작성자:김민혁
1. pandas 불러오기
import pandas as pd
2. Series
- Series는 일련의 데이터를 1차원 배열로 저장하며, 각 데이터 항목은 인덱스와 연결된다.
data = [10, 20, 30, 40]
series = pd.Series(data)
3. DataFrame
- DataFrame은 행과 열로 이루어진 2차원 데이터 구조로, 각 열은 서로 다른 타입의 데이터를 저장할 수 있다.
data = {'Name': ['Kim', 'Lee', 'Park', 'choi'], 'Age': [28, 22, 34, 42]}
df = pd.DataFrame(data)
4. sort
- 데이터를 정렬할 때 사용한다. 예를 들어, 'Age' 열에 따라 데이터를 오름차순으로 정렬할 수 있다.
df.sort_values(by='Age')
5. drop
- 필요하지 않은 열이나 행을 삭제할 때 사용한다.
df.drop('Age', axis=1)
6. groupby
- 동일한 값에 대한 통계 또는 요약을 계산할 때 사용한다. 예를 들어, 'City'별로 데이터를 그룹화하고 각 그룹의 평균 나이를 계산할 수 있다.
df.groupby('City').mean()
7. pivot table
- 데이터를 재구조화하여 요약 표를 만들 때 사용한다. 예를 들어, 행은 'City', 열은 'Name', 값은 'Age'인 피벗 테이블을 생성할 수 있다.
pd.pivot_table(df, values='Age', index='City', columns='Name')
8. plot
- 데이터를 시각화할 때 사용한다. 예를 들어, 'Age' 데이터를 바 차트로 표현할 수 있다.
df['Age'].plot(kind='bar')
이러한 기본적인 기능들을 활용하여 `pandas` 라이브러리를 통해 데이터를 다루고 분석할 수 있다.
작성자 : 정현석
1. 판다스 불러보기
| import pandas as pd |
일반적으로 as pd라는 별명으로 저장한다.
예를들어, pandas.DataFrame이 아닌 pd.DataFrame으로 간단하게 저장할 수 있다.
2. Data Frame
| df = pd.DataFrame( {"A": [4,8,16], "B": [3,9,27], "C": [10,11,12]}, index = [1,2,3]) df |
위 DataFrame에 대한 결과는 다음과 같다.
| A | B | C | |
| 1 | 4 | 3 | 10 |
| 2 | 8 | 9 | 11 |
| 3 | 16 | 27 | 12 |
이는 A,B,C라는 칼럼(행)을 가진 DataFrame이 생성된 것이다.
2. Series
df["A"]라는 행을 출력하게 되면 A행에 있는 4,8,16이라는 값이 출력되는데 이것을 Series 데이터라고 한다.
위 Series에 대한 결과는 다음과 같다.
| 1 4 2 5 3 6 Name: A, dtype: int64 |
Series는 일련의 데이터를 1차원의 형태로 저장하며, 각 데이터 항목은 [1,2,3]과 같은 인덱스와 연결된다.
여기서 대괄호를 하나 더 쓰게 된다면 DataFrame의 형태로 출력된다.
| df[["A"]] |
결과는 다음과 같다.
| A | |
| 1 | 4 |
| 2 | 8 |
| 3 | 16 |
이처럼 DataFrame는 2차원의 구조를 가지고 있는 것을 확인할 수 있고, 이에 반해 Series는 1차원의 구조를 가지고 있는 것을 확인할 수 있다.
3. Subset(일부 값만 불러오기)
두 개 이상의 값을 불러올 때는 Series 형태가 아닌 DataFrame의 형태로 불러와야한다.
| df[df.Length > 7] #열 기준 예시 df[['width', 'length', 'species']] #행 기준 예시 df["a", "b"] # a, b와 같이 두 개 이상의 값을 Series 형태로 불러올 때는 오류가 발생 df[["a", "b"]] # DataFrame 형태로 불러오면 정상적으로 작동 |
4. Summarize Data
| df["A"].value_counts() |
해당 빈도수를 구한 결과는 다음과 같다.
| 16 1 8 1 4 1 Name: A, dtype: int64 |
5. Reshaping
#sort_values, drop
1) "A"컬럼을 기준으로 정렬하기
| df["A"].sort_values() |
해당 행을 기준으로 정렬한 결과는 다음과 같다.
| 1 4 4 4 2 8 3 16 Name: A, dtype: int64 |
2) DataFrame 전체에서 "A"값 기준으로 정렬하기
| df.sort_values("A") |
해당 DataFrame을 기준으로 정렬한 결과는 다음과 같다.
| A | B | C | |
| 1 | 4 | 3 | 10 |
| 4 | 4 | 3 | 10 |
| 2 | 8 | 9 | 11 |
| 3 | 16 | 27 | 12 |
3) 역순으로 정렬하기
| df.sort_values("A", ascending=False) |
해당 "A"값 기준으로 정렬한 결과는 다음과 같다.
| A | B | C | |
| 3 | 16 | 27 | 12 |
| 2 | 8 | 9 | 11 |
| 1 | 4 | 3 | 10 |
| 4 | 4 | 3 | 10 |
4) Drop
| df = df.drop(["c"], axis=1) df |
c칼럼을 드랍한 결과는 다음과 같다.
| A | B | |
| 1 | 4 | 3 |
| 2 | 8 | 9 |
| 3 | 16 | 27 |
| 4 | 4 | 3 |
6. Groupby
동일한 값으로 통계를 내거나 간단하게 요약할 때 사용하는 방법이다. 예를 들어 국가별로 데이터를 군집화하여 각 국가의평균 소득를 계산할 수 있다.
7. plot_table
이미 생성된 데이터를 재구성하여 간단하게 요약한 표를 생성할 때 사용된다.
행은 'Nation', 열은 'name', 값은 ' income'인 피벗 테이블을 생성하여 데이터를 재구성할 수 있다.
8. plotting
데이터를 다양한 방식으로 시작화 하는 것을 말한다.
데이터를 꺾은 선 그래프, 막대그래프, 밀도함수 등으로 나타낼 수 있다.
작성자 : 이나은
# 데이터 프레임 생성 및 Series

팬더스 라이브러리를 활용하면 다음과 같은 데이터 프레임을 생성할 수 있다. 여기서
df['(칼럼명)']이를 활용하면 위에서 a, b, c 등 각 칼럼에 있는 값만을 출력할 수 있다. 대괄호를 두번 쓰는 경우는 데이터 프레임 형태로 출력된다.
# Subset
df['(칼럼명)'] > 4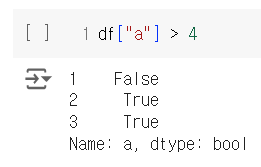
위와 같이 Subset을 활용하여 데이터의 일부만 불러올 수도 있다. 대괄호를 두번 치면 데이터 프레임의 형태로 바뀌는 것은 동일하다.
# Summarize Data

위와 같이 value counts로 빈도수를 체크할 수도 있고, len을 사용해 길이를 측정할 수도 있다.
# Reshaping
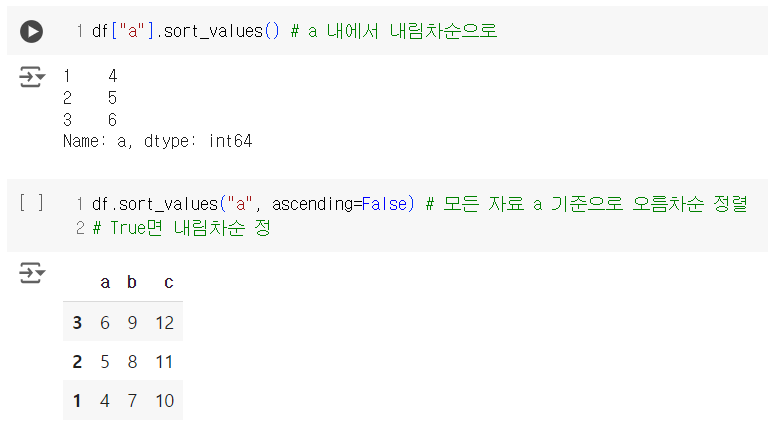

위와 같이 오름차순과 내림차순으로 데이터를 정리하는 것도 가능하며 열을 기준으로 drop하는 것도 가능하다.
# Group Data
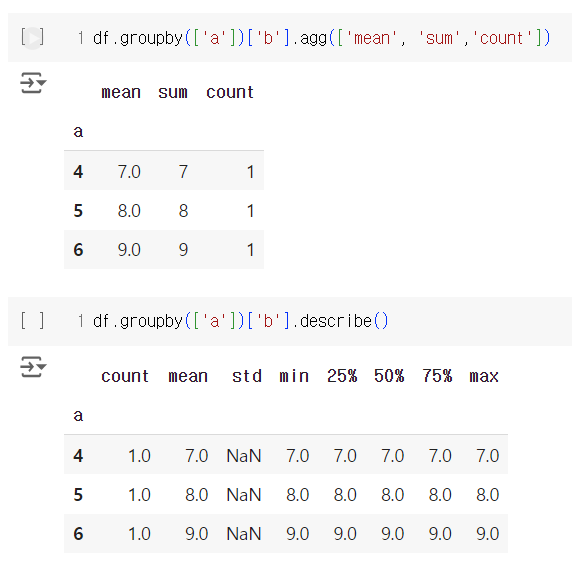
또, 데이터를 다양한 방법을 통해 그룹화하는 것도 가능하다.
작성자 : 김서현
1주차
중간고사 직전 배웠던 파이썬 이론들을 한번 더 정리하며 자주 사용되는 코드들에 대해 복습 후 퀴즈를 풀어보았다. 점프 투 파 이썬의 범위가 너무 방대하여 어떤 코드들이 중요하고 잘 사용되는지에 대한 감을 쉽게 잡을 수 없었지만, 이번 스터디를 통해 서 자주 사용되는 것들에 대해 다시 한번 복습하고 공부하며 더 효율적으로 공부할 수 있어 유익했다.
2주차
처음에는 pandas라는 새로운 개념이 등장하여 이걸 어떻게 사용하는지, 어디에 사용하는지에 대한 여러 궁금증이 생겼었는데, 여러번 보고 하나씩 따라해 보며 pandas라는 것에 대해 익숙해 졌다. 그 중 가장 재밌었던 단계는 plotting 단계로, 직접 시각화 해보고 그래프로 나타내 보니 흥미로웠다. 앞으로 있을 코드의 미니 프로젝트에서도 여러 시각화를 시켜야 하는 과정들이 많을 텐데, 기대가 될 뿐 아니라, 더 많이 공부하고 실전에 적용해 보고 싶다는 생각을 하게 되었다.
작성자: 김민정
1주차
첫 번째 활동이었던 Jump to Python 스터디 중 스스로 학습할 시간이 부족했다고 느껴졌던 부분에 대해 복습하는 시간을 가지고, 부스트코스 강의를 들으며 내용을 점검할 수 있었다. - 특히 여러 가지 오류 처리 방법에 대해 다시 공부하고, time모듈 함수를 직접 루프 안에서 실행해보았다.
2주차
pandas 스터디
부스트코스 강의를 통해 pandas 개념 학습을 시작했다. 처음에는 dataframe을 배우며 등장하는 행과 열조차 헷갈렸으나 강의 속 예시들을 직접 하나씩 실행해보니 이해할 수 있었다. plotting을 통해 처음으로 데이터를 시각화했는데, 예시를 따라해본 후 내가 듣는 전공 3과목의 중간고사에 대한 값을 dataframe으로 만들고 시각화해보는 방향으로 활용해보았다.
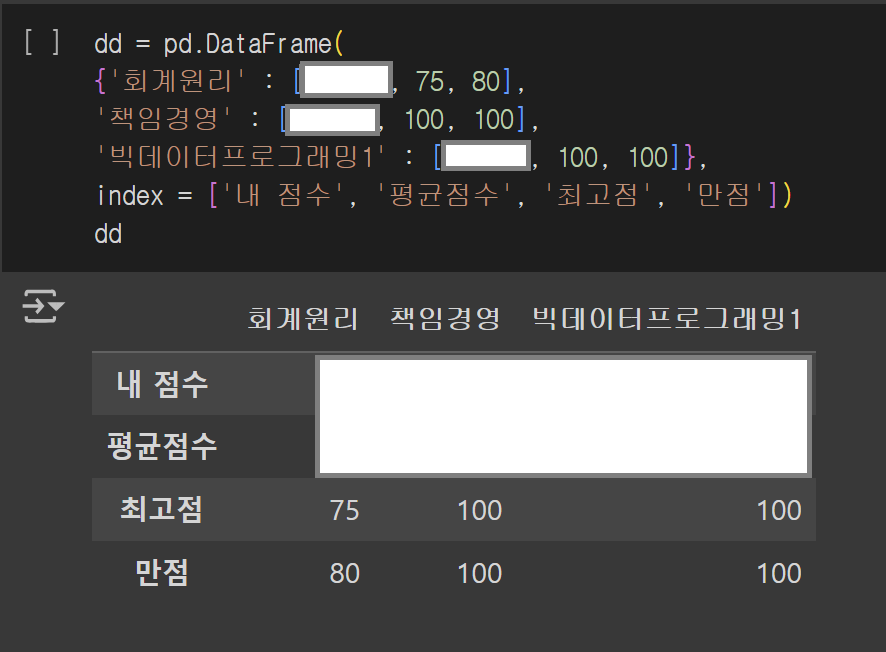
이때 직접 만든 dataframe으로 plotting을 해보니, pandas는 기본적으로 dataframe의 index를 x축 값으로 활용하니까 시각화를 할 때에 x축으로 활용하고 싶은 값을 index로 지정해야겠다는 것을 깨닫게 되었다. 또한, plot함수는 기본적으로 한국어를 지원하지 않으니 내부적으로 matplotlib을 통해 한글을 지원하는 폰트를 설정해둬야 시각화 과정에서 한국어가 나타나도록 할 수 있다는 것을 알게 되었다. 그리고 평소에는 세션을 종료한 후 나중에 다시 실행해도 별도의 과정 없이 잘 이어졌기에 생각하지 못했지만, 파이썬의 저장 방식에 따라 이전 세션에서 정의한 dataframe은 다시 사용할 때마다 라이브러리를 다시 임포트하고 데이터를 로드해야 되기 때문에 이를 습관화해야겠다는 생각을 하였다.
'Study > CODE 3기 [파이썬으로 배우는 데이터 사이언스]' 카테고리의 다른 글
| [최최레최레최정예 1조:김이김이나] K-beauty 온라인 판매 전략 (0) | 2024.05.29 |
|---|---|
| [4조:불사조] 건강검진데이터로 가설검정하기 (0) | 2024.05.28 |
| [5조 C5DE] 1, 2주차 스터디 (0) | 2024.05.17 |
| [2조:ACE] 1-2주차 (0) | 2024.05.16 |
| [불사조] 데이터 분석을 위한 핵심 파이썬 문법 + 판다스 활용법 (0) | 2024.05.16 |


