team 2
프로젝트 주제 및 선정 배경
공공 심야 약국이란 일반적으로 심야 시간대에도 의약품을 구매할 수 있는 약국을 의미합니다. 공공 심야 약국은 특히 심야 시간에 발생하는 응급 상황에서 시민들이 필수적인 의약품을 구입할 수 있도록 도움을 주는 중요한 공공 서비스입니다. 이는 응급실 방문을 줄이고, 응급 상황에서의 신속한 대처를 가능하게 하여 시민 건강과 안전에 기여하는 역할을 합니다.

현재 서울시에는 일부 심야 약국이 운영되고 있지만, 이들의 위치와 운영 시간은 일정하지 않거나 제한적이어서 실질적으로 시민들이 긴급한 상황에서 필요한 의약품을 쉽게 구할 수 없는 경우가 발생하고 있습니다. 예를 들어, 야간에 아동이 열이 나는 경우나 고령자가 갑작스럽게 필요한 약품을 구할 수 없는 경우 응급실 방문으로 이어지는 경우가 많습니다. 편의점에서 판매중인 의약품은 성분에 따라 판매할 수 있는 종류가 제한되어있습니다. 또한 의약품에 대한 약사의 복약상담이 없어 오남용이 발생할 위험이 큽니다.

이로 인해 불필요한 응급실 이용이 증가하여 의료비와 사회적 비용이 가중되는 문제를 낳고 있습니다.
서울시는 이러한 문제를 해결하고자 공공 심야 약국을 확대하려 하고 있으며, 이를 위해 기존 심야 약국의 운영 효율성을 개선하고 새로운 심야 약국의 설치 위치를 전략적으로 선정하는 것이 중요한 과제가 되었습니다.
현재 서울시의 공공 심야 약국 운영 현황 및 문제점은 다음과 같습니다:
- 심야 시간대 운영하는 약국의 부족(서울시 내 자치구별로 최대 2개소만 운영)으로 인한 긴급 약품 접근성의 문제
- 특정 지역에 편중된 심야 약국 배치로 인해 발생하는 지역 간 형평성 문제
- 응급실을 방문하는 불필요한 사례 증가로 인해 발생하는 의료비와 사회적 비용 증가
이러한 문제를 해결하기 위해 서울시는 공공 심야 약국의 신규 설치에 대한 필요성을 인식하고 있으며, 저희 팀은 이를 데이터 분석을 통해 효과적으로 지원하고자 합니다.
프로젝트 목적
저희 팀은 서울시 공공 심야 약국 운영 실태와 시민들의 심야 의약품 접근성을 분석하여:
- 심야 의약품 접근성 사각지대에 있는 지역을 파악하고,
- 효율적인 약국의 확대 방안을 제시하며, 심야 약국의 신규 설치가 필요한 최적 위치를 추천하는 데이터를 기반으로 한 분석 프로젝트를 기획하게 되었습니다.
이 프로젝트를 통해 심야 시간에 시민들의 의약품 접근성을 높이고, 불필요한 응급실 방문을 줄여 공공의료비 절감에 기여할 수 있는 서울시 공공 심야 약국의 효과적 확대 방안을 제시하고자 합니다.
▶ 프로젝트 목표
① 관련 데이터 수집을 통해 행정구역별 인구/행정구역별 의료취약지수를 산출.
② 현재 설치되어 있는 심야 약국 입지와 지수를 동시에 고려하여 최소 비용으로 최대 수요를 만족할 만한 심야 약국 입지를 선정함.
▶ 활용 데이터 소개 및 프로젝트 개요
▷ 데이터 수집(시각화) → 데이터 전처리(PYTHON, 시각화) → 데이터 분석(QGIS, 시각화) → 최적 입지 선정 및 분석 결과
1. 데이터 수집
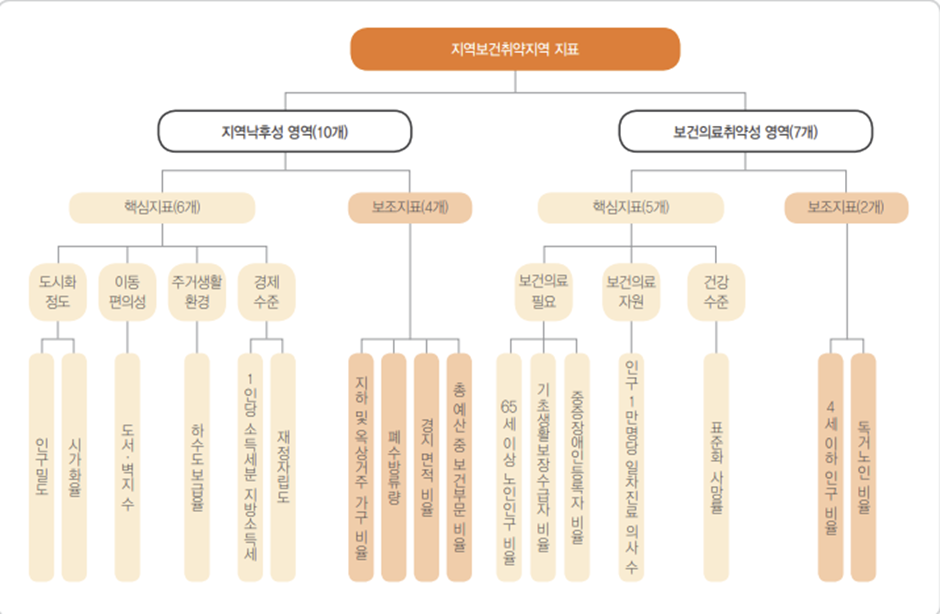
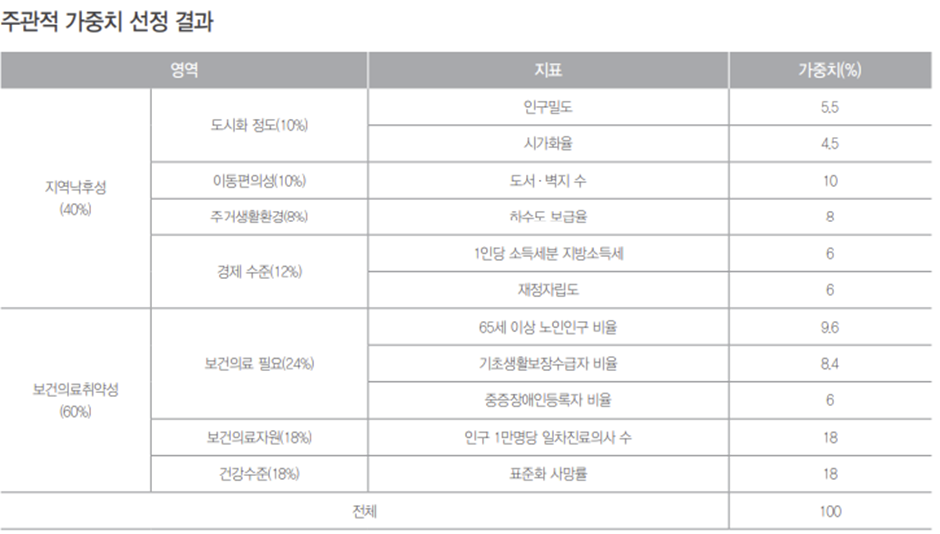
시·도별 지역보건취약지역 보고서에 나온 보건의료취약성 영역의 핵심지표를 이용
데이터 수집의 기준을 마련하였다. 지역낙후성은 심야 약국과 큰 상관관계가 없다고 생각해 배제하고, 보건의료 취약성의 5가지 지표를 이용하기로 하였다. 지표 중 인구 1만명당 일차진료의사 수는 응급실 공급자의 관점에서 사용한 지표라고 생각하여 응급실 이용자수로 지표를 수정하였습니다.
보건의료취약성(60%)를 백분율로 나타내어 가중치를 설정하고 정규화 후 모두 더하여 의료취약지수로 사용하였습니다.
| 65세 이상 노인인구 비율 | 16% |
| 기초생활수급자 비율 | 14% |
| 중증장애인등록자 비율 | 10% |
| 응급실 이용자 현황 | 30% |
| 행정동별 사망률 | 30% |
행정동 단위 생활인구 (내국인) 데이터, 서울열린데이터광장
행정동 단위 고령자 현황 데이터, 서울열린데이터광장
행정동 단위 국민기초생활보장수급자 현황 데이터, 서울열린데이터광장
행정동 단위 장애인 현황 데이터, 서울시빅데이터캠퍼스
생활인구 (내국인) 데이터
https://data.seoul.go.kr/dataList/OA-14991/S/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
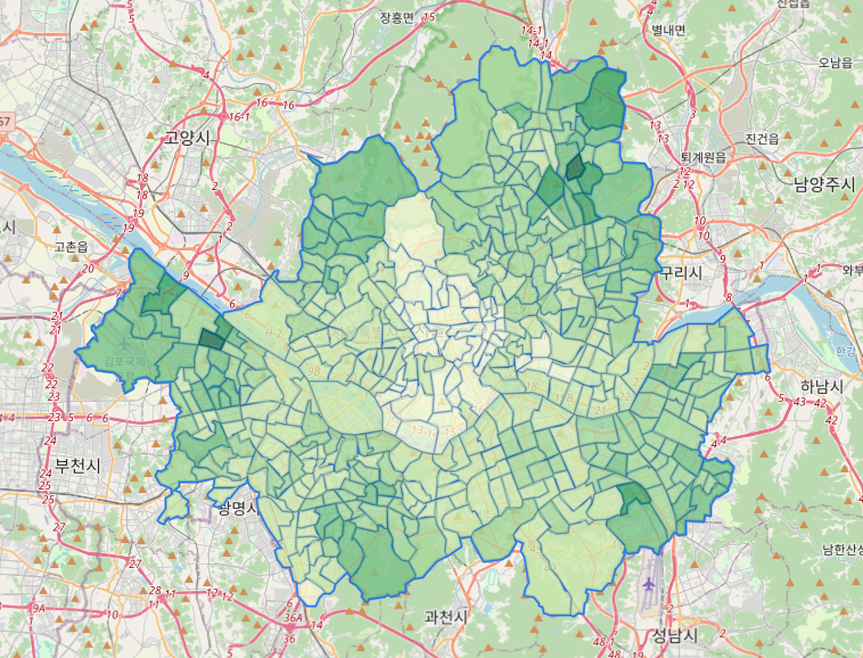
각 행정동별 인구는 곧 추후 의료취약지수와 곱하여 심야 약국 실사용자를 구할 때 사용
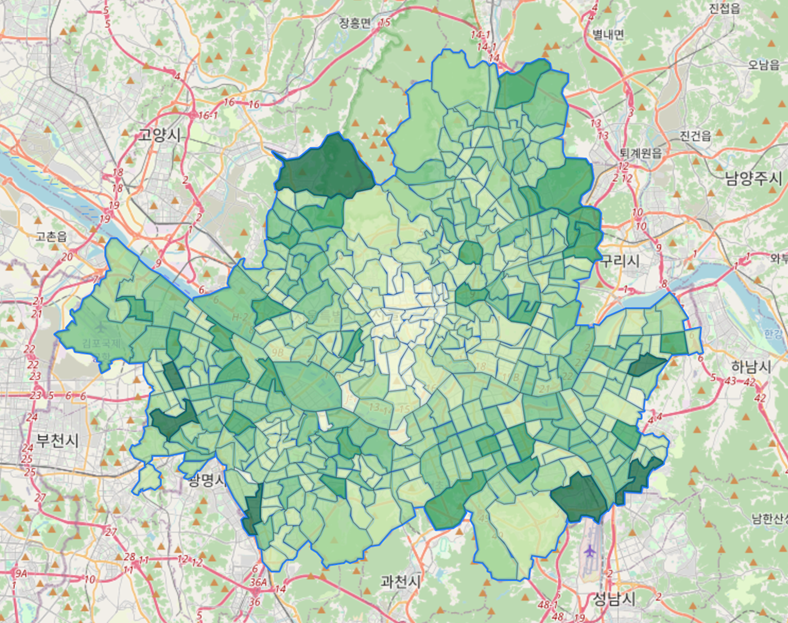
서울시 행정동별 거주인구 데이터(시각화)
고령자 현황 데이터
https://data.seoul.go.kr/dataList/10730/S/2/datasetView.do
국민기초생활보장수급자 현황 데이터
https://data.seoul.go.kr/dataList/10113/S/2/datasetView.do
장애인 현황 데이터
https://data.seoul.go.kr/dataList/10476/S/2/datasetView.do
사망률 데이터
https://www.data.go.kr/data/15099156/fileData.do
응급실 이용 데이터
https://data.seoul.go.kr/dataList/11034/A/2/datasetView.do
2. 데이터 전처리

- 행정동, 행정코드로 같은 데이터가 다른 이름으로 저장된 경우가 많았음. pandas에서 sqlite를 사용해 데이터를 통합함.
- 5가지 지수에 각각 가중치를 곱한 후에 t점수로 환산(
- Min/max scaling 으로 진행하면 이상치 보정이 어려움.
- T점수(평균 50, 표준편차 10)으로 환산 + 가중치 곱(14%)
서울시 의료취약지수 데이터(시각화)
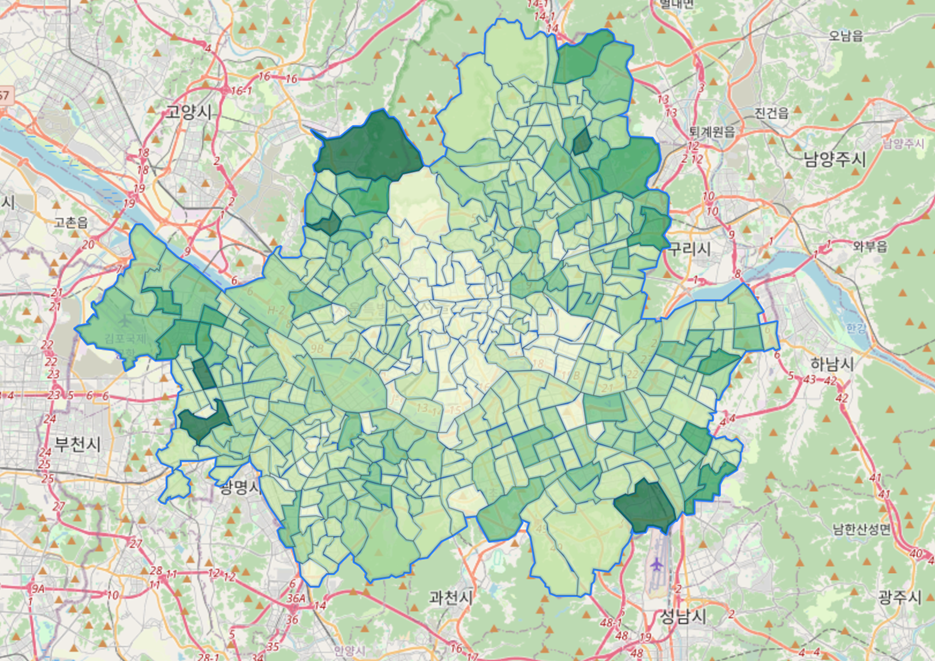
서울시 행정동별 거주인구 데이터 x 서울시 의료취약지수 데이터
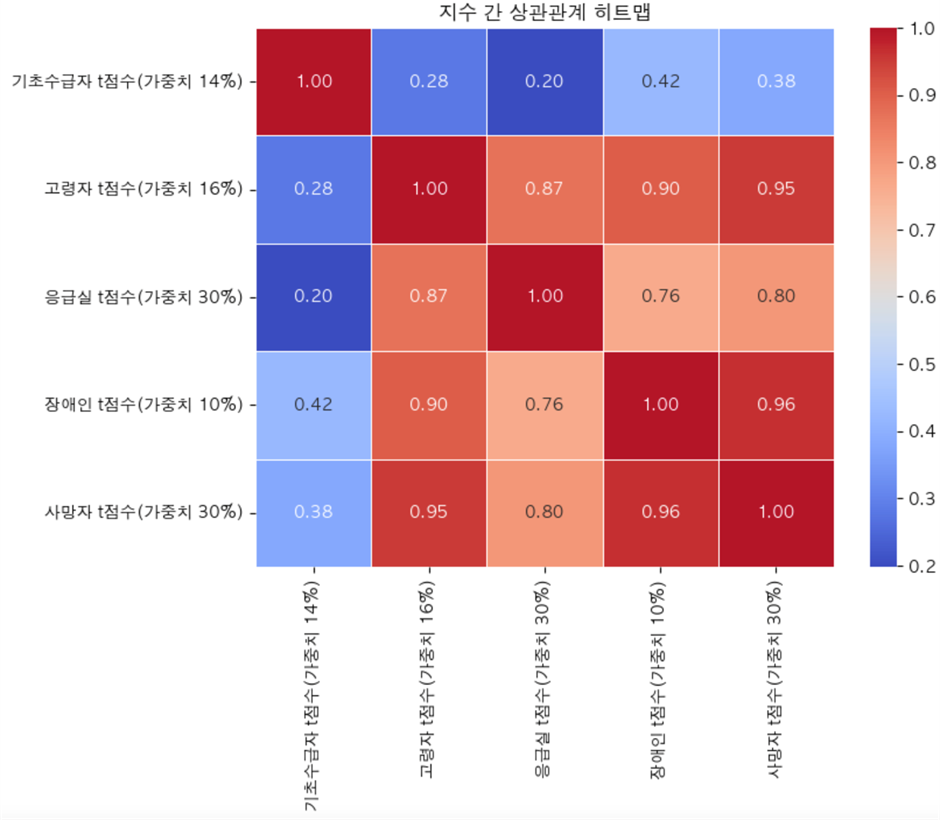
상관관계 분석을 통해 각 지수의 관계를 확인하는 것이 가능.
- 기초수급자를 제외한 4가지 지수가 상관관계가 높게 나옴.
- 한계점으론 이 같은 결과로 더 나은 결과를 만드는데 기여하지 못함.
데이터 전처리 코드
#기초수급자 지수 계산
import numpy as np
import pandas as pd
from scipy import stats
df = pd.read_excel("전처리 이전 통합 데이터.xlsx")
print(df["기초수급자 현황"])
# '기초수급자 현황' 열을 숫자로 변환하고, 변환할 수 없는 값은 NaN으로 처리
df['기초수급자 현황'] = df['기초수급자 현황'].astype(int)
# 단일 표본 t-검정 (기본 비교 평균값은 0으로 설정)
t_statistic, p_value = stats.ttest_1samp(df['기초수급자 현황'], 50)
# 결과 출력
print(f"T-통계량(T-statistic): {t_statistic}, P-값(P-value): {p_value}")
print(df['기초수급자 현황'].dtype)
# 기본 설정
pop_mean = 50 # 모집단 평균
sample_size = len(df['기초수급자 현황']) # 표본의 크기
sample_mean = np.mean(df['기초수급자 현황']) # 표본의 평균
sample_std = np.std(df['기초수급자 현황'], ddof=1) # 표본의 표준편차 (ddof=1은 자유도 보정)
# 각 데이터에 대해 t-점수 계산
df['t_score'] = (df['기초수급자 현황'] - pop_mean) / (sample_std / np.sqrt(sample_size))
# t-점수 출력
print(df[['기초수급자 현황', 't_score']])
# 평균 50, 표준편차 10인 t 점수로 변환
df['t_score_new'] = (50 + 10 * df['t_score']) * 0.14
# 변환된 t 점수 출력
print(df['t_score_new'].to_string(index=False))#고령자현황 지수 계산
import numpy as np
import pandas as pd
from scipy import stats
df = pd.read_excel("고령자현황(16%)(구별).xlsx")
print(df["고령자지수"])
# '기초수급자 현황' 열을 숫자로 변환하고, 변환할 수 없는 값은 NaN으로 처리
df['고령자지수'] = df['고령자지수'].astype(int)
# 기본 설정
pop_mean = 50 # 모집단 평균
sample_size = len(df['고령자지수']) # 표본의 크기
sample_mean = np.mean(df['고령자지수']) # 표본의 평균
sample_std = np.std(df['고령자지수'], ddof=1) # 표본의 표준편차 (ddof=1은 자유도 보정)
# 각 데이터에 대해 t-점수 계산
df['t_score'] = (df['고령자지수'] - pop_mean) / (sample_std / np.sqrt(sample_size))
# t-점수 출력
print(df[['고령자지수', 't_score']])
# 평균 50, 표준편차 10인 t 점수로 변환
df['t_score_new'] = (50 + 10 * df['t_score']) * 0.16
# 변환된 t 점수 출력
print(df['t_score_new'].to_string(index=False))#응급실 지수 계산
import numpy as np
import pandas as pd
from scipy import stats
df = pd.read_excel("구별 응급실 이용자 현황(응급지수)(구별)(30%).xlsx")
print(df["응급실이용자"])
# '기초수급자 현황' 열을 숫자로 변환하고, 변환할 수 없는 값은 NaN으로 처리
df['응급실이용자'] = df['응급실이용자'].astype(int)
# 단일 표본 t-검정 (기본 비교 평균값은 0으로 설정)
t_statistic, p_value = stats.ttest_1samp(df['응급실이용자'], 50)
# 결과 출력
print(f"T-통계량(T-statistic): {t_statistic}, P-값(P-value): {p_value}")
print(df['응급실이용자'].dtype)
# 기본 설정
pop_mean = 50 # 모집단 평균
sample_size = len(df['응급실이용자']) # 표본의 크기
sample_mean = np.mean(df['응급실이용자']) # 표본의 평균
sample_std = np.std(df['응급실이용자'], ddof=1) # 표본의 표준편차 (ddof=1은 자유도 보정)
# 각 데이터에 대해 t-점수 계산
df['t_score'] = (df['응급실이용자'] - pop_mean) / (sample_std / np.sqrt(sample_size))
# t-점수 출력
print(df[['응급실이용자', 't_score']])
# 평균 50, 표준편차 10인 t 점수로 변환
df['t_score_new'] = (50 + 10 * df['t_score']) * 0.3
# 변환된 t 점수 출력
print(df['t_score_new'].to_string(index=False))#장애인 지수 계산
import numpy as np
import pandas as pd
from scipy import stats
df = pd.read_excel("장애인+현황(구별)(10%).xlsx")
print(df["장애인수"])
# '기초수급자 현황' 열을 숫자로 변환하고, 변환할 수 없는 값은 NaN으로 처리
df['장애인수'] = df['장애인수'].astype(int)
# 단일 표본 t-검정 (기본 비교 평균값은 0으로 설정)
t_statistic, p_value = stats.ttest_1samp(df['장애인수'], 50)
# 결과 출력
print(f"T-통계량(T-statistic): {t_statistic}, P-값(P-value): {p_value}")
print(df['장애인수'].dtype)
# 기본 설정
pop_mean = 50 # 모집단 평균
sample_size = len(df['장애인수']) # 표본의 크기
sample_mean = np.mean(df['장애인수']) # 표본의 평균
sample_std = np.std(df['장애인수'], ddof=1) # 표본의 표준편차 (ddof=1은 자유도 보정)
# 각 데이터에 대해 t-점수 계산
df['t_score'] = (df['장애인수'] - pop_mean) / (sample_std / np.sqrt(sample_size))
# t-점수 출력
print(df[['장애인수', 't_score']])
# 평균 50, 표준편차 10인 t 점수로 변환
df['t_score_new'] = (50 + 10 * df['t_score']) * 0.1
# 변환된 t 점수 출력
print(df['t_score_new'].to_string(index=False))#사망자 지수 계산
import numpy as np
import pandas as pd
from scipy import stats
df = pd.read_excel("사망원인별+사망(성별_구별)(30%).xlsx")
print(df["사망자수"])
# '기초수급자 현황' 열을 숫자로 변환하고, 변환할 수 없는 값은 NaN으로 처리
df['사망자수'] = df['사망자수'].astype(int)
# 단일 표본 t-검정 (기본 비교 평균값은 0으로 설정)
t_statistic, p_value = stats.ttest_1samp(df['사망자수'], 50)
# 결과 출력
print(f"T-통계량(T-statistic): {t_statistic}, P-값(P-value): {p_value}")
print(df['사망자수'].dtype)
# 기본 설정
pop_mean = 50 # 모집단 평균
sample_size = len(df['사망자수']) # 표본의 크기
sample_mean = np.mean(df['사망자수']) # 표본의 평균
sample_std = np.std(df['사망자수'], ddof=1) # 표본의 표준편차 (ddof=1은 자유도 보정)
# 각 데이터에 대해 t-점수 계산
df['t_score'] = (df['사망자수'] - pop_mean) / (sample_std / np.sqrt(sample_size))
# t-점수 출력
print(df[['사망자수', 't_score']])
# 평균 50, 표준편차 10인 t 점수로 변환
df['t_score_new'] = (50 + 10 * df['t_score'])*0.3
# 변환된 t 점수 출력
print(df['t_score_new'].to_string(index=False))#상관관계 분석
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import platform
# 한글 폰트 설정
if platform.system() == 'Darwin': # MacOS
rc('font', family='AppleGothic')
elif platform.system() == 'Windows': # Windows
rc('font', family='Malgun Gothic')
else:
print("지원되지 않는 운영체제입니다.")
plt.rcParams['axes.unicode_minus'] = False # 마이너스 기호 깨짐 방지
# 데이터프레임 생성 (파일 경로 수정)
file_path = "/Users/kmh5692/Downloads/노인취약지수.xlsx"
df = pd.read_excel(file_path)
# 필요한 열만 추출
scaled_df = df[["기초수급자 t점수(가중치 14%)", "고령자 t점수(가중치 16%)", "응급실 t점수(가중치 30%)", "장애인 t점수(가중치 10%)", "사망자 t점수(가중치 30%)"]]
# 상관계수 계산
correlation_matrix = scaled_df.corr()
# 히트맵 그리기
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f", linewidths=0.5)
# 글자 각도 조정
plt.xticks(rotation=0) # 가로 범주 글자 각도 설정
plt.yticks(rotation=0) # 세로 범주 글자 각도 설정
# 그래프 파일로 저장 (PNG 형식)
plt.savefig('correlation_heatmap.png', dpi=300, bbox_inches='tight')
# 그래프 제목 및 라벨 설정
plt.title('지수 간 상관관계 히트맵')
plt.show()#행정동별 거주인구 시각화
!pip install folium
!pip install geojsonimport pandas as pd
import geopandas as gpd
# 모든 열을 출력하도록 설정
pd.set_option('display.max_columns', None)
# 행정동 인구 데이터 로드
population_data = pd.read_csv('행정안전부_지역별(행정동) 성별 연령별 주민등록 인구수_20240831.csv', encoding='cp949')
# 행정구역 경계 데이터 로드
boundary_data = gpd.read_file('HangJeongDong_ver20240701 마지막 2개 추가.geojson')
# 행정기관코드를 문자열로 변환
population_data['행정기관코드'] = population_data['행정기관코드'].astype(str)
# 데이터 결합
merged_data = boundary_data.merge(population_data, left_on='adm_cd2', right_on='행정기관코드')
# print(merged_data.head()) # 데이터의 첫 몇 줄을 출력
# print(merged_data.columns) # 열 이름을 출력
import folium
from folium import GeoJson
# 기본 지도 생성
m = folium.Map(location=[37.5665, 126.978], zoom_start=11)
# GeoJson으로 경계 데이터 추가
GeoJson(merged_data).add_to(m)
# 인구 수에 따라 색상 조정folium.Choropleth(
geo_data=merged_data,
name='인구 분포',
data=merged_data,
columns=['행정기관코드', '계'],
key_on='feature.properties.adm_cd2',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
).add_to(m)
# 지도 표시
m.save('population_distribution_map.html')
print(m)#의료취약지수 시각화
import pandas as pd
import geopandas as gpd
# 모든 열을 출력하도록 설정
pd.set_option('display.max_columns', None)
# 노인 취약 지수 로드
value_data = pd.read_excel('노인취약지수.xlsx')
# 행정구역 경계 데이터 로드
boundary_data = gpd.read_file('HangJeongDong_ver20240701 마지막 2개 추가.geojson')
# 행정기관코드를 문자열로 변환
value_data['행정기관코드'] = value_data['행정기관코드'].astype(str)
# 데이터 결합
merged_data = boundary_data.merge(value_data, left_on='adm_cd2', right_on='행정기관코드')
# print(merged_data.head()) # 데이터의 첫 몇 줄을 출력
# print(merged_data.columns) # 열 이름을 출력
import folium
from folium import GeoJson
# 기본 지도 생성
m = folium.Map(location=[37.5665, 126.978], zoom_start=11)
# GeoJson으로 경계 데이터 추가
GeoJson(merged_data).add_to(m)
# 인구 수에 따라 색상 조정 (예시)
folium.Choropleth(
geo_data=merged_data,
name='인구 분포',
data=merged_data,
columns=['행정기관코드', '노인취약지수'],
key_on='feature.properties.adm_cd2',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
).add_to(m)
# 지도 표시
m.save('노인취약지수_map.html')
print(m)import pandas as pd
# 엑셀 파일 불러오기
file1 = pd.read_csv('행정안전부_지역별(행정동) 성별 연령별 주민등록 인구수_20240831.csv', encoding = "cp949") # 파일1
file2 = pd.read_excel('노인취약지수.xlsx') # 파일2
# "읍면동면" 열과 "행정동" 열이 같을 때, file1에서 "행정기관코드"를 새로운 열로 추가
merged_df = pd.merge(file1, file2, left_on='읍면동명', right_on='행정동', how='left')
# 필요한 열만 출력 (기존 파일1의 데이터와 행정기관코드가 추가된 데이터)
print(merged_df[['읍면동명', '행정기관코드']].head(428))
# 엑셀로 저장 (필요시)
merged_df[['읍면동명', '행정기관코드']].head(428).to_excel('읍면동명_행정기관코드.xlsx', index=False)#의료취약지수 x 거주인구수 시각화
import pandas as pd
data = pd.read_csv("행정안전부_지역별(행정동) 성별 연령별 주민등록 인구수_20240831.csv", encoding = "cp949")
print(data[["계"]].head(426).to_string(index=False))
3. 데이터 분석
행정동별 인구로 공공야간약국을 선정한다면 행정구역별 면적 차이에 따라 선정과정에서 왜곡이 발생할 수 있다.
서울시 전체를 500mX500m의 타일로 나눠 선정과정에서 정확하게 변수를 고려할 수 있도록 하였다.
지리 공간 데이터를 시각화, 분석, 편집하는 QGIS라는 프로그램을 사용.
서울시 전체를 타일로 나누어, 행정구역별 인구 X 의료취약지수 값을 컬러맵으로 적용하여 각 지역별 지수를 한 눈에 알아볼 수 있도록 시각화하였다.
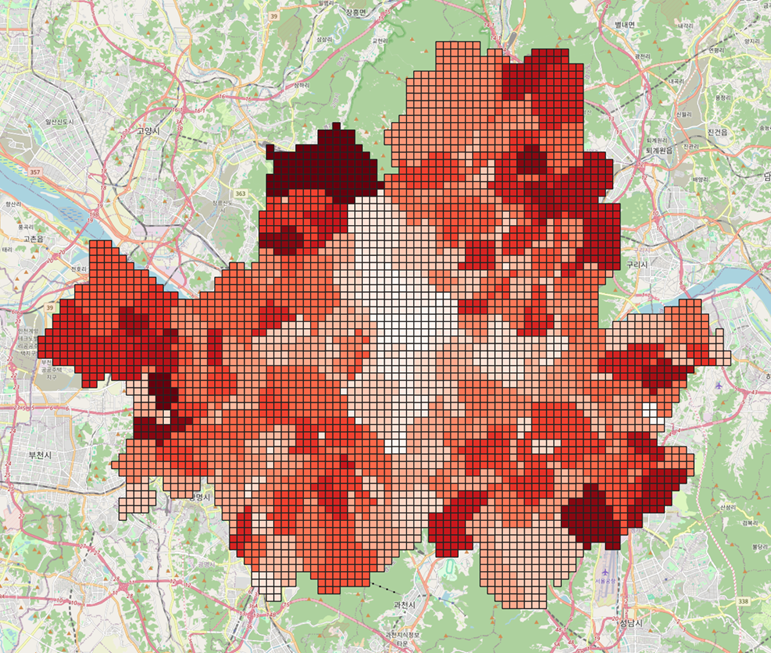
타일별 거주인구데이터 x 의료취약지수데이터
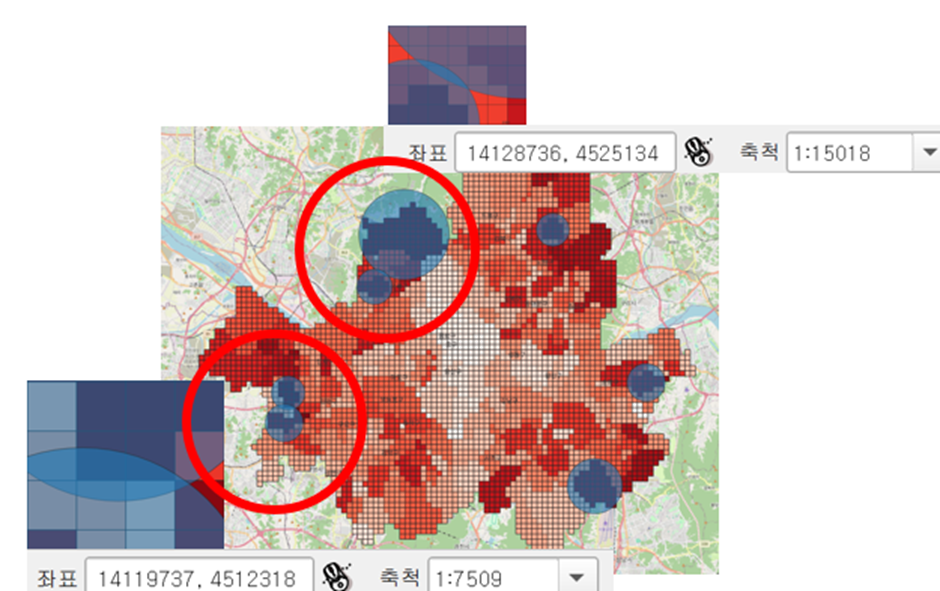
진한 컬러의 타일 군집의 중심에 점 벡터를 설정하여 데이터 포인트를 생성하였습니다. 그리고 데이터 포인트를 중심으로 하는 원을 그렸는데요. 원의 반지름은 타일 개수와 비례하는 버퍼로 설정하여 데이터 포인트의 수요 커버리지를 확인할 수 있었습니다. 우측의 수요 커버리지가 겹치는 지역을 다수의 수요가 몰리는 지역이라고 인식하였습니다.
-> 두 지역 도출(은평구 대조동, 양천구 신월동)
4. 최적 입지 선정 및 분석 결과
거주인구와 의료취약지수를 고려한 최적의 공공야간약국의 입지 선정 기준을 마련할 수 있었다.
QGIS를 통해 서울을 500m X 500m 그리드로 나누고 취약지수가 높은 타일을 산출한 후에 해당 지점의 중심점을 점벡터로 사용하였고, 점벡터에는 해당 타일 개수와 비례하는 버퍼를 할당하여 적절한 수요 커버리지를 설정했다.
추후 공공심야약국의 확대를 수요 커버리지가 겹치는 곳에 설치하는 곳이 최다수를 만족할 것이라 생각하여 겹치는 부분을 입지로 선정하기로 결정했다
-> 두 지역 도출(은평구 대조동, 양천구 신월동)