| 작성자: 김민정, 김서현, 정현석 목적 : K-beauty 매출은 국제 정세와 어떤 상관 관계를 갖고 변화하는지 탐구해보고자 함 목차 : 1. 데이터 전처리하기 2. 데이터 시각화하기 3. 가설 설정 및 가설 검증하기 |
1. 데이터 전처리하기
작성자 : 정현석
1-1
라이브러리 import
K-beauty의 매출 현황을 분석하기 위해 필요한 라이브러리를 임포트
|
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
|
pandas는 데이터 조작 및 분석을 위한 라이브러리
seaborn은 파이썬을 활용한 통계적 데이터 시각화를 위한 라이브러리
matplotlib.pyplot은 matplotlib의 시각화 모듈로, 다양한 그래프와 플롯을 생성 가능한 라이브러리
위의 라이브러리를 활용하여 데이터를 분석해보도록 한다.
1-2
구글 드라이브와 연동하여 CSV파일 불러오기
파일을 Colab으로 업로드 하는 과정에서 발생하는 오류를 방지하기 위해
구글 드라이브와 연동하여 파일을 불러오도록 한다.
Google 드라이브 모듈 임포트
|
from google.colab import drive
|
Colab에는 구글 드라이브와 연동하여 상호작용할 수 있는 google.colab 모듈이 포함되어 있다.
이 모듈의 drive 서브모듈을 사용하면 드라이브를 Colab 환경에 마운트할 수 있다.
드라이브 마운트
|
drive.mount('/content/gdrive')
|
drive.mount 메서드를 사용하여 구글 드라이브를 특정 디렉토리에 마운트한다.
/content/gdrive는 드라이브가 마운트될 경로로, 이 경로를 통해 Colab 환경에서 드라이브의 파일과 폴더에 접근한다.
📌 Colab에서 구글 드라이브를 마운트(mount)하는 것의 장점
1. 파일 접근: Colab 환경에서 Google 드라이브에 저장된 파일에 쉽게 접근 가능 2. 파일 저장: Colab 환경에서 생성된 파일이나 결과를 Google 드라이브에 저장할 수 있어, 작업이 끝난 후에도 데이터가 안전하게 보관 가능 3. 작업 연속성: Colab 세션이 종료되더라도, 작업한 파일들이 Google 드라이브에 저장되어 있어 나중에 다시 이어서 작업 가능 |
csv파일 불러오기
|
df = pd.read_csv('/content/gdrive/My Drive/지역별___상품군별_온라인쇼핑_해외직접판매액_20240530114255(code).csv', encoding = 'cp949')
|
앞서 저장한 Google 드라이브에 있는 CSV 파일을 경로를 지정하여 불러온다.
여기서 encoding='cp949'은 한글로 인코딩하기 위한 설정이다.
1-3
tidy data만들기
melt 함수를 이용하기
|
df.melt(id_vars=["지역별", "상품군별", "판매유형별"], var_name="기간", value_name="백만원")
|
데이터프레임을 melt 함수를 이용하여 다음과 같이 데이터프레임을 변환한다.
melt 함수는 Pandas 라이브러리에서 사용되는 데이터프레임 변환 함수로, 데이터를 길고 좁은 형식으로 변환한다.
이는 데이터의 열을 행으로 변환하여 피벗 테이블의 반대 작업을 수행하거나 시각화하는데 유용하다.
id_vars는 식별자로 사용할 열들을, var_name은 옮겨질 열의 이름을, value_name은 값이 될 열의 이름을 지정한다.
코드를 실행한 결과는 다음과 같다.

1-4
문자열의 데이터 타입 변경하기
열의 값을 연도로 표현하기
|
df["기간"] = df["기간"].astype(int)
|
"기간" 열의 값을 정수형(int type)으로 변환하여 연도로 표현한다.
여기서 astype는 Pandas 라이브러리에서 데이터프레임이나 시리즈의 자료형을 변환하는 데 사용된다.
astype를 사용하면 특정 열 또는 전체 데이터프레임의 데이터 타입을 변경할 수 있다.
결측치(-)를 NaN으로 replace하기
|
df["백만원"] = df["백만원"].replace('-', pd.NA)
|
replace 함수를 이용하여 "백만원" 열에서 '-' 값을 결측치(NaN)로 대체할 수 있다.
불필요한 데이터 제거하기
|
df = df[df["상품군별"] != "합계"]
|
"상품군별" 열에서 "합계"가 아닌 행들만 필터링하여 데이터프레임을 업데이트한다.
이제 데이터를 시각화하기 위한 데이터 전처리는 마무리 되었다.
지금까지 작성한 코드를 실행하면 다음과 같다.

2. 데이터 시각화하기
작성자 : 김민정
2-1
상품군별 판매량 데이터 시각화
시각화 하기 전, NA로 나타난 결측치 데이터의 행 삭제
df_total = df[df["판매유형별"] == "계"].copy()
df_total.head()결측치 데이터로 인해 시각화가 잘 안 나타나는 경우가 있어 미리 삭제하는 것이 좋다
연도에 따른 판매액을 lineplot으로 그려본다
sns.lineplot(data=df_total, x="연도", y="백만원", hue="상품군별")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)상품군별로 다른 색깔로 표시하고, legend 값을 외부에 표시하도록 하면 다음과 같은 결과가 나온다

시각화를 통해 화장품이 다른 상품군에 비해 크게 증가하였음을 확인할 수 있다
2-2
분기별 화장품 판매액 데이터 시각화
화장품 데이터 가져오기
우선 T/F를 나타내는 boolean 식을 만든다
df_total["상품군별"] == "화장품"상품군별이 화장품에 해당하는 데이터만 가져온다
(이때 원본 데이터에 변형이 가지 않도록 copy로 복사한다)
df_cosmetic = df_total[df_total["상품군별"] == "화장품"].copy()
df_cosmetic
가져온 데이터 확인하기
df_cosmetic["상품군별"].unique()unique함수로 화장품만 담긴 것이 확인될 경우, 시각화를 시작한다
연도별로 시각화하기
sns.lineplot(data=df_cosmetic, x="연도", y="백만원")x축을 연도로 설정하여 시각화할 수도 있다
국가(대륙)별로 시각화하기
plt.figure(figsize=(15,4))
plt.xticks(rotation=30)
sns.lineplot(data=df_cosmetic, x="기간", y="지역별")위 과정을 통해 중국에서의 판매액이 가장 높다는 것을 알 수 있다.
3. K-beauty와 국제정세의 상관관계 분석
작성자 : 김민정, 김서현
가설: ‘알타시아’ (탈중국화)가 k-beauty 매출액에 영향을 미쳤는가?
최근, '알타시아'라는 새로운 개념의 등장이 전세계적으로 어마무시한 영향력을 미치고 있다.


이러한 영향력이 k-뷰티 시장에 어떠한 영향력을 미쳤는지 알아보고자 이러한 가설을 설정하였다.
연도별로만 분류된 데이터로 코로나19, 탈중국화 등의 국제정세가 K-beauty 판매에 미친 영향을 알아보고자 한다.

tidy data를 만들고 문자열 분리, 데이터 타입 변경을 진행한 후 시각화한다.
코로나19에 대하여 2020년을 기준으로 삼고 lineplot을 사용하였다.
중국 시장에서의 매출 변화를 확인할 수 있도록 하였다.
'상품군별' 중 '합계'가 아닌 데이터 필터링
df = df[df["상품군별"] != "합계"]
# 중국의 화장품 매출 데이터 필터링
china_cosmetics = df[(df["지역별"] == "중국") & (df["상품군별"] == "화장품")]
# 연도별 중국 화장품 매출 변화 그래프
plt.figure(figsize=(14, 7))
sns.lineplot(data=china_cosmetics, x="기간", y="백만원", marker='o')
plt.title('연도별 중국 화장품 매출 변화')
plt.xlabel('연도')
plt.ylabel('매출 (백만원)')
#코로나 시작에 해당하는 2020년 별도 표시
plt.axvline(x=2020, color='blue', linestyle='--', label='코로나 시작')
plt.legend()
plt.grid(True)
plt.show()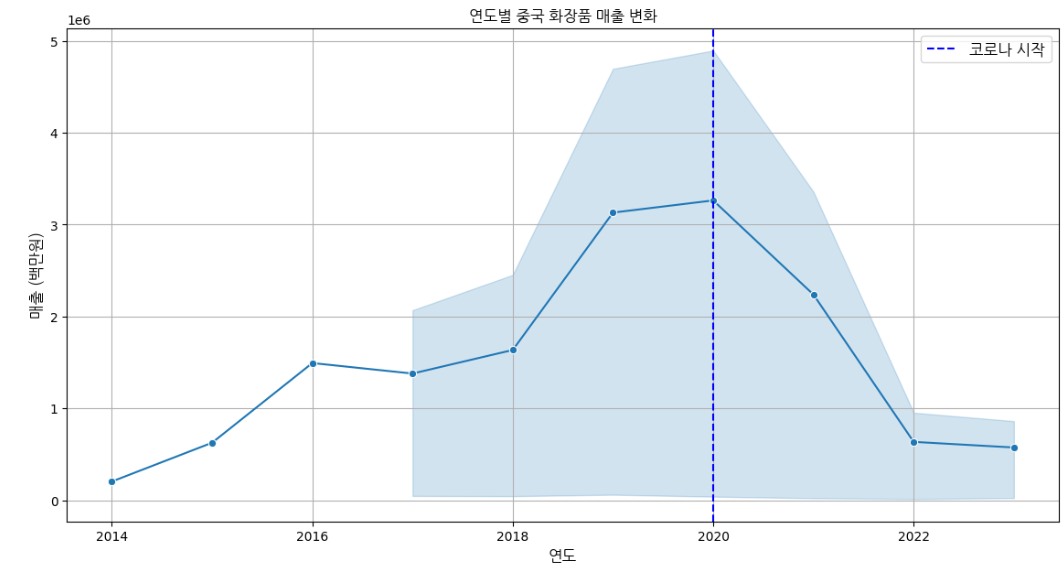
위 그래프를 통해 코로나 이후로 중국에서의 K-beauty 매출이 급격히 감소하는 것을 확인할 수 있다.
탈중국화로 중국시장의 대안으로 떠오른 동남아시아 시장에서의 매출 변화 또한 확인해보았다.
# 아세안의 화장품 매출 데이터 필터링
asean_cosmetics = df[(df["지역별"] == "아세안") & (df["상품군별"] == "화장품")]
plt.figure(figsize=(14, 7))
sns.lineplot(data=asean_cosmetics, x="기간", y="백만원", marker='o')
plt.title('연도별 아세안 화장품 매출 변화')
plt.xlabel('연도')
plt.ylabel('매출 (백만원)')
plt.axvline(x=2020, color='blue', linestyle='--', label='코로나 시작')
plt.legend()
plt.grid(True)
plt.show()<그래프 1>에서 코로나19 이후 급격하게 줄어든 중국 시장에서 이제는 미국과의 정치적 문제뿐만 아니라, 중국의 경제 성장이 둔화하며 소비 시장이 위축되고 있음을 알 수 있다.
우리 조가 조사한 중국의 k-뷰티 시장 역시, 코로나 19로 인해 눈에 띄게 감소하였고, 작년 3분기부터 새롭게 등장한 ‘알타시아’라는 개념이 전세계적으로 영향을 미치며 중국의 k-뷰티 시장은 더욱더 하락세를 보이고 있다.
알타시아란, 중국을 대체하는 아시아 국가들을 의미한다.
중국 대안으로 2023년부터 알타시아, 즉, 중국을 대체하는 아시아 국가들로 동남아시아 국가들이 떠오르면서 여러 기업에서 베트남을 중심으로 많은 알타시아 국가들로 시장이 뻗어 나가고 있다.
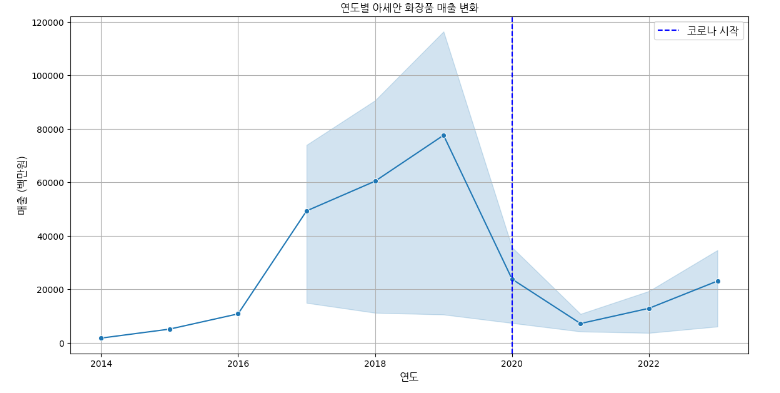
이러한 점이 k-뷰티 시장에도 영향을 미치는지 확인해 보기 위해 데이터를 사용하여 아세안 (동남아시아) 국가들의 매출 변화를 분석해 본 결과, <그래프 2> 처럼 코로나 19로 감소했던 k-뷰티 시장이 ‘중국의 대안 국가’으로 떠오르며 2023년부터 더 높은 성장세를 보이고 있음을 확인할 수 있었다.
코로나로 인해 동남아시아 시장에서의 매출 또한 일시적으로 감소했으나,
동남아시아 시장이 중국 시장의 대체로 떠오르며 다시 매출이 증가하기 시작하였고 앞으로 더욱 증가할 것으로 보인다.
'Study > CODE 3기 [파이썬으로 배우는 데이터 사이언스]' 카테고리의 다른 글
| [비비빅] 행정구역별 병원당 노인 인구수 비교 분석 (0) | 2024.06.01 |
|---|---|
| [2조:ACE] K-beauty 온라인 판매 분석 (0) | 2024.06.01 |
| [C5DE] 수도권/비수도권 간 의료 격차 알아보기 (1) | 2024.05.31 |
| [우승은어짜피우리] K-beauty 온라인 판매분석 (1) | 2024.05.30 |
| [불4조 - 코린이집] 서울 종합병원 분포 확인하기 (0) | 2024.05.29 |



