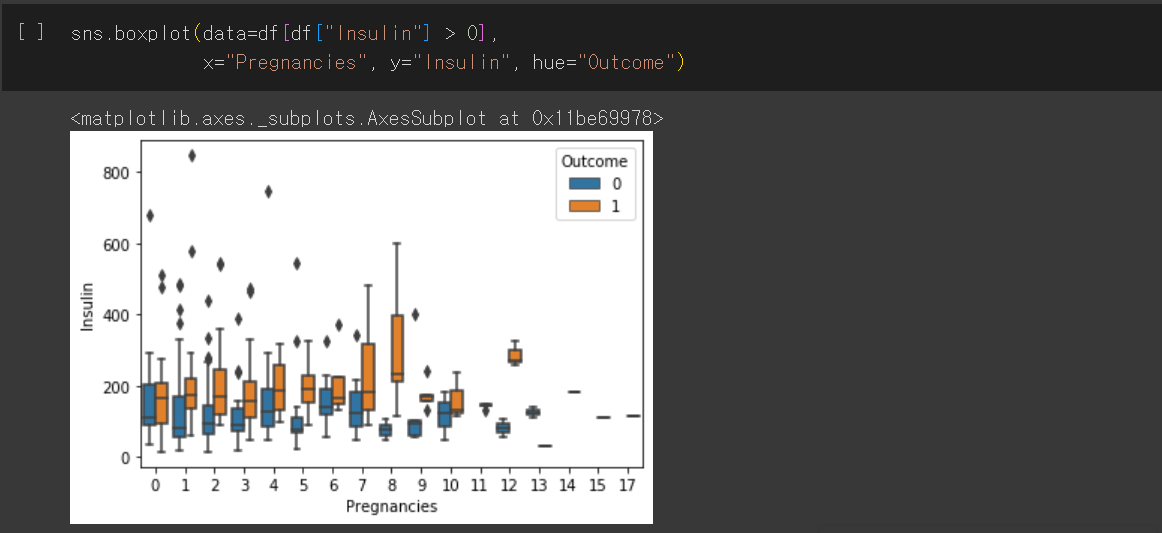
이렇게 Insulin의 범위를 재설정했을 때 boxplot이 주저앉지 않은 채로 나타낼 수 있습니다.
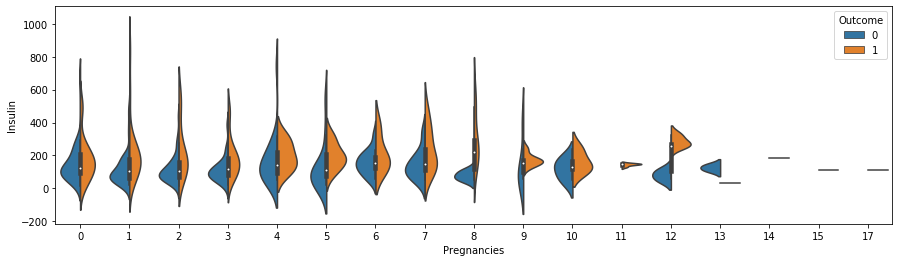
violinplot
이제 violinplot으로 위의 그래프를 시각화해보겠습니다.

그림의 크기를 (15, 4)로 설정하고, "Insulin"이 0보다 큰 경우에 대해서만 데이터를 사용합니다.
이때 'split=True'는 violinplot의 각 바이올린을 분할하여 반씩 표시하도록 하는 매개변수입니다. 이 매개변수를 사용하면 "hue" 매개변수에 지정된 범주형 변수에 따라 데이터를 분할하여 각 범주에 대한 분포를 비교할 수 있습니다.
위의 코드에서 "Outcome"이라는 범주형 변수를 "hue"로 사용하고 'split=True'를 설정하면 "Outcome"의 각 범주(예: 당뇨병 발병 여부)에 대해 violinplot을 그릴 때, 해당 범주에 속하는 데이터를 두 부분으로 나누어 각각의 바이올린 모양을 표시합니다. 이를 통해 두 범주 간의 분포 차이를 시각적으로 비교할 수 있습니다.
결과:
<matplotlib.axes._subplots.AxesSubplot at 0x11be4ab38>
swarmplot
이번에는 swarmplot으로 Insulin 수치에 대한 boxplot을 시각화해보겠습니다.
swarmplot은 산포도를 그리는 데 적합합니다. split은 violinplot에서만 사용 가능하므로 split을 지워줍니다.

결과:
<matplotlib.axes._subplots.AxesSubplot at 0x11bc83710>
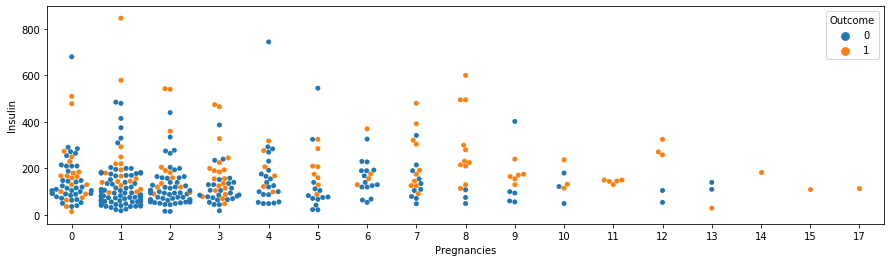
주황색이 발병하는 케이스("Outcome"=1)입니다. viloinplot과 swarmplot을 찍으면 데이터 수를 확인할 수 있습니다.
이를 통해 임신 횟수는 당뇨병 발병률과 관련이 있는 것을 확인할 수 있습니다.
2.1.5 수치형 변수의 분포를 정답값에 따라 시각화 해보기
학습 목표
- 수치형 변수의 분포를 시각화할 수 있는 distplot을 이해하고, 활용할 수 있다.
핵심 키워드
- distplot
distplot
막대 그래프인 countplot은 카테고리형 데이터를 시각화할 때 사용하는 반면,
displot은 선 그래프로 1개의 수치형 변수를 표현할 때 사용하는 시각화 그래프입니다.
distplot은 다른 그래프와 달리 data 옵션 없이 바로 Series 데이터를 넣어줍니다.

결과:
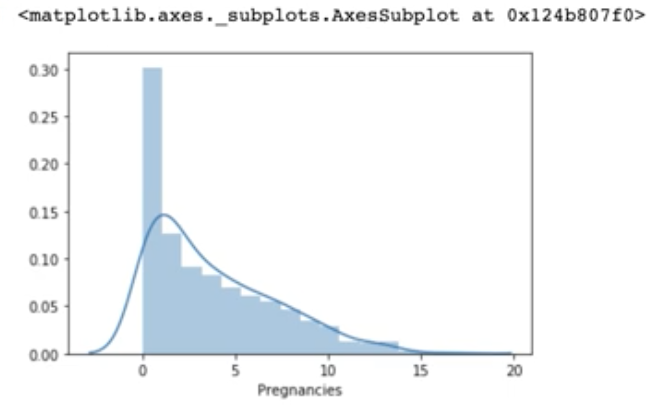
발병하는 케이스와 발병하지 않는 케이스를 각각 변수에 넣어줍니다.

1. 임신 횟수(Pregnancies)에 따른 당뇨병 발병 여부를 시각화합니다.

결과:
<matplotlib.axes._subplots.AxesSubplot at 0x11e3817f0>
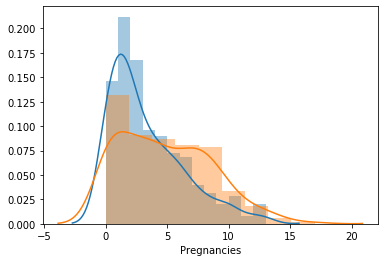
임신 횟수가 5가 넘어가면 발병률이 더 높아집니다.
2. 나이(Age)에 따른 당뇨병 발병 여부를 시각화합니다.

(1) hist 옵션을 False로 지정하면 부드러운 곡선만 그려줍니다.
(2) 아래에 카펫 같은 rug를 만들어줍니다.
(3) 어떤 색상이 어떤 데이터인지 알기 어려우므로 label을 지정해줍니다.
결과:
<matplotlib.axes._subplots.AxesSubplot at 0x11e699080>
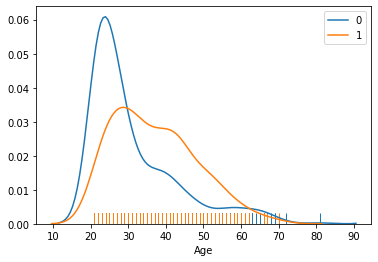
30세 이후에 발병하는 케이스가 더 많은 것을 확인할 수 있습니다.
2.1.6 서브플롯으로 모든 변수 한번에 시각화 하기
학습 목표
- 다양한 변수의 상관관계를 subplot에 그래프로 나타낼 수 있다.
핵심 키워드
- subplot
- displot
pregnacies하고 age 두 개의 변수에 대해서만 그렸는데요.
이제 모든 수치형 변수에 따라서 서브 플롯을 그려보고 싶습니다.
그래서 pands에서 제공하고 있는 df.hist를 통해서 이렇게 그래프를 그려볼 수가 있는데
keyError 오류가 난 것을 볼 수 있습니다.
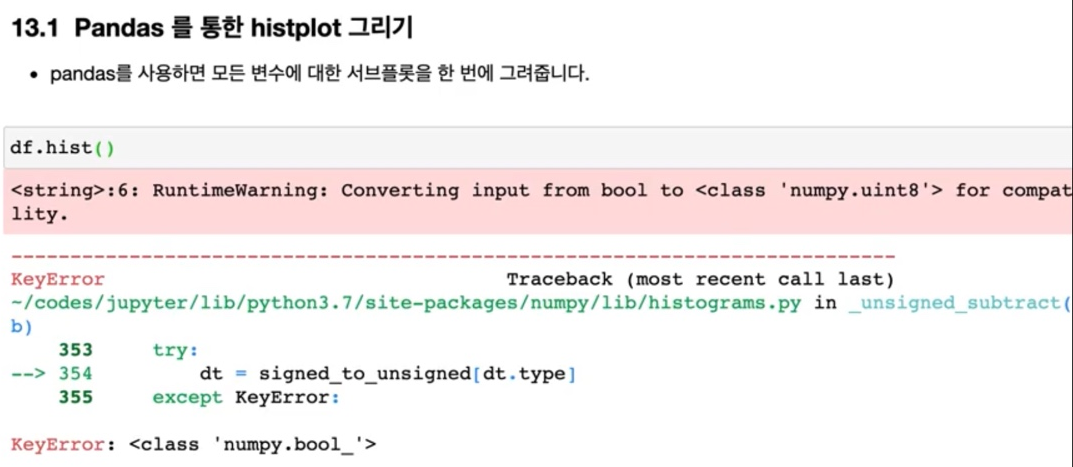
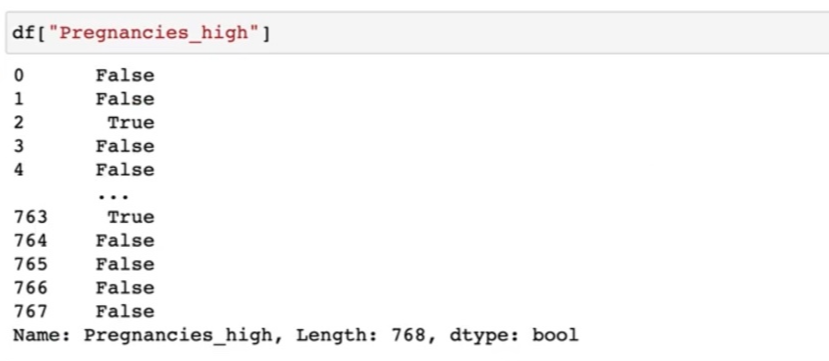
> numpy.bool이라고 오류가 났는데 오류가 난 이유는 df 출력을 해보게 되면
이전 학습에서 pregnancies_high 라는 컬럼을 bool 값으로 만들어줬었습니다.
>그런데 이 histplot을 그릴 때 여기에서는 이 bool 값을 지원을 하지 않기 때문에 오류가 났고,
이 값을 .astype(int)로 바꿔줘야 합니다.
> pregnancies_high가 bool 타입에서 int 타입으로 변경이 되었습니다.
> 하지만 반영이 안 되지 않는 것을 볼 수 있습니다.
>그래서 꼭 할당을 해야 이 pregnancies_high라는 컬럼에 반영이 됩니다.
> 확인해 보면 pregnancies_high가 true/false값에서 0과 1 값으로 바뀐 걸 확인해 볼 수가 있습니다.
그러면 이 상태에서 이제 히스토그램 그려보도록 할 텐데요.
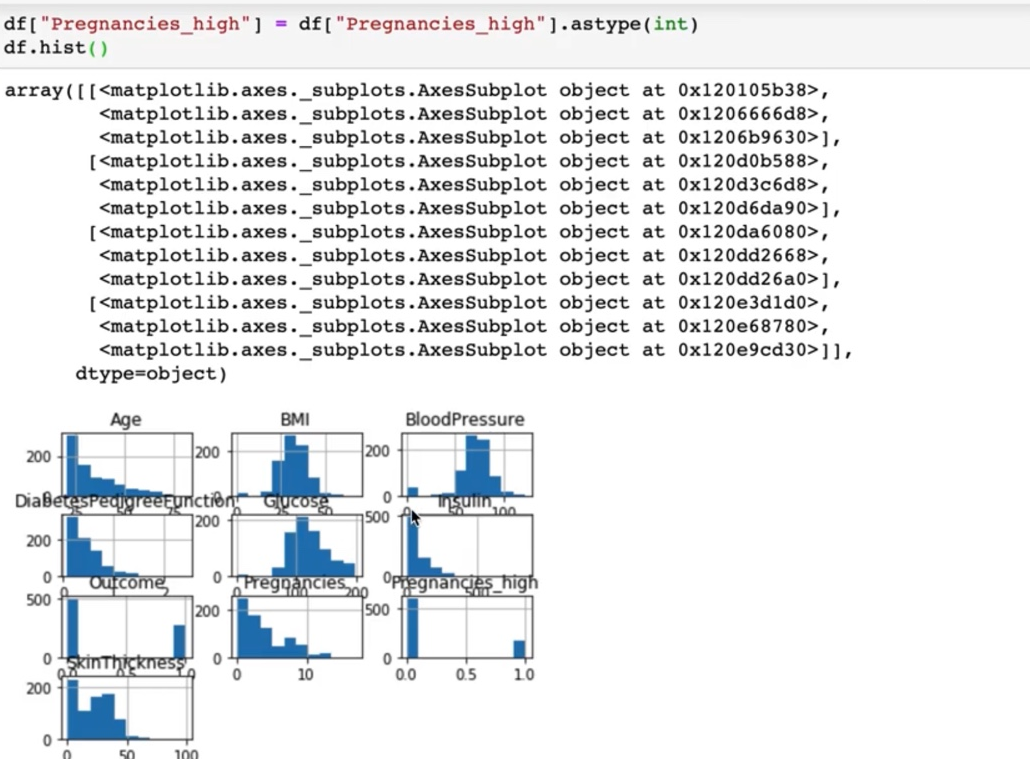
히스트라고 그려보도록 할겠습니다. 그러면 히스토그램이 한번에 표시가 되는 것을 볼 수 있습니다.
h라는 변수에 할당해서 그리게 되면 위에 그래프보다 조금 더 깔끔하게 그래프를 나타낼 수 있습니다.
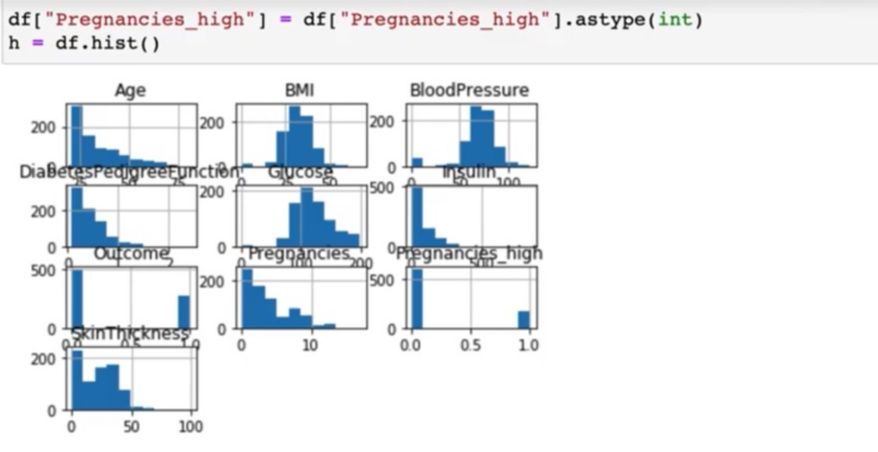
그래프 사이즈도 좀 넓게 그리고 싶을 때는 figsize를 이용하면 됩니다.
15,15 정도로 넓게 그려보았습니다.
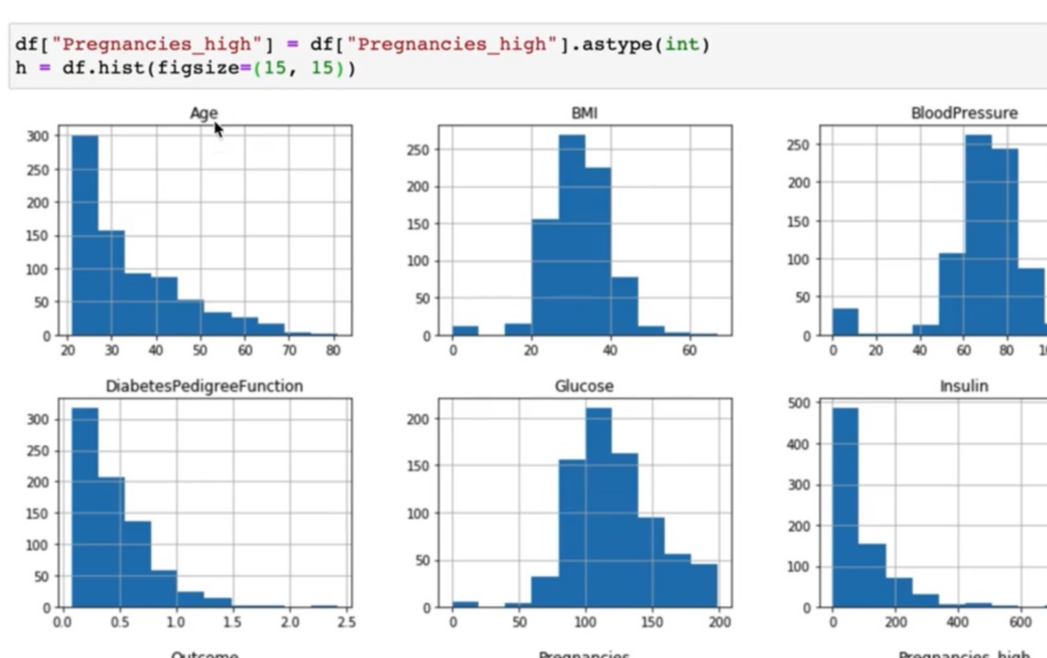
> age, BMI, bloodpressure 등이렇게 다양한 변수에 대해서 그래프를 시각화한 것을 볼 수가 있습니다.
이렇게 시각화한 데이터를 보면 막대의 개수가 있습니다. 막대의 개수를 조금 넓게, 여러 개 그려보고 싶다면 bins 설정을 통해 막대의 개수를 조정할 수 있습니다.
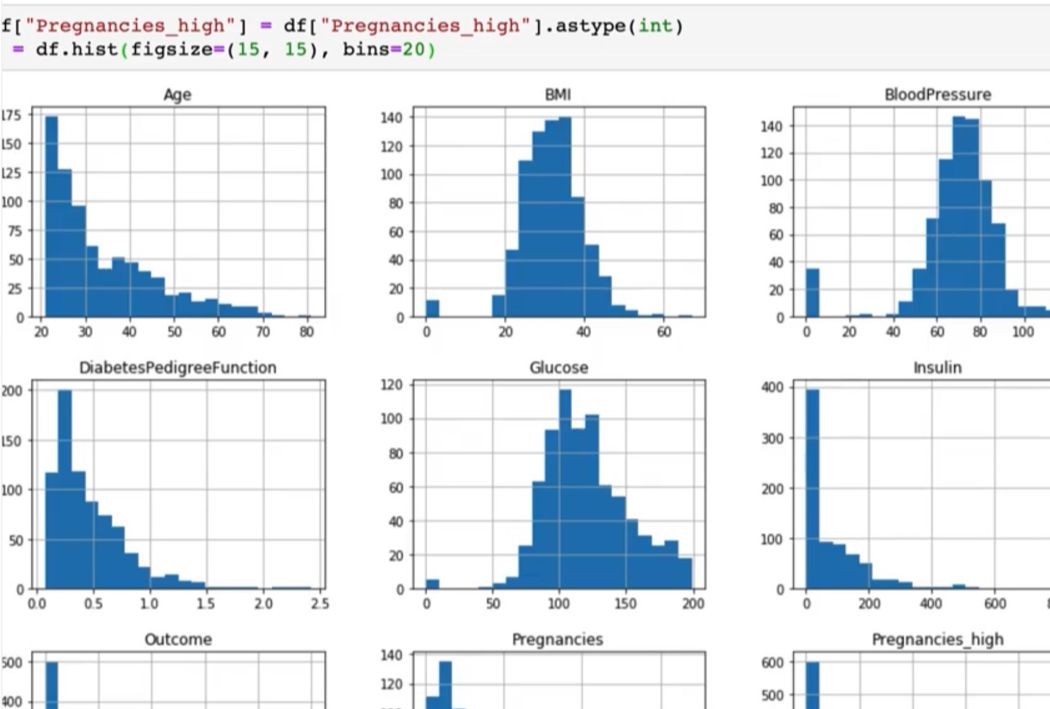
그래서 조금 더 자세하게 표현을 해보고 싶다 할 때는 이 막대의 개수를 조정을 해서 그래프의 모양을 변경을 해볼 수 있습니다.
다음으로, 반복문을 통해서 서브플롯을 그려볼 수 있습니다.
모든 변수에 대해서 다 그리고 싶다라고 할 때는 이제 컬럼 수만큼 for문을 만들어서 디스트 플롯을 그려보겠습니다.

> df.columns하게 되면 모든 컬럼들을 다 가져오게 됩니다.

> 그리고 여기에서 .shape하게 되면은 지금 컬럼의 개수가 10개라는 것을 확인해볼 수 있습니다.

> col_nm이라는 변수에다가 담아주었습니다. col_nm이라는 변수에 컬럼의 개수가 들어갔습니다.
이제 distplot으로 이제 서브 플롯을 그려볼 것입니다.
plt.subplots 라고 하게 되면은 이 subplots로 서브 플롯을 그릴 수 있습니다.

> 이 서브 플롯의 옵션은 nrows=1, ncols=1이 들어가게 되는데, 10개를 그리겠다고 하면 nrows는 계산하기 쉽게 9개만 그려보도록 하겠습니다. nrows는 3개, ncols는 3개
figsize 를 이용하여 조금 넓게 15,15 정도로 그려보았습니다.
> 지금은 비어 있는 서브 플롯을 그렸습니다. 이 비어있는 서브플롯을 distplot으로 채워보도록 할 것입니다.
fig, axes라고 변수에다가 할당을 해주도록 하겠습니다.

이 안에다가 그래프를 하나씩 채울 건데, 일단 하나 먼저 그려보도록 하겠습니다.
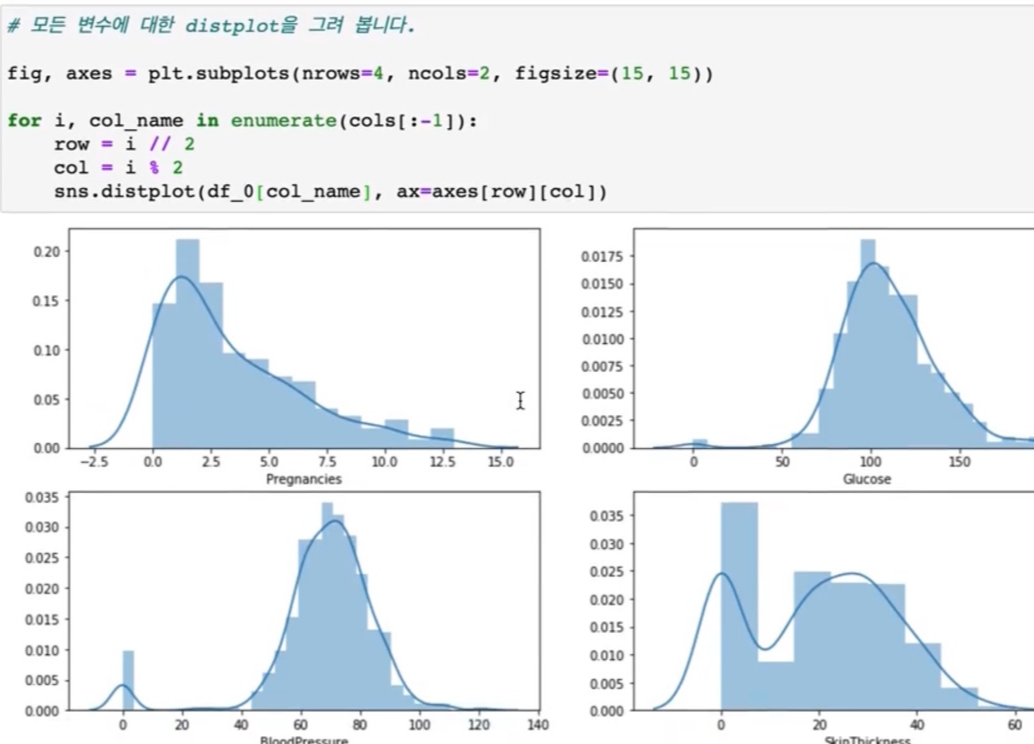
sns.distplot(df)의 outcome col을 그려보도록 하겠습니다.
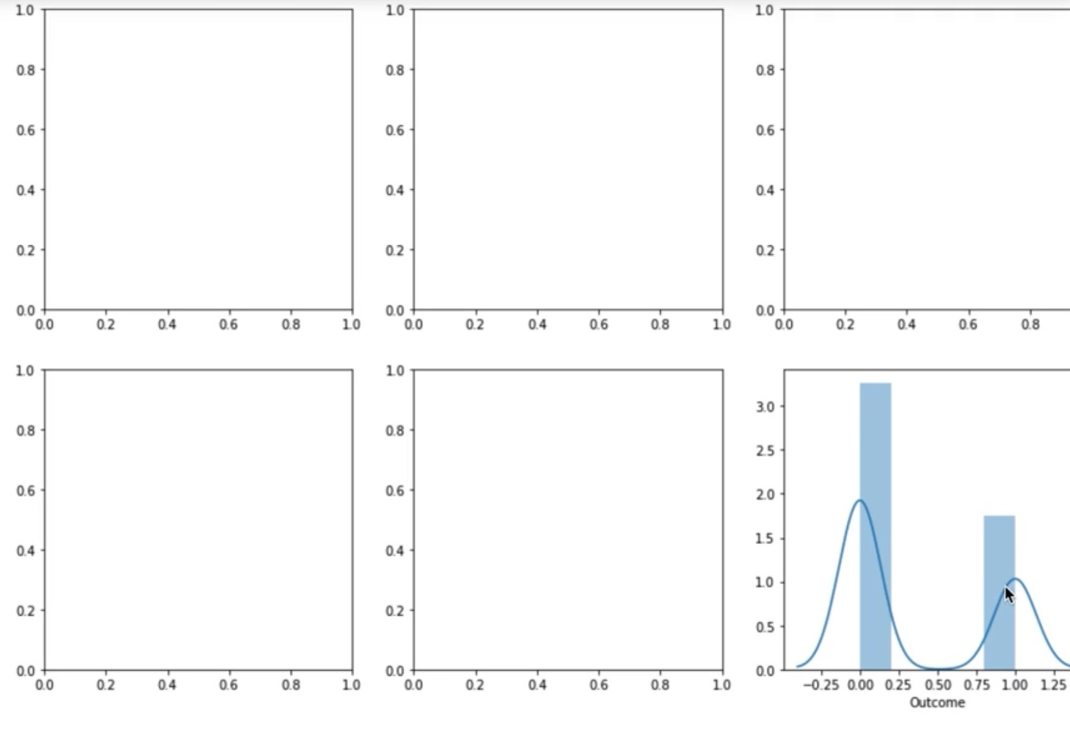
> outcome col이 맨 끝에 가서 그려지는 걸 확인할 수 있습니다.
이제 이 그래프를 몇 번째에다가 지정을 해줄 건지 설정해줄 것입니다.
ax=axes 0번째, 0번째 맨 앞에다가 지정을 하고 싶다라고 하게 되면은
아래 보이는 코드를 통해서 내가 지정하고자 하는 그래프의 위치를 지정을 해줄 수 있습니다.
> 1, 1 로 설정하면, 0번째부터 이 인덱스가 시작을 하게 됩니다.
> 가운데에 그려주겠습니다.
모든 컬럼에 채우고 싶습니다.
컬럼들을 수행하면서 일단 이 distplot은 주석 처리를 하겠습니다.
for i in range(9): 를 이용해서 9개를 돌아가면서 출력을 하겠습니다.
> 0부터 8까지 출력됩니다.
> 컬럼들 전부 다 보는 것이 아니라 columns에 -1해서 아웃컴까지만 보도록 하겠습니다.
> 슬라이싱을 통해서 마지막 값을 빼고 가져온 것을 볼 수 있습니다.
df.columns.tolist로 이제 리스트 형태로 만들어주는 것까지 하게 되면 이 리스트를 순회하면서
다시 cols라는 변수에 지정을 해주도록 하겠습니다.
for문을 도는데 이제 range로 cols를 도는 게 아니라 enumerate라는 걸 통해서 이 cols를 순회하도록 해보겠습니다.
> enumerate로 for문을 순회하게 되면은 여기 인덱스 값하고 col_name 값하고 같이 갖고 오게 됩니다.
i ,col_name을 출력을 해보도록 할게요.
> pregnacies부터 outcome까지 가져오게 됩니다.
이제 이 9개의 밸류를 각각의 서브 플롯에 하나씩 넣어줄 것인데,
넣어주기 위해서는 여기에 이제 좌표 값을 알아야 합니다.
> 행과 열의 값을 맞춰줘야 합니다.
i라는 값에 3개씩 들어가니까 3개씩 나눠서 이거를 행의 값으로 만들도록 하겠습니다.
col_name 뒤에다가 row 한번 출력해보도록 하겠습니다.
> 뒤에 소수점이 찍히게 되는데, 한 번 더 해주게 되면은 소수점을 제외하고 계산하게 됩니다.
> 소수점 제외한 유형이 계산되었습니다.
> 그래서 0번째 행 에는 pregnancies부터 bloodpressure까지 들어가고, 첫 번째 행에는 skinthickness부터 BMI까지 들어갑니다. 그다음에 마지막 행 이렇게 값이 들어가게 될 것입니다.
칼럼의 이름 col의 이제 인덱스 값은 i %3으로 지정을 해보도록 하겠습니다.
그다음에 col 값도 같이 출력을 해줄 텐데요.
그러면 서브 플롯에 인덱스를 지정해 줄 수가 있을 것입니다.
> 그럼 이렇게 지정한 서브 플롯 여기에서 outcome이 아니라 col_name을 지정해줄 수가 있겠습니다.
col_name을 지정을 해주고 ax=axes에 앞에는 row, 뒤에는 col의 행과 열의 번호를 넣어주고 이 서브 플롯을 그려보도록 하겠습니다.
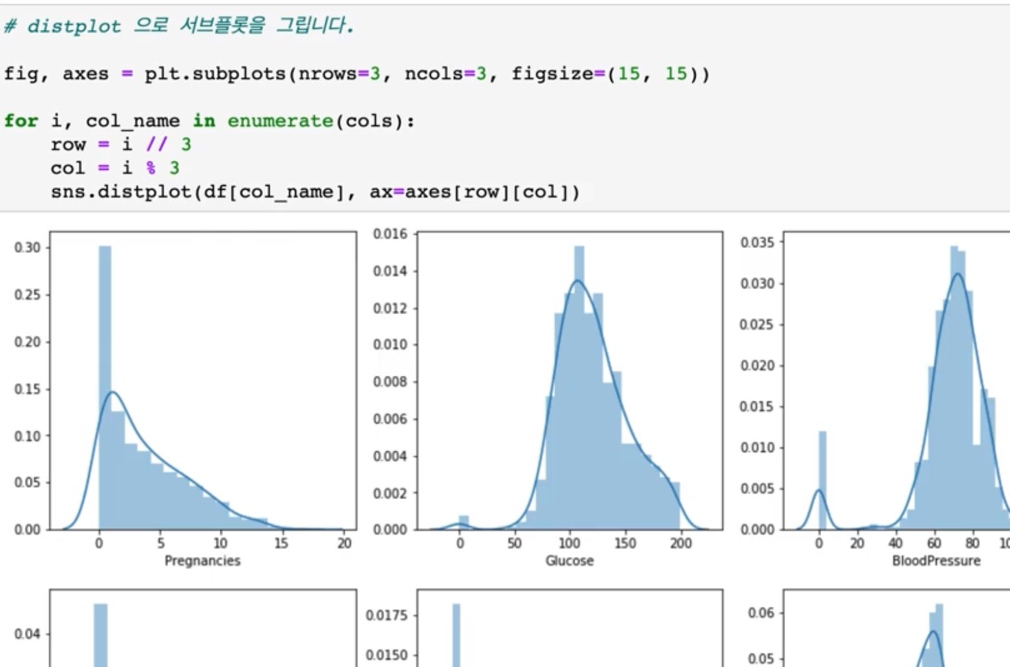
> 디스트 플롯으로 서브 플롯을 그려보았습니다.
> 전체 변수에 대해서 여기 이전에 그렸었던 히스토그램으로 그리게 되면 한 번에 훨씬 더 편리하게 그릴 수가 있습니다.
> 히스토그램은 이제 빈도 수를 y축 값에 표현을 해주고, distplot 같은 경우에는 이 값을 적분했을 때의 1이 되는 값을 이 왼쪽에 표시를 해주고 있습니다. 그래서 값이 표시해 주는 값이 다른 것입니다.
> 그다음에 이 distplot 같은 경우에는 이 부드러운 밀도 함수를 같이 계산을 해서도 그려주고 있다 라는 게 차이점일
것입니다.
그럼 distplot 전체적으로 그려봤는데,이렇게 전체적으로 그린 것에서 이제 outcome 값을 기준으로 한번 distplot을 다시 그려보도록 하겠습니다. outcome 값이 있냐 없냐에 따라 다르게 그려볼 건데, 이번에는 df에서 outcome 값이 있느냐 없느냐로 한번 보도록 하겠습니다.
> 여기에서 저희가 모든 컬럼 사용하지 않고 9개까지 age까지 그렸습니다.
> 여기에서 outcome 값으로 구분해서 볼 것이라 이제 8개로 그려보도록 하겠습니다.
그러면은 여기 행의 개수를 4개로 col의 개수를 2개로 줄이도록 할게요.
왜냐하면은 age까지만 그릴 거니까.
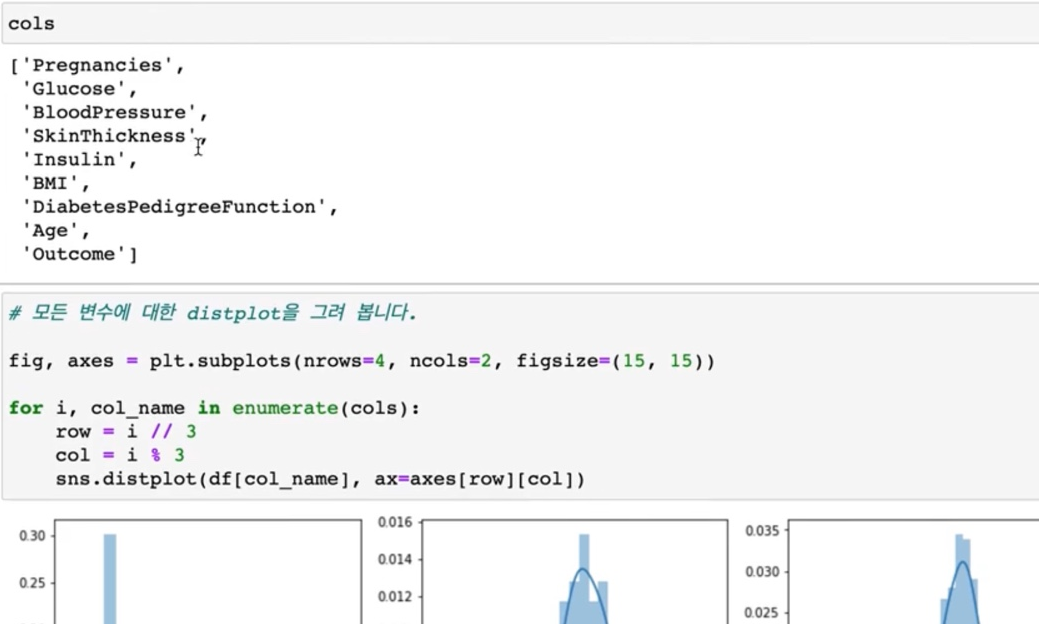
> 그래서 여기에 cols도 다시 한번 가져와서 보도록 하겠습니다.
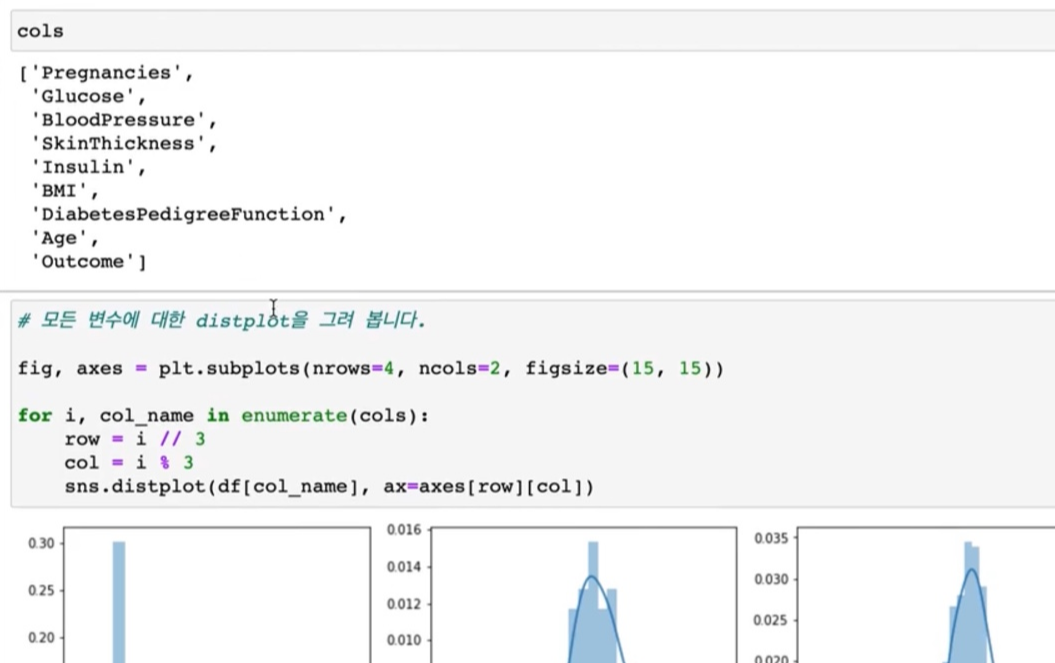
> cols 보게 되면 지금 outcome까지 나오는데 outcome 값은 빼고 그릴 것입니다.
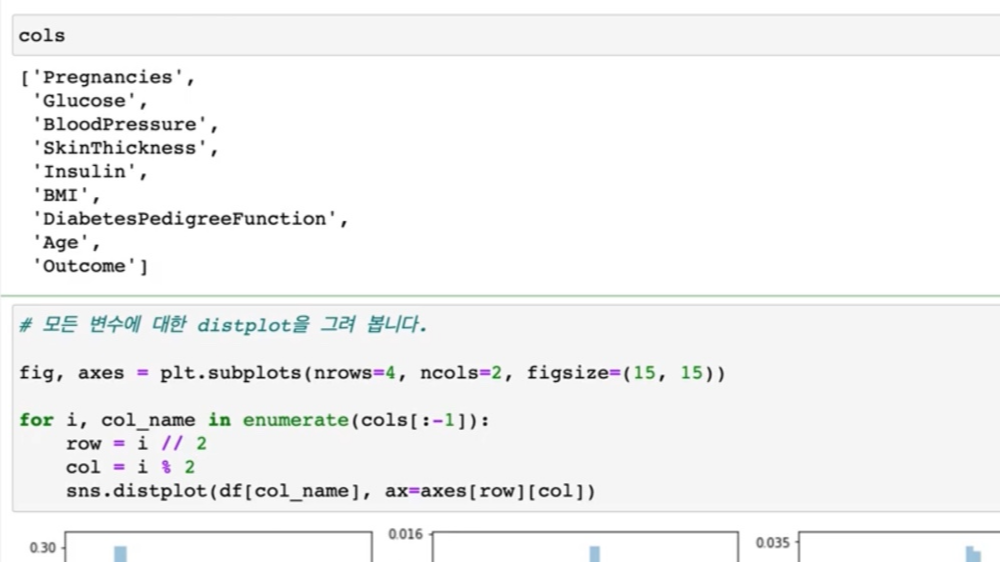
outcome값에 따라서 다르게 구분을 해서 그릴 것이기 때문입니다.
그래서 이제 4개 2개로 그릴 것이고, 그다음 나눌 때는 2로 나눠주도록 하겠습니다.
다시 한번 그려보게 되면, 4개의 행과 2개씩 그래프를 나눠서 그리게 되는데 이 값을 당뇨병 발병 여부에 따라서 나눠서 그리고 싶습니다.

그러면은 일단 df에서 outcome 값을 보도록 할겠습니다.
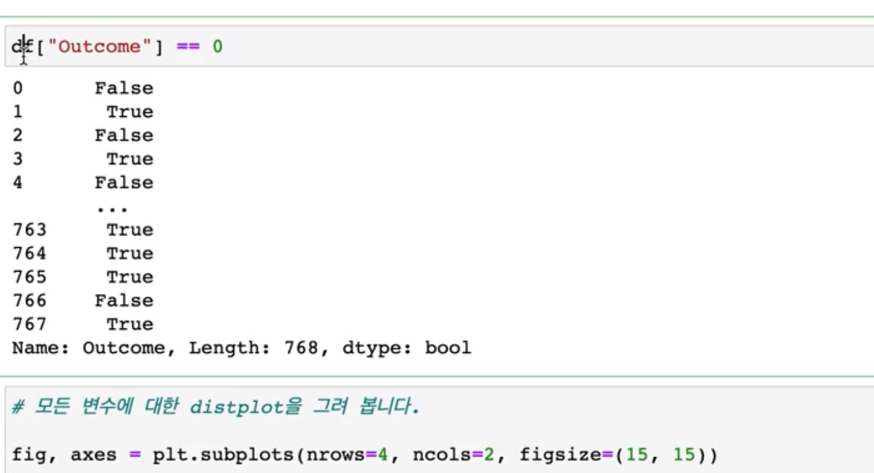
> outcome이 0일 때, 1일 때의 값을 subset을 가져와서 그려보도록 할 텐데
이미 예전 학습에서에서 df_0과 1이라는 서브 셋을 이미 만들어놨었습니다.
여기에서 df_0 하고 그려보도록 하겠습니다. 그러면은 이전 영상에서 만들었던 0 값으로 그리게 되고,
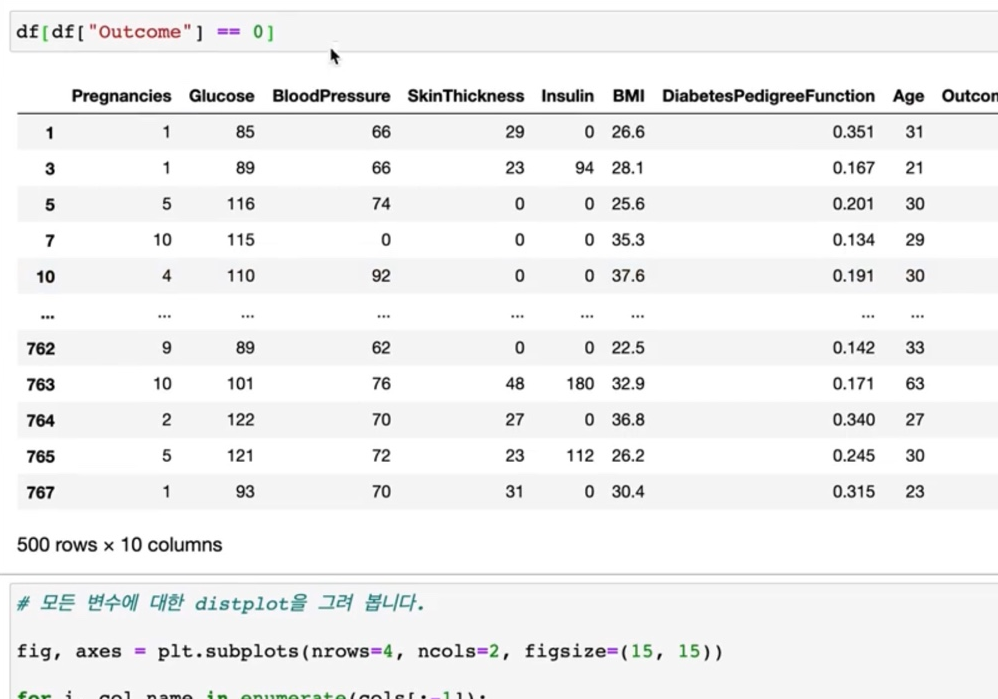
그다음으로 df_1 하게 되면, outcome이 1인 값에 따라서 색상이 다르게 표현됩니다.
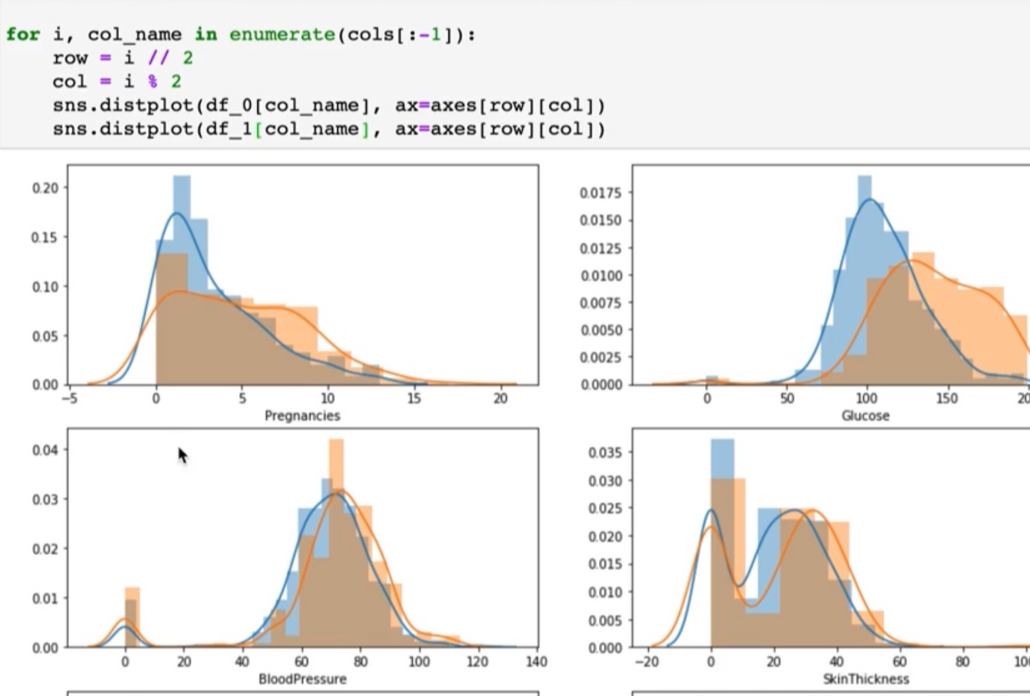
그래서 이전 학습처럼 pregnacies 특정 수치를 기준으로 당뇨병 발병 비율이 이렇게 나뉘게 됩니다.
glucose 같은 경우에도 특정 값을 기준으로 발병률이 높고 낮고가 달라지게 됩니다.
Bloodpressure는 그렇게 큰 차이는 없어 보입니다.
BMI 지수도 물론 이 BMI 지수가 높은 사람들이 발병률이 더 높기는 하다라고 보여집니다.
age도 특정 값을 기준으로 발병률이 높고 낮고를 이제 확인해 볼 수가 있었습니다.
만약에 이런 수치형 변수를 outcome 값에 따라서 우리가 예측하고자 하는 값에 따라서 구분을 해보고, 특정 값에 따라서 outcome 값이 구분이 된다라고 하면 연속된 수치 변수를 카테고리 범주형 값으로 만들어서 표현을 해볼 수도 있을 것 같습니다.