작성자 : 도소연
Import
파이썬의 라이브러리나 패키지를 가져올 수 있다.
Boolean
True나 False는 0과 1로도 표현할 수 있으나 명시적으로 표현하기 위해 True와 False를 사용한다.
- True는 1과 같다.
- False는 0과 같다.
- 파이썬에서는 같음을 비교할 때 == 연산을 사용한다.
- True는 문자 1과 다르다.(역도 성립)
- False는 문자 0과 다르다.(역도 성립)
- 파이썬에서는 같지않음을 비교할 때 != 연산을 사용한다.
- and는 모든 값이 True일 때만 True가 된다.
- and는 조건 중 하나라도 False라면 False가 된다.
- or는 하나만 True라도 True가 된다.
Number and String
- 숫자 1과 문자 “1”은 다르다.
- 데이터 타입을 표현할 때 type을 통해 데이터를 출력한다.
Strings and Lists
| 연산자 | 기능 |
| == | 비교연산 |
| = | 할당연산 |
1) Strings
- 변수명.lower( ) → 소문자로 변환
- 변수명.upper( ) → 대문자로 변환
2) Lists
- 변수명.append( ) → 리스트 마지막에 원소 추가
- 변수명[인덱스번호] → 인덱스에 해당하는 요소 불러오기
Control Flow
반복문, 조건문
- for i, val in enumerate(변수명) :
print( I, val ) - → 인덱스 번호와 원소를 같이 가져올 수 있다.
문자열
- 변수명.strip( ) → 앞뒤 공백을 제거한다.
- len(변수명) → 문자열의 길이
- 변수명.split( ) → 공백으로 문자열 분리하여 리스트 생성
- len(변수명) → 리스트의 길이
- 변수명[ : ] → 슬라이싱
- 변수명.startswith( “ 원소값 “ ) → 특정문자가 포함되는지 여부 확인 (True/False)
- “원소값” in 변수명 → 특정 문자열을 포함하고 있는지 여부 확인
리스트
- " ".join(리스트명) → 리스트를 공백 문자열로 연결
Pandas
수식으로 계산할 수 있고 시각화도 할 수 있는 데이터 분석도구.
엑셀로는 힘든 대용량의 데이터를 판다스는 분석할 수 있다.
Dataframe
이차원 데이터로 표현된다.
df = pd.DataFrame({“a” : [4,5,6], “b” : [7,8,9]} , index = [1,2,3])
df| a | b | |
| 1 | 4 | 7 |
| 2 | 5 | 8 |
| 3 | 6 | 9 |
Series
일차원 데이터로 표현된다.
df[“a”]| 1 | 4 |
| 2 | 5 |
| 3 | 6 |
Subset
df[“a”] > 4→ 4보다 큰 값만 일차원 데이터 형태의 boolean으로 표시된다.
| 1 | False |
| 2 | True |
| 3 | True |
df[df[“a”] > 4 ]→ 4보다 큰 값만 불러와 이차원데이터로 표현한다.
- 대괄호 한 번 : Series 형태
- 대괄호 두 번 : Dataframe 형태
- 두 개 이상의 column을 가져올 때는 dataframe 형태로 가져온다.
Summarize Data
df[“a”].value_counts( )→ df에서 a열의 value값 갯수
len(df)→ df의 길이
Reshaping
df[“a”].sort_values( )→ 특정 column을 일차원 데이터 형태로 오름차순 정리
df.sort_values(“a”)→ 전체 데이터 값을 특정 column값 기준으로 정렬
df.sort_values(“a”, ascending=False)→ 전체 데이터 값을 특정 column값 기준으로 내림차순 정리)
df.drop([“c”], axis=1)→ 기본적으로 행을 기준(axis=0)으로 drop하게 되어있기 때문에 열을 drop하고 싶다면 axis=1을 써준다.
Group Data
df.groupby([“a”])[“b”].mean( )→ a라는 column으로 groupby해서 b라는 column값으로 평균값 구하기
df.groupby([“a”])[“b”].agg([“mean”, “sum”, “count”])
df.groupby([“a”])[“b”].describe( )
pd.pivot_table(df, index = “a”, values = “b”)
Plotting
df.plot( )→ 간단한 시각화
작성자: 임효신
📂 파이썬으로 시작하는 데이터 사이언스
2.1 데이터 분석을 위한 파이썬 속성 코스
1. import, Zen of Python
import this→
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
2. boolean
print(False == 0)
print(True == "1")
print(True != "1")
print(True and True)
print(1 and 1)
print(True or False)→
True
False
True
True
1
True
3. strings
strings = "Today I learned"
print(strings)
print(strings.lower())
print(strings.upper())→
Today I learned
today i learned
TODAY I LEARNED
4. lists
user_input = []
print(user_input)
user_input.append("python")
user_input.append("java")
user_input.append("c")
print(user_input)
print(user_input[0])
print(user_input[1])
print(user_input[-1])→
[]
['python', 'java', 'c']
python
java
c
5. 제어문
for i in user_input:
print(i)
for i in user_input:
if i == "python":
print("python")
else: print("기타")
for i in range(5):
print(i)
# 짝수일 때 "python", 홀수일 때 "java"
for i in range(1, 10):
if i % 2 == 0:
print("python")
else: print("java")
# enumerate -> 인덱스 번호와 원소를 함께 가져올 수 있다.
for i, val in enumerate(user_input):
print(i, val)
# 출력되는 번호의 시작점을 설정할 수 있다.
for i, val in enumerate(user_input, start = 1):
print(i, val)→
python
java
c
python
기타
기타
0
1
2
3
4
java
python
java
python
java
python
java
python
java
0 python
1 java
2 c
1 python
2 java
3 c
6. 문자열
address = "경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층"
print(address)
# 앞뒤 공백 제거
address = address.strip()
print(address)
print(len(address))
address_list = address.split()
print(address_list)
print(len(address_list))→
경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층
경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층
33
['경기도', '성남시', '분당구', '불정로', '6', 'NAVER', '그린팩토리', '16층']
8
7. 슬라이싱, startswith
# 슬라이싱
print(address[:2])
# startswith -> 특정 문자 포함 여부
print(address.startswith("경기"))
print("경기" in address)→
경기
True
True
8. 인덱싱, join
gu = address_list[2]
print(gu)
street = address_list[3]
print(street)
print(address_list[-1])
print("".join(address_list))
print(",".join(address_list))→
분당구
불정로
16층
경기도성남시분당구불정로6NAVER그린팩토리16층
경기도,성남시,분당구,불정로,6,NAVER,그린팩토리,16층
2.2 판다스 치트시트를 활용한 기초 익히기
Pandas: 수식으로 계산할 수 있고 시각화도 할 수 있는 데이터 분석도구
1. import pandas
import pandas as pdas pd는 간결하게 사용하기 위한 별칭
2. DataFlame
df = pd.DataFrame(
{"a":[4,5,6,4],
"b":[7,8,9,9],
"c":[10,11,12,10]},
index = [1,2,3,4])
df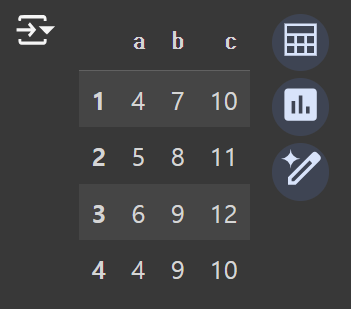
3. Series
df["a"]→
1 4
2 5
3 6
4 4
Name: a, dtype: int64
4. DataFrame 형태로 출력
df[["a"]]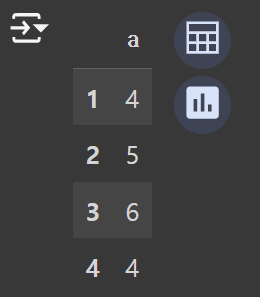
5. Subset (일부 값만 불러오기)
Rows 기준
df[df["a"] > 5]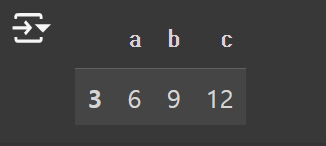
Columns 기준
* 두 개 이상의 값을 불러 올 때는 DataFrame 형태로 불러와야 한다.
df[["a","b"]]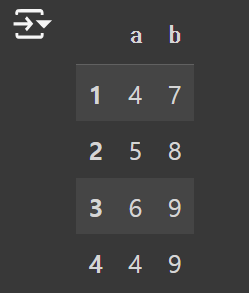
6. Summarize Data - 값의 빈도수 구하기
df["a"].value_counts()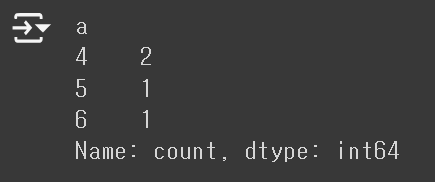
7. Reshaping - sort_values, drop
1) "a" column 기준으로 정렬하기
df["a"].sort_values()
2) DataFrame 전체에서 "a" 값을 기준으로 정렬하기
df.sort_values("a")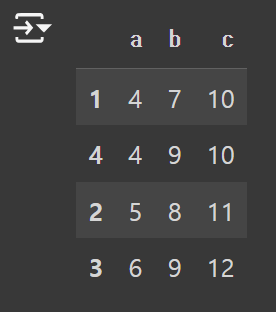
3) 역순 정렬하기
df.sort_values("a", ascending=False)
# ascending=False는 내림차순 정렬. 쓰지 않는다면 오름차순 정렬된다.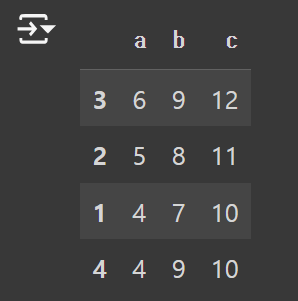
4) "c" column drop
df.drop(["c"], axis=1)
# axis=1은 열 방향으로 동작, axis=0은 행 방향으로 동작. 잘 맞추어 넣어야 한다.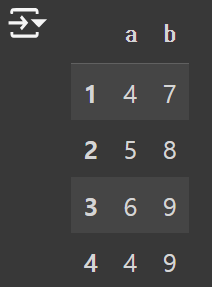
bonus) 4 Rows drop
df.drop([4], axis=0)
8. Group Data - Groupby, pivot_table
1) "a" column값을 Groupby하여 "b"의 column값 평균 구하기
해당 부분이 잘 이해가 되지 않았는데, "a" 칼럼에 4라는 값이 두 번 나오면 해당 행에 해당하는 "b" 칼럼 값을 합쳐서 계산하더라. "a" 칼럼 값 기준으로 "b" 칼럼 값을 모아준다고 생각하면 될 듯.
df.groupby(["a"])["b"].agg(["mean", "sum", "count"])
# 평균값 뿐만 아니라 합, 빈도수도 구할 수 있다.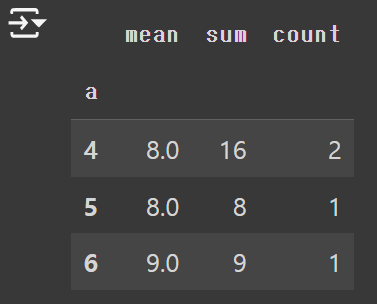
df.groupby(["a"])["b"].describe()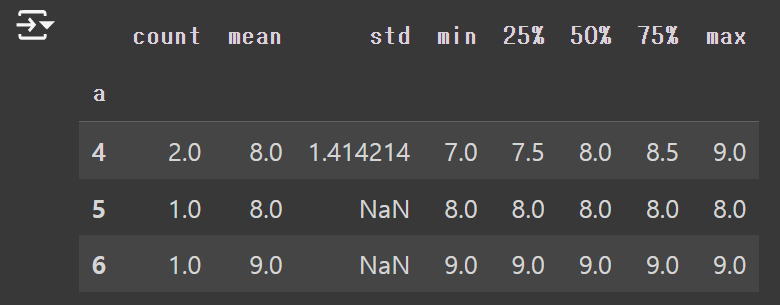
2) pivot_table로 평균값 구하기
pd.pivot_table(df, index="a")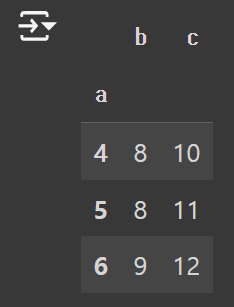
pd.pivot_table(df, index="a", values="b", aggfunc="sum")
9. 여러 가지 그래프
1) 꺾은선 그래프
df.plot()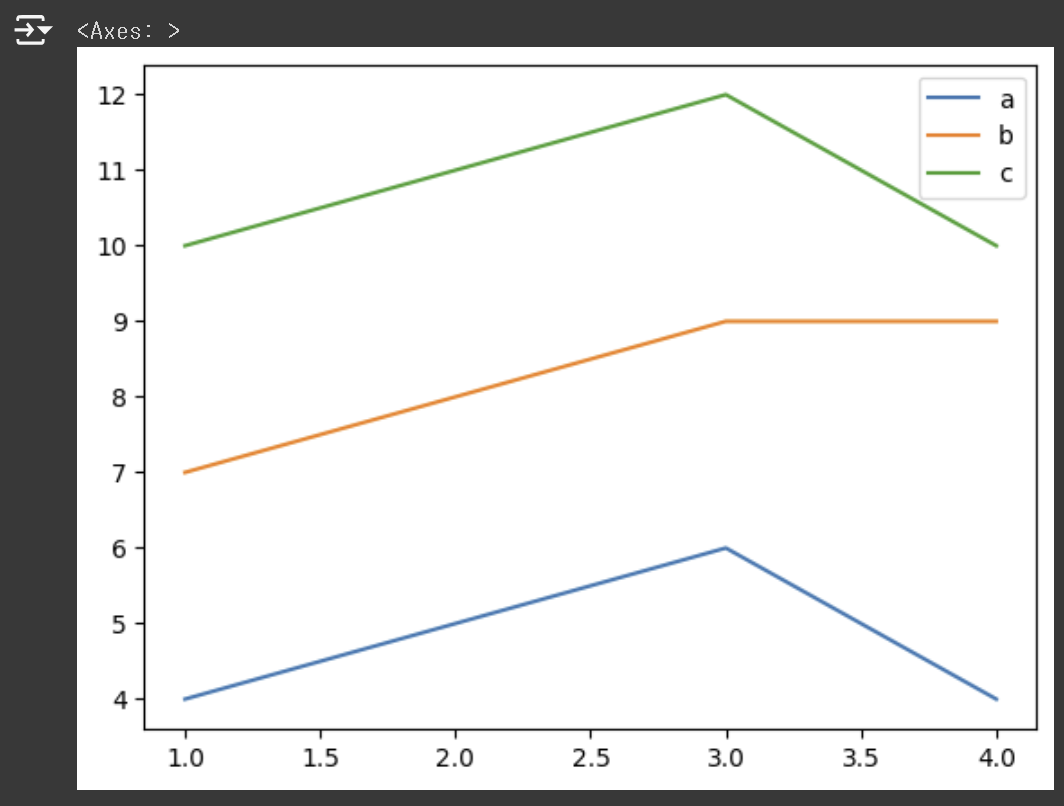
2) 막대그래프
df.plot.bar()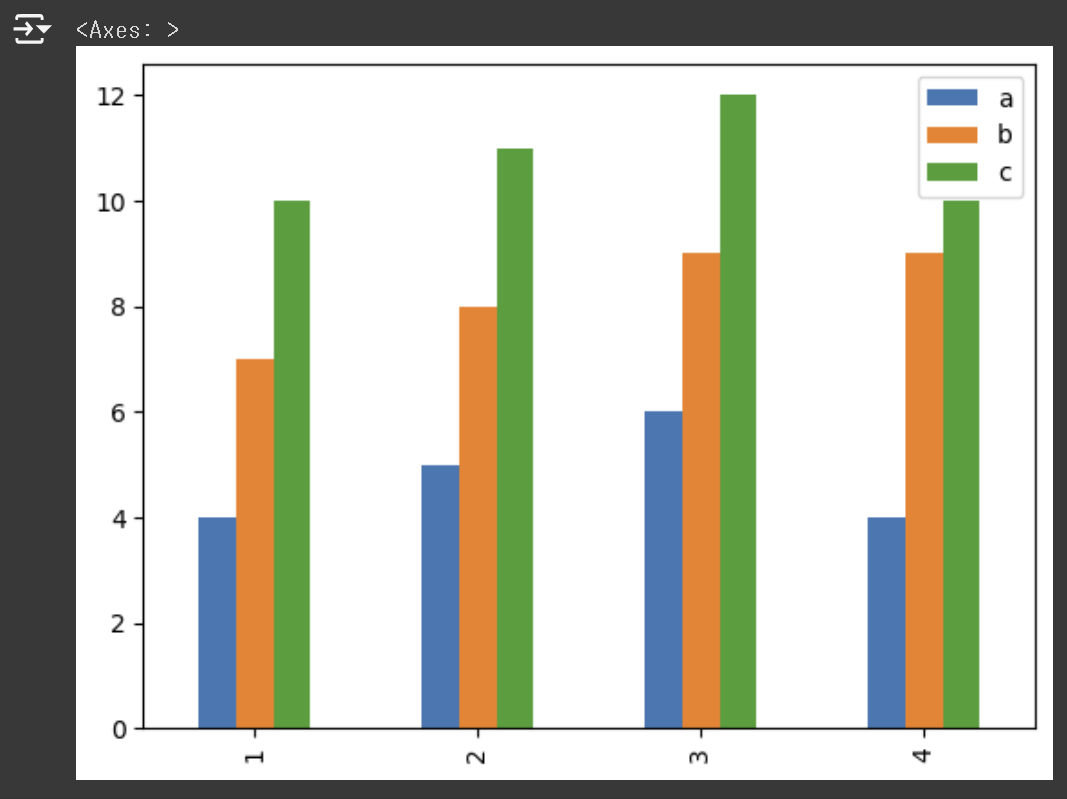
3) 밀도함수
df.plot.density()