[불4조 - 코린이집] 서울 종합병원 분포 확인하기

작성자: 김승혁, 이예주, 임은진
서울 종합병원 분포 확인하기
csv 파일 형태의 데이터에서 제공된 위도, 경도 값을 이용하여 서울 내 종합병원의 분포를 시각화

이용한 데이터: 국가중점데이터인 <상권정보 상가(상권)정보_의료기관_201909>
https://www.data.go.kr/dataset/15012005/fileData.do
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
분석준비 -> 데이터 미리보기 -> 전처리(결측치제거) -> 시각화(scatterplot, folium)
1. 분석준비
라이브러리
본 데이터 분석에 필요한 라이브러리는 총 3개
pandas(데이터 구조화, 표형식), numpy(수치 계산), seaborn(데이터 시각화)
|
import pandas as pd
import numpy as np
import seaborn as sns
|
폰트설치
데이터를 한국어로 보기 위해 한글 폰트를 설치해야 한다. 설치를 안 하면 글자가 네모로 나타난다.
| 한글 폰트 설정 | |
| 공통 |
from matplotlib import pyplot as plt
|
| windows |
plt.rc('font', family='NanumBarunGothic')
|
| mac |
plt.rc('font', family='AppleGothic')
|
| 공통 |
plt.rc('axes', unicode_minus=False)
|
그래도 글꼴 설치가 안된다면 밑에 코드를 실행(chat gpt한테 물어봐도 됨)
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('retina')파일 업로드
구글 드라이브에 마운트하여 데이터를 코랩으로 불러오고 데이터를 df 라는 변수명에 저장한다.
*파일 경로 명을 적을 때 코랩의 <경로복사 기능>을 이용하면 편리하다.
from google.colab import drive
drive.mount('/content/drive')
df = pd.read_csv('/content/drive/MyDrive/data/소상공인시장진흥공단_상가업소정보_의료기관_201909.csv',low_memory= False, encoding="cp949")
2.데이터 확인하기
데이터를 전처리 하기 전과 후에 데이터(프레임)를 확인 하는 것이 매우 중요하다.
df
데이터 미리보기 옵션
데이터 요약하기

결측치 보기

특정 칼럼만 불러오기
| df.["특정 칼럼명"] | + | .mean() |
| .median() | ||
| .max() | ||
| .min() | ||
| .count() |
+) 특정 칼럼 삭제하기
drop_columns = df_null_count_top[" 불러오고 싶은 칼럼명"].tolist()
#삭제하고 싶은 칼럼 모아서 drop_columns에 저장
df = df.drop(drop_columns, axis = ?? )하면 삭제됨
#행 기준으로 삭제-> axis=0/ 열 기준으로 삭제-> axis=1
기초통계값 확인하기 (describe)
- 결측치는 빼고 보여준다.
- df.describe(include = 'number') == df.describe() 는 같은 표현이다.
-df.describe(include = 'object')

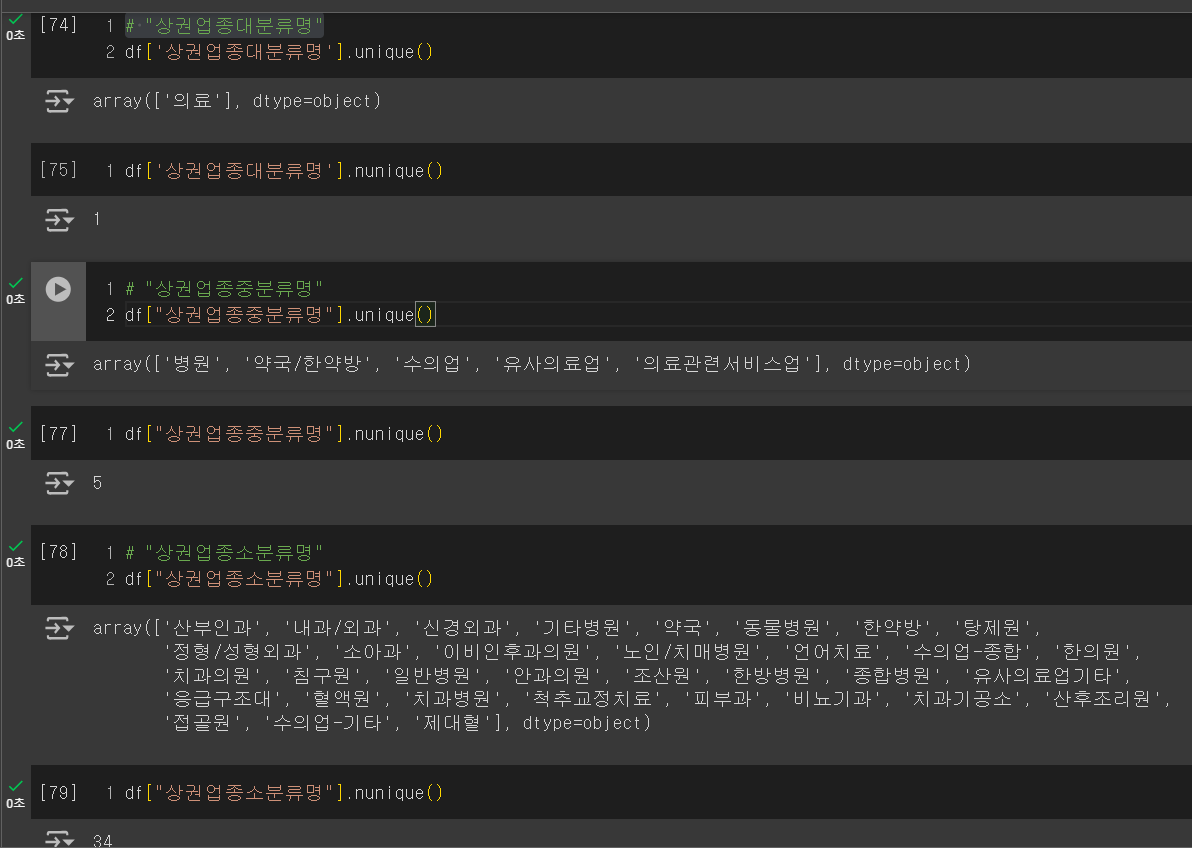
중복 제거한 값 보기 (unique)
- unique() : 종류와 타입을 모두 출력
- nunique() : 종류의 개수만 출력
- * 두 가지 모두 숫자에서만 나오는 특징 값이다.
df에 실행한 결과는 아래와 같다. 이를 통해 데이터의 index와 column을 쉽게 파악할 수 있다.
그룹화된 요약값 확인하기 (value_counts)
value_counts 를 사용하면 카테고리 형태의 데이터 갯수를 세어볼 수 있으며,
* normalize=True 옵션을 사용하면 비율을 구할 수 있다.

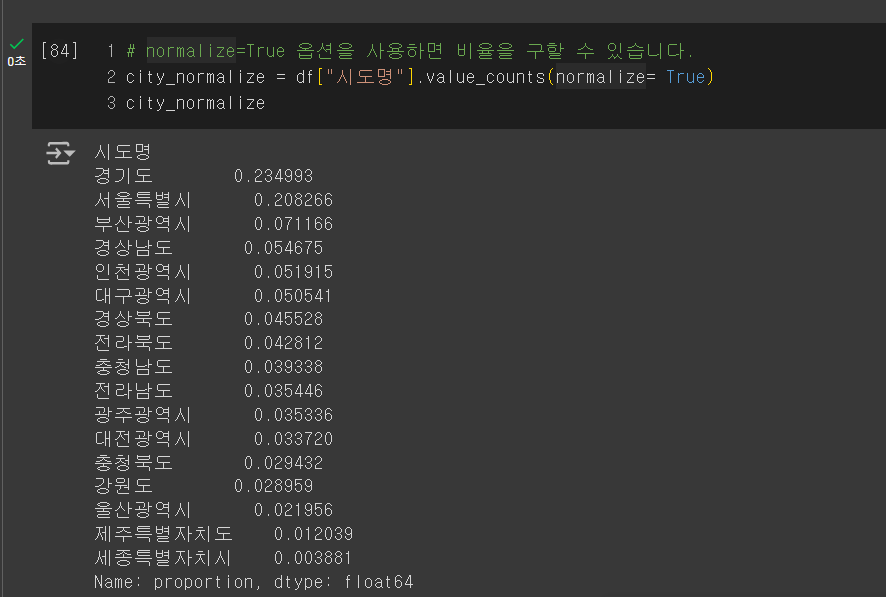
+ 참고 ) value_counts를 통해 얻어낸 시리즈를 시각화해서 분석할 수도 있다.
[plot기능을 이용한 시각화]
*Pandas 라이브러리에서는 plot기능을 내장하고 있어, 막대그래프, 파이차트 등 다양한 시각화를 할 수 있다.
* - pie 차트의 경우, city 와 city_normalize의 그래프 모두 똑같이 나온다.
(pie 차트가 나타내는 것이 비율이기 때문에 발생하는 것으로, 다른 그래프에서는 다르게 나타난다.)
* pie 차트를 통해서는 각 데이터 간의 차이를 파악하기가 쉽지 않기 때문에 바 그래프를 이용하는 것이 좋다.
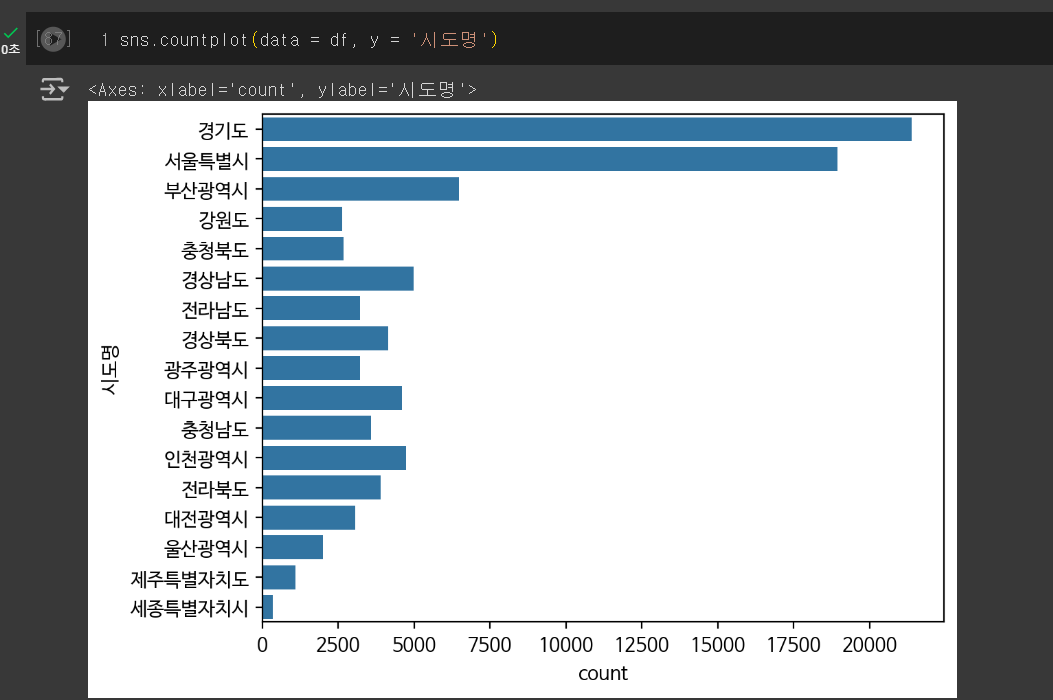
아래는 value_counts를 이용해서 서울 구별 종합 병원분포를 시각화한 것이다.


[seaborn라이브러리를 이용한 시각화]
- seaborn 라이브러리에서는 파이차트를 만드는 함수를 지원하지 않는다.
- 장점: metplot 과의 차이점은 metplot은 미리 저장된 데이터 프레임을 그래프로 나타낸다면,
seaborn 은 데이터가 선행되지 않아도 되며, seaborn은 고급 통계기능을 그래프 내에서 제공한다.
- 단점: 데이터의 크기가 커질수록 실행 속도가 느려진다.
3. 전처리 (결측치제거 & 인덱싱)
(1) 결측치 개수 확인하기
#True ==1, False ==0 임을 이용해서 sum 함수로 결측치의 개수를 측정함
null_count = df.isnull().sum()
null_count
(2) 결측치 수를 데이터 프레임 형태로 변환하기
- reset_index(): 기존에 설정되어 있는 행 인덱스를 제거하고, 그 인덱스를 데이터의 열로 추가하는 방식
#데이터 프레임으로 변환
df_null_count = null_count.reset_index()
df_null_count
#컬럼명 변경
df_null_count.columns =['컬럼명', "결측치수"]
df_null_count
(3) 제거할 데이터의 컬럼명 확인하기
- df_null_count 데이터프레임에 있는 결측치수 컬럼을 sort_values 를 통해 정렬해서 결측치가 많은 순으로 상위 10개를 의 컬럼명가져와서 drop_columns 라는 변수에 담습니다.
#결측치수 상위 10개 새로운 변수에 저장
df_null_count_top = df_null_count.sort_values(by='결측치수',ascending=False).head(10)
#컬럼명을 가져와 리스트에 저장
drop_columns = df_null_count_top["컬럼명"].tolist()
drop_columns
(4) 결측치 데이터 제거
print(df.shape)
df = df.drop(drop_columns, axis =1) #할당 필수// 안하면 적용이 안된다.
print(df.shape)(행개수,열개수)
결측치 제거전: (91335, 39)
결측치 제거후: (91335, 29)
(5) 데이터 확인
전처리 과정에서는 전처리가 잘 진행되었는지 확인하기 위해 데이터 정보를 수시로 확인하는 것이 좋다.
컬럼수가 달라졌음을 확인할 수 있다.
df.info()

(6) 데이터 색인하기
- 색인 = 특정 데이터만 불러오기 = 인덱싱(indexing)
- df[ coulmn 이나 index명] + 조건식 => bool 형태로 표현됨
- df[ df[ coulmn 이나 index명] + 조건식 ] => 데이터 프레임 형태로 표현됨
- 색인 조건이 여러개인 경우 괄호와 &(and)를 이용해서 표현 가능하다.
색인 예시
# "시군구명" 으로 그룹화 해서 구별로 서울 종합병원의 수 확인하기
df_seoul_hospital["시군구명"].value_counts()
텍스트 데이터 색인하기
* copy()를 이용한 이유: 원본 데이터가 변형 방지하기 위해서
df_seoul_hospital = df[ (df['상권업종소분류명']=='종합병원') & (df['시도명']=='서울특별시')].copy()
df_seoul_hospital
색인하기 전에 상호명중에 종합병원이 아닌 데이터를 찾아보기
df_seoul_hospital.loc[~df_seoul_hospital["상호명"].str.contains("종합병원"),"상호명"].unique().str.contains(" 조건") => 조건에 해당하는 문자열을 포함하는 데이터만 가져온다 / T,F를 리턴한다.
~ => '아니다'를 의미한다. (조건 연산자의 not과 같은 의미)

종합병원이 아닌 데이터의 인덱스를 리스트에 저장하기
상호명에 꽃배달, 의료기, 장례식장, 상담소, 어린이집이 들어가는 데이터 인덱스 찾기
drop_row = df_seoul_hospital[df_seoul_hospital["상호명"].str.contains("꽃배달|의료기|장례식장|상담소|어린이집")].index
drop_row = drop_row.tolist()의원으로 끝나는 데이터의 인덱스 찾기
drop_row2 = df_seoul_hospital[df_seoul_hospital["상호명"].str.endswith("의원")].index
drop_row2 = drop_row2.tolist()두 리스트 합치기
drop_row = drop_row + drop_row2
len(drop_row)
#24개의 행리스트를 이용해서 데이터 제거하기 / shape를 이용해 행, 열 확인하기
print(df_seoul_hospital.shape)
df_seoul_hospital = df_seoul_hospital.drop(drop_row, axis = 0 )
#행을 기준으로 drop 하기 때문에 axis = 0으로 옵션 설정한다.
print(df_seoul_hospital.shape)(91, 29)
(67, 29)
확인하기
df_seoul_hospital["상호명"].unique()
4. 시각화 하기
특정 지역만 보기
df_seoul = df[df["시도명"] == "서울특별시"].copy()
df_seoul.shape
#서울시 데이터 샘플링scatter plot
scatter plot은 수치형 데이터가 어디 좌표에 위치하는지 출력할 때 주로 이용한다
df_seoul ["시도명"].value_counts().plot.bar(figsize=(10, 4), rot=30)
# figsize: 사이즈, rot: 회전각도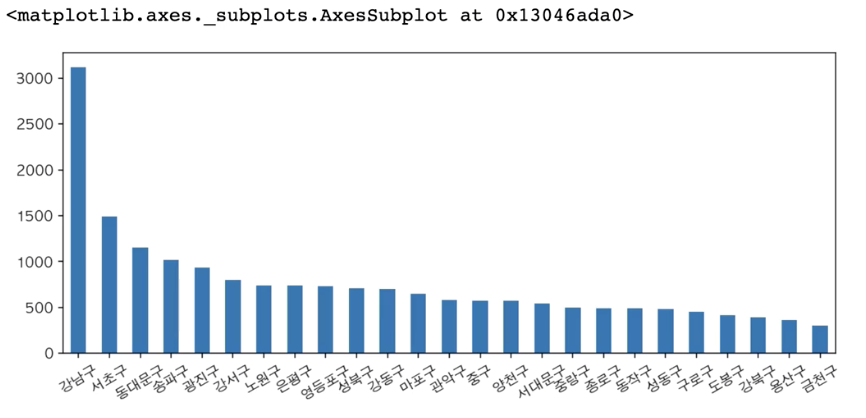
plt.figure(figsize=(9, 8))
sns.scatterplot(data=df_seoul, x="경도", y="위도", hue="시군구명")
#hue를 활용하여 구별로 다른 색상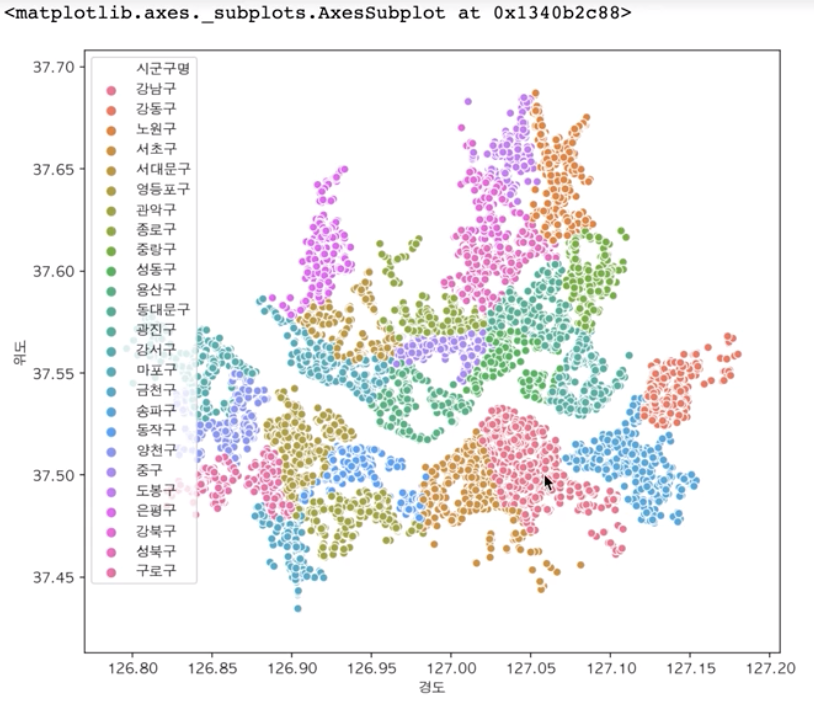
Folium 시각화
Anaconda prompt에 conda install -c conda-forge folium을 입력하여 설치한다
import folium #folium 불러오기folium.Map()
map = folium.Map(location=[df1["위도"].mean(),df2["경도"].mean()], zoom_start=1)folium.Map은 세계지도가 나오지만 location과 zoom_start를 찍으면 위치를 설정할 수 있다.
서울 종합병원 분포 folium으로 시각화하기
지도 기본 설정
# geo_df 에 df_seoul_hospital 을 copy() 로 복사해서 할당
# copy() 사용하는 것은 원본 데이터의 변형을 막기 위해서이다.
geo_df = df_seoul_hospital.copy()
# 지도의 중심을 지정하기 위해 위도와 경도의 평균을 구합니다.
df_seoul_hospital["위도"].mean()
df_seoul_hospital["경도"].mean() #mean = 평균지도 옵션 설정
map = folium.Map(location = [df_seoul_hospital["위도"].mean(),df_seoul_hospital["경도"].mean()],
zoom_start = 12)
for n in df_seoul_hospital.index:
name = df_seoul_hospital.loc[n,'상호명']
address = df_seoul_hospital.loc[n,'도로명주소']
popup = f"{name}-{address}"
# 지도의 마커를 클릭하면 도로명 주소와 상호명이 팝업으로 뜨도록 설정
location = [df_seoul_hospital.loc[n,'위도'],df_seoul_hospital.loc[n,'경도']]
#df_seoul_hospital 데이터 프레임의 인덱스가 n이고, 열이 '위도','경도'이니 데이터들을 리스트에 담기
folium.Marker(location= location, popup=popup).add_to(map)
map
마커로 표시된 위치를 통해 서울 종합병원이 어느 지역에 밀집 해있는지, 주변시설로 무엇이 있는지 등
데이터 프레임 형태로는 파악하기 어려웠던 위치적인 특징을 파악하기 용이해졌다.
서울특별시 소아과, 어린이집 분포 비교 분석
1. 변형 목적/방법 설명
- 변형목적 : 데이터 시각화를 통해 지식 얻기
단순히 기존 데이터로 다른 형식의 그래프를 그리는 것이 아닌, 강의에서 배운 코드를 활용하여
다른 데이터의 시각화를 통해 새로운 지식을 도출해내고 싶어 진행하게 되었다. - 변형방법:
서울 내 어린이집과 소아과의 위치분포에 대한 가설을 세우고, 데이터 프레임과 지도형태의 시각화를 통해서 가설 검증을 진행하였다. - 가설: 어린이집이 많은 곳에 소아과가 많이 분포하고 있을 것이다.
(즉, 어린이집과 소아과의 분포가 비슷하다.)
2. 소아과와 어린이집 분포 분석
1)소아과 분포
(1)데이터 색인
소아과는 앞 부분에서 전처리된 데이터를 기반으로 분석을 시작함.
#상권업종소분류명에서 소아과/ 시도명에서 서울특별시 데이터만 불러옴
#소아과와 서울특별시 교집합을 df_seoul_ped 변수에 할당시킴
df_seoul_ped = df[(df['상권업종소분류명']=='소아과') & (df["시도명"]=="서울특별시")]
print(df_seoul_ped.shape)(2)시각화
#시군구별 소아과 분포 확인
plt.figure(figsize=(9, 6))
df_seoul_ped["시군구명"].value_counts().plot.barh(figsize= (8,7), color='navy')
#위도, 경도를 기반으로 분포 시각화
df_seoul_ped[["경도",'위도','시군구명']].plot.scatter(x='경도',y= '위도', figsize = (8,7), grid = True, color='navy')
#hue='시군구명'을 써서 시군구별로 분포 나타냄
plt.figure(figsize=(9, 8))
sns.scatterplot(data = df_seoul_ped, x= "경도",y= '위도',hue = "시군구명")
#지도상에 소아과 위치 확인하기
map = folium.Map(location = [df_seoul_ped["위도"].mean(),df_seoul_ped["경도"].mean()],
zoom_start = 12)
for n in df_seoul_ped.index:
name = df_seoul_ped.loc[n,'상호명']
address = df_seoul_ped.loc[n,'도로명주소']
popup = f"{name}-{address}"
location = [df_seoul_ped.loc[n,'위도'],df_seoul_ped.loc[n,'경도']]
folium.Marker(location= location, popup=popup).add_to(map)
map
2) 어린이집 분포 확인하기
(1) 데이터 로드
#코랩 구글 마운트
from google.colab import drive
drive.mount('/content/drive')
#서울시 어린이집 데이터를 로드
df2 = pd.read_csv('/content/서울시 어린이집 정보(표준 데이터).csv',low_memory= False, encoding="cp949")
df2.shape
어린이집 데이터: https://www.data.go.kr/data/15088924/fileData.do
서울특별시_어린이집 정보_20210915
어린이집정보공개포털에서 제공하는 어린이집 현황 정보입니다. <br/>※ 본 데이터의 저작권은 어린이집정보공개포털(http://info.childcare.go.kr/)에 있음을 알려드립니다.
www.data.go.kr
(2) 결측치 제거 (전처리)
df_filtered_data1 = df2[df2['운영현황'] == "정상"]
df_filtered_data1어린이집 데이터에서 운영현황이 정상인 데이터만 불러옴 (데이터 색인)
df2_null_count[df2_null_count['컬럼명']=='시설 경도(좌표값)']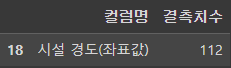
df2_null_count[df2_null_count['컬럼명']=='시설 위도(좌표값)']
# subset=['특정컬럼']: dropna() 메서드의 매개변수 중 하나로, 결측치를 삭제할 때 고려할 열을 지정
# 여기서는 "특정컬럼"에 해당하는 열을 지정함. 이것은 결측치가 있는 행을 찾기 위한 기준 열이 된다.
df_filtered_data2 = df_filtered_data1.dropna(subset=['시설 위도(좌표값)'])
(3) 데이터 시각화
import matplotlib.pyplot as plt
#데이터 시각화 라이브러리* 그래프의 좌표축 범위를 조절하는 plt.xlim(), plt.ylim() 함수를 이용하기 위해 임포트했다.
그래프 그리기
df_filtered_data2[['시설 위도(좌표값)', '시설 경도(좌표값)','시군구명']].plot.scatter(y='시설 위도(좌표값)',x='시설 경도(좌표값)',figsize = (12,10),grid = True, color='green')
plt.title("<서울 내 어린이집 분포>")
plt.ylim(37.4, 37.7)
plt.xlim(126.7, 127.3)
plt.show()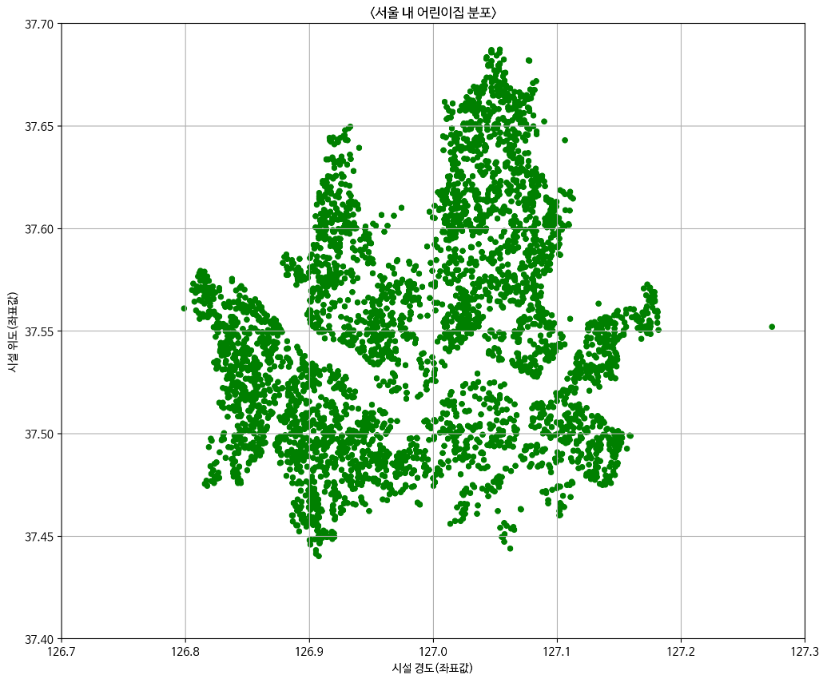
hue를 사용하여 구별로 색상을 달리함
plt.figure(figsize=(12, 10))
sns.scatterplot(data = df_filtered_data2, y= "시설 위도(좌표값)",x= '시설 경도(좌표값)',hue = "시군구명")
plt.title("<서울 내 어린이집 분포>")
plt.ylim(37.4, 37.7)
plt.xlim(126.7, 127.3)
plt.show()
seoul_daycare.plot.barh(color = 'green')
#막대그래프를 통해 구별로 나타냄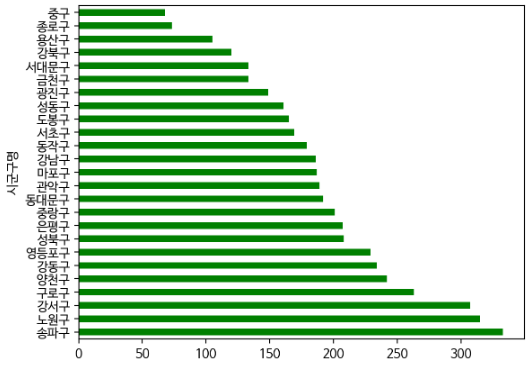
seoul_daycare.describe()
#데이터 요약
(4) 지도위에 어린이집 나타내기
import folium
# 서울 데이터프레임의 중심 좌표를 설정
map = folium.Map(location=[df_filtered_data2["시설 위도(좌표값)"].mean(), df_filtered_data2["시설 경도(좌표값)"].mean()], zoom_start=12)
# 업로드한 이미지 파일 경로
icon_image = '/content/KakaoTalk_20240601_160648776.png'
for n in df_filtered_data2.index:
name = df_filtered_data2.loc[n, '어린이집명']
address = df_filtered_data2.loc[n, '상세주소']
popup = f"{name} - {address}"
location = [df_filtered_data2.loc[n, '시설 위도(좌표값)'], df_filtered_data2.loc[n, '시설 경도(좌표값)']]
# CustomIcon 객체를 생성하고 크기를 지정
icon = folium.features.CustomIcon(icon_image=icon_image, icon_size=(50, 50))
# 지도에 마커 추가
folium.Marker(location=location, popup=popup, icon=icon).add_to(map)
map.save('map.html')
map
3. 해석
1)어린이집과 소아과의 전체적인 분포분석
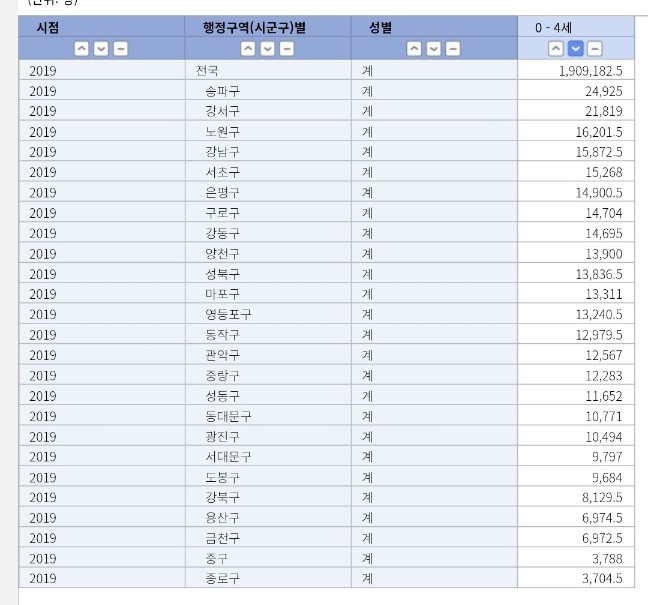
어린이집이 많은 지역은 송파구, 강서구, 노원구, 구로구, 양천구이다.
소아과가 많은 지역은 강남구, 강서구, 서초구, 송파구, 노원구이다.
송파구와 강서구, 노원구는 어린이집과 소아과 수가 비슷하지만
어린이집이 4, 5번째로 많은 구로구와 양천구는 소아과 수가 중간값에 머물렀다.
중위권에는 특히 동작구, 마포구만 비슷한 분포를 가지며 중위권에는 차이가 조금씩 난다.
하위권에 중구, 종로구, 용산구 강북구 등의 유사한 분포를 지닌다.
지역별 아동인구 수와 비교해도 비슷한 흐름으로 어린이집 수, 소아과 분포 수와 유사하다.
결론: 전체적으로 어린이집 분포 순서와 소아과 분포 순서가 정확히 일치하지 않다.
상위, 중위, 하위로 나누어 보았을 때는 비슷하게 위치해 있는 것을 알 수 있다.
따라서 소아과 분포와 어린이집 분포가 매우 유사하다.
2) 소아과, 어린이집의 밀집도가 높은 지역 위주로 분석했을 때

평균보다 수가 많은 지역을 어린이집과 소아과가 많은 지역이라고 하고,
어린이집과 소아과 두 분포가 모두 높은 지역들이 절방 이상 일치할 때 가설을 참이라고 결정하기로 했다.
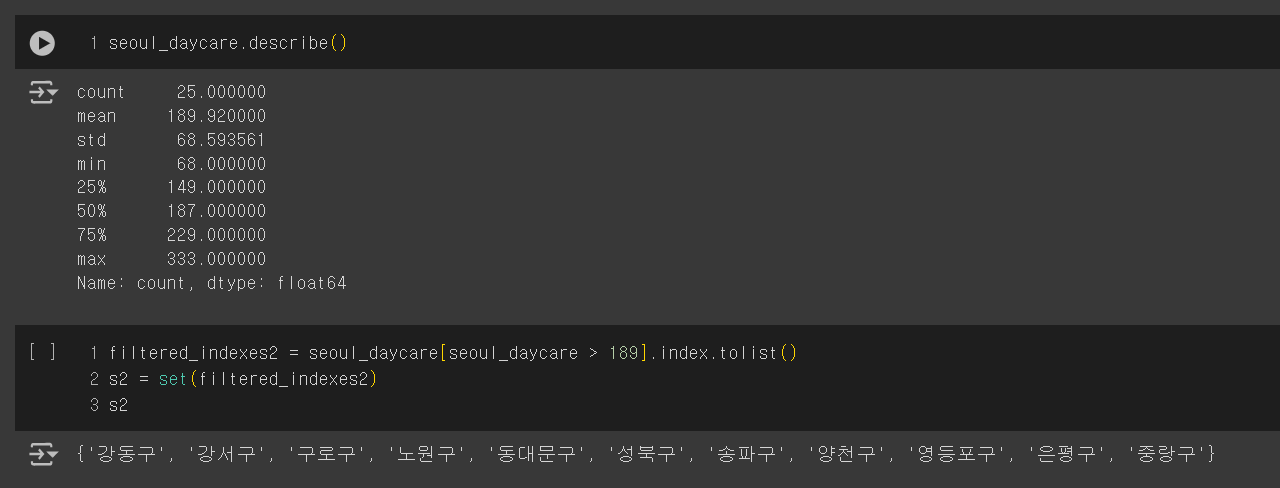
서울 구별 어린이집 개수의 평균은 189.92개였고, 평균보다 어린이집이 많이 분포한 지역은
'강남구', '강동구', '강서구','노원구', '마포구', '서초구', '성동구', '성북구', '송파구', '양천구', '영등포구', '은평구'
(12개구)였다.
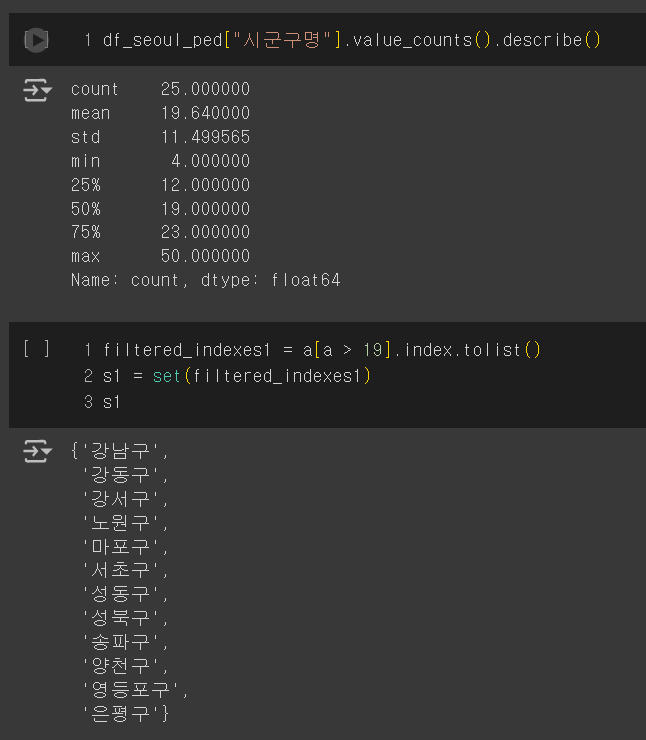
서울 구별 소아과 개수의 평균은 169.64개였고, 평균보다 소아과가 많이 분포한 지역은
'강동구', '강서구', '구로구', '노원구', '동대문구', '성북구', '송파구', '양천구', '영등포구', '은평구', '중랑구' (11개구)였다.
어린이집과 소아과 모두 평균보다 높은 분포를 가진 지역은
'강동구', '강서구', '노원구', '성북구', '송파구', '양천구', '영등포구', '은평구' (8개 구)로,
소아과, 어린이집의 분포도가 높은 지역의 과반을 차지하므로, 가설은 수용되었다.
4. 결론:
가설이 수용되었다.
소아과 분포와 어린이집 분포가 매우 유사하다. (O)
= 어린이집이 많은 곳에 소아과가 많이 분포하고 있을 것이다. (O)
5. 제언
- 아쉬운 점 / 한계점
- 소아과와 어린이집 분포를 직접 시각화하지 않아도 비슷하게 위치해 있다는 것을 어느정도 짐작할 수 있기에 완전히
새로운 지식을 창출해 내었고 인사이트를 얻었다고 말하기는 힘들다.
- 어린이집, 소아과의 두 scatterplot 그림을 겹치는 것, 지도위에 scatterplot을 시각화하는데에
어려움이 있어서 위치의 미세한 분포를 비교하지 못했다. - 프로젝트 느낀점
- 처음에는 지도 위에 병원을 표시하는 프로젝트가 굉장히 어려워 보여서 걱정했지만, 막상 해보니 어려웠던 것도
하나하나 해결되고 데이터를 분석함에 얻어가는 것이 많았던 것 같다.
- 데이터 프레임의 전처리부터 강의를 직접 따라해볼 수 있어서 좋았고, 변형하면서 강의에서는 배우지 않았던, 옵션이나 코드도 공부할 수 있어서 좋았다. 특히,스터디를 할 때 gpt를 이용해서 코드를 공부하는 방법이나 오류를 해결하는 방법도 연습할 수 있어서 나중에 도움이 될 것 같다.
- 앞으로 하고 싶은 것
- 다음번에는 특정 이슈에 관한 데이터를 활용하여서 사회현상을 읽고 싶다.
- 이번활동에서 배운 막대그래프나 scatterplot 외에도 다양한 그래프로 데이터를 나타내보고 싶다.
- 나중에는 이렇게 정해진 주제로 데이터 분석을 하는 것이 아닌 자신이 관심이 있었던 주제로 한 번 데이터 분석을 해봤으면 하는 아쉬움이 있다