[삼위일체(3조)] 프로젝트로 배우는 데이터 사이언스_3주차
3.1.2 범주형 변수를 수치형 변수로 변환하기 - 원핫인코딩
학습 목표
- 범주형 변수를 수치형 변수로 변환하는 기법을 이해합니다.
핵심 키워드
- 원핫인코딩 (one-hot-encoding)
필요한 라이브러리와 데이터셋 로드는 앞에서 설명했으므로 생략하겠습니다.
나이를 기준으로 '25세 미만', '25세부터 60세', '60세 초과'의 3개의 카테고리를 만들어보겠습니다.

pandas 모듈에서는 조건을 2개 이상 다룰 때 and를 쓰면 동작을 하지 않으므로 and 대신 &를 써줍니다.
pandas에서 여러 개의 column을 볼 때는 꼭 리스트 형태로 묶어줘야 합니다.
세 카테고리를 포함한 데이터프레임을 head()를 사용하여 미리보기합니다.
조건에 부합하면 True, 부합하지 않으면 False로 나타납니다.
결과:

학습, 예측 데이터셋 나누기

학습, 예측에 사용 컬럼

Age를 low, middle, high 세 범주로 나눴으므로 Age 컬럼은 삭제해줍니다.
정답값이자 예측해야 될 값

트리 알고리즘 분석하기
의사결정나무를 시각화합니다.

결과:

각 피처의 중요도를 추출합니다.

sns.barplot을 사용해서 피처의 중요도를 시각화합니다.

Glucose가 피처 중에서 가장 중요한 역할을 합니다. Age_low와 Age_high는 모수가 매우 적어 bar로 표현되지 않습니다. Pregnancies_high도 조금의 영향을 주고 있습니다.
정확도(Accuracy) 측정하기
실제값에서 예측값을 뺀 값, 즉 틀린 개수를 구합니다.

결과값은 49로 Pregancies를 범주화했을 때는 성능이 올라간 반면, Age를 범주화했을 때는 성능이 내려갔습니다.
이번에는 정확도를 구합니다.

정확도가 74에서 68로 내려갔습니다.
모델을 학습하고, 예측하니 성능이 오히려 더 나빠졌습니다.
이를 통해 좋은 기법을 쓴다고 해서 더 나은 성능이 나오는 것은 아님을 알 수 있습니다. 다양한 방법을 시도해봐야 합니다.
3.1.4 결측치 중앙값으로 대체하기
학습 목표
- 결측치를 중앙값으로 일괄 채우는 방법을 알아봅니다.
핵심 키워드
-isnull(), sum()
3.1.3 을 통해 결측치를 평균값으로 대체했을 때 성능이 꽤 올라간 것을 확인하였습니다.
이번에는 결측치를 중앙값으로 대체하였을 때 성능 변화를 살펴볼 것입니다.
우선 이전과 동일하게 insulin 값을 결측치로 만들어준 후, 결측치 비율을 확인합니다.


그룹화하기를 통해 평균값과 중앙값을 다시 구해봅니다.
이번에는 결측치를 채울 때 중앙값인 102.5로 채워보도록 하겠습니다.

이번에는 결측치를 채울 때 중앙값인 102.5와 169.5 로 채워보도록 하겠습니다.

이전과 동일하게 학습, 예측 데이터셋을 나누어주고 학습에 사용할 컬럼명를 가져옵니다.
여기서부터 학습, 예측 데이터셋을 실행한 후 예측하는 과정까지 이전(결측치->평균값 대입하기)과 동일합니다.
정확도가 얼마나 향상 되었는지 측정해보도록 하겠습니다.


중앙값으로 대체하니 정확도가 기존 85%에서 89%로 향상된 것을 확인할 수 있습니다.
결측치를 중앙값으로 대체하는 것 이외에도 결측치 자체를 지워버리는 방법도 있었습니다.
그러나, 이 데이터셋에서는 데이터의 개수도 굉장히 많은 편이었으며, 인슐린 데이터의 거의 절반이 결측치로 되어있어 제거를 해줄 수 있는 상황이 아니므로 결측치를 특정값(평균값, 중앙값)으로 대체하는 방식으로 진행하였습니다.
그 결과, 성능이 89% 정도의 꽤 준수한 수준으로 나타난 것을 확인할 수 있었습니다.
3.1.5 수치형 변수를 정규분포 형태로 만들기
학습 목표
- log 변환을 통해 전처리하는 방법을 이해합니다.
핵심 키워드
- 왜도
- 첨도
- 로그 변환
시각화를 할 때 아래와 같이 수치가 한쪽으로 편향되어있으면 제대로 학습하기에 어려운 경우가 생깁니다.
그리하여, 결측치를 사용하여 한쪽으로 치우친 데이터들을 정규 분포처럼 변환을 해주기도 합니다.
정규분포를 이룰 때 머신러닝이나 딥러닝 알고리즘은 좀 더 좋은 성능을 내기 때문에 정규 분포 형태를 만들기 위한 과정을 실행합니다.

결측치 전처리 이전의 인슐린 데이터의 분포를 그려보니 0쪽으로 치우친 모습을 볼 수 있습니다.

인슐린값만 보기 위해, 0보다 큰 값만을 활용해서 다시 그려보아도 한쪽으로 치우쳐져 있으며 뾰족함을 확인할 수 있습니다.
-왜도: 치우침의 정도
-첨도: 뾰족함의 정도

왜도를 낮추기 위한 전처리로, 인슐린값에 log 를 씌워보니 정규 분포 형태가 되었습니다.

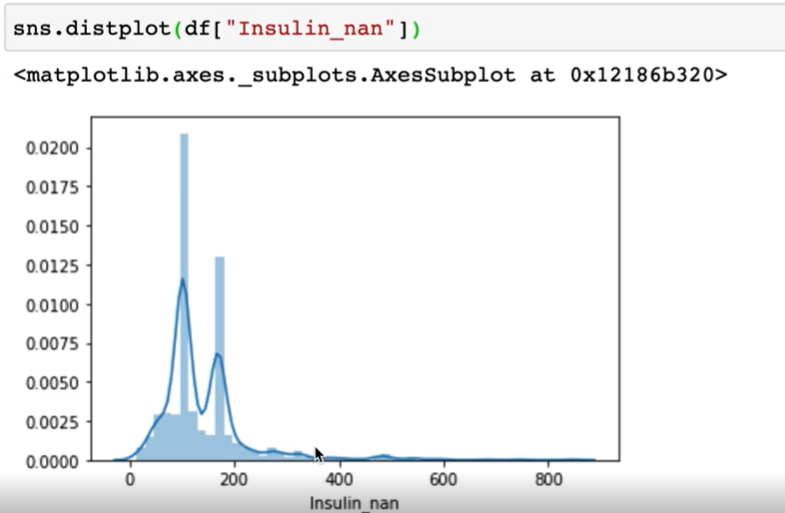
Insulin_nan 을 시각화해보니, 결측치를 중앙값으로 채워주었기 때문에 두 부분에 뾰족한 첨도가 나타나는 것을 볼 수 있습니다. 그리고 여전히 왼쪽에 치우쳐져 있습니다.
+1 을 해준 이유는 마이너스 무한대로 값이 확장되는 경우가 빈번히 발생하여, 이를 방지하기 위함입니다.
이렇게 하고 다시 그래프를 그렸더니 두개의 뾰족한 값을 가진 그래프가 됩니다.

이제 이것들이 학습에 도움이 되는지 점검해보도록 하겠습니다.
피처의 중요도를 시각화해보니 여전히 인슐린값이 중요한 역할을 하고 있네요.
정확도도 모두 동일하게 나왔습니다.



보통은 로그처리를 하게 되면 좀 더 좋은 성능을 내기도 하는데, 이 데이터에서는 큰 차이가 없네요. (ㅠㅠ)
하지만 '로그처리' 라는 방법 자체는 자주 사용되는 기법이니 잘 기억해두어야 합니다.