[RNN]
1. RNN의 개요
Recurrent Neural Network(RNN)는 순환 구조를 가지는 딥러닝 모델로, 현재 타임스텝의 예측값을 이전 타임스텝의 정보에 기반하여 산출한다. RNN은 매 타임스텝마다 동일한 파라미터를 가진 모듈을 반복적으로 호출하여 이전의 상태 정보를 계속 이어가는 '재귀적인 호출' 방식을 따르기 때문에 '순환 신경망'이라고 한다.
2. RNN 계산법
RNN의 학습과 예측은 시간 축에 따라 단계적으로 진행된다. 이 과정에서는 각 타임스텝 t에 대해 입력 벡터, 이전 hidden state, 새로운 hidden state, 출력 벡터가 모두 계산에 활용된다.
<주요 변수>
- x_t : 현재 타임스텝 t의 입력 벡터이다.
- h_{t-1} : 이전 타임스텝 t−1의 hidden state 벡터이다.
- h_t : 현재 타임스텝 t의 새로운 hidden state 벡터이다.
- f_wf : 파라미터 W로 정의된 RNN의 함수로, 이전 상태와 현재 입력을 바탕으로 새로운 hidden state를 계산한다.
- y_t : 현재 타임스텝 t의 출력 벡터이다.
<RNN의 계산 과정>
RNN에서는 매 타임스텝 t마다 이전 hidden state h_{t-1}와 현재 입력 x_t가 RNN의 함수 f_w에 입력된다. 이 함수는 매 타임스텝에서 동일한 가중치 W를 사용하여 새로운 hidden state h_t를 구한다.
h_t = f_w(h_{t-1}, x_t))
일반적으로 활성화 함수 tanh와 같은 비선형 함수를 사용하여 hidden state를 계산한다. 이렇게 계산된 h_t와 입력 x_t를 통해 현재 타임스텝의 출력값 y_t가 산출된다. 이와 같은 구조 덕분에 RNN은 시간 순서에 따라 정보를 누적해 나가면서, 과거의 정보가 현재 예측에 반영될 수 있다.
3. 다양한 타입의 RNN 모델
RNN은 다양한 입력-출력 구조에 따라 여러 유형으로 나눌 수 있다.
| 유형 | 설명 | 예시 |
| One-to-One | 하나의 입력을 받아 하나의 출력을 산출한다. | 예: [키, 몸무게, 나이] 등의 데이터를 바탕으로 혈압을 예측하는 태스크 |
| One-to-Many | 하나의 입력에서 여러 개의 출력을 생성한다. | 예: 이미지 캡셔닝 - 하나의 이미지를 입력으로 받아 설명 문장을 생성 |
| Many-to-One | 여러 입력을 받아 하나의 출력을 산출한다. | 예: 감성 분석 - 문장 전체를 입력으로 받아 긍/부정 레이블을 분류 |
| Many-to-Many | 여러 입력을 받아 여러 출력을 생성한다. 입력 전체를 처리한 후 결과를 출력한다. | 예: 기계 번역 - 한 언어의 문장을 읽고 번역된 문장을 출력 |
| Many-to-Many | 각 타임스텝마다 입력과 출력을 동시에 생성한다. | 예: 비디오 프레임별 분석이나 단어의 품사 태깅(POS 태깅) |
[Character-Level Language Model]
1. 개요
Character-level language model은 언어 모델의 한 유형으로, 단어 단위가 아닌 문자 단위로 다음에 등장할 문자를 예측한다. 이 모델은 특히 철자 오류 수정, 텍스트 생성, 텍스트 유사도 분석 등 문자 수준에서의 세밀한 예측이 필요한 작업에 유리하다. 예를 들어, 'hello'라는 단어를 예측할 때, 첫 번째로 주어진 문자 'h'에 이어 다음 문자로 'e'를 예측하고, 이 다음에는 'l'을 예측하는 식으로 진행된다.
2. Character-Level Language Model의 작동 방식
Character-level language model은 RNN(Recurrent Neural Network) 구조를 사용하여, 각 문자마다 이전 문자들을 기반으로 hidden state를 갱신하면서 다음 문자를 예측한다. 이때 타임스텝별로 hidden state가 업데이트되면서 문맥 정보를 누적하고, 각 문자에 대한 확률 분포를 산출하여 가장 가능성이 높은 다음 문자를 예측한다.
예시: "hello" 예측 과정
- 첫 문자 'h' 입력: 모델은 첫 번째 문자 'h'를 입력받아 해당 hidden state를 생성한다.
- 다음 문자 예측: 현재 hidden state를 바탕으로 다음 문자 'e'에 대한 확률을 계산하여 예측한다.
- 반복 갱신: 이후 문자 'e'를 입력하여 다시 hidden state를 갱신하고, 다음 문자 'l'을 예측합니다. 이 과정을 반복하여 단어가 끝날 때까지 모든 문자를 예측한다.
이와 같이 RNN 기반의 character-level language model은 입력 문자가 순서대로 들어올 때마다 hidden state를 갱신하며 문맥 정보를 쌓아 나간다.
3. Character-Level Language Model의 구성 요소
(1) Hidden State
각 타임스텝 t에서 hidden state h_t는 이전 상태와 현재 입력 문자의 결합을 통해 계산된다. 이는 모델이 이전 문자들을 기반으로 새로운 문자를 예측할 수 있도록 맥락 정보를 저장하는 역할을 한다. Character-level 모델의 경우, 이러한 hidden state는 문맥을 유지하여 각 문자 예측이 자연스럽게 이어지도록 한다.
(2) Output Layer와 Logit
각 타임스텝에서 RNN의 hidden state를 통해 출력층(Output Layer)에서 다음 문자의 예측을 위한 logits을 생성한다. Logit은 해당 타임스텝에서 유니크한 문자 집합의 각 문자에 대한 점수로, 각 문자가 다음에 등장할 확률을 나타낸다.
Softmax와 One-Hot Encoding
출력층에서 나온 logits는 softmax 함수를 거쳐 확률 값으로 변환된다. softmax 함수를 통과하면, 유니크한 문자 개수만큼의 확률 값이 도출되며, 이 확률 값이 가장 높은 문자가 다음 문자로 예측된다. 이 확률 벡터는 최종적으로 one-hot 벡터 형태로 나타나며, 각 문자에 대한 예측값으로 사용된다.
[RNN의 학습 방법 및 Gradient 문제]
1. RNN의 학습 방법: Truncation과 BPTT
RNN(Recurrent Neural Network)은 시간에 따라 순차적으로 입력되는 데이터의 특성을 학습하기 위해 forward propagation과 backward propagation을 사용한다. 그러나 시퀀스가 길어질수록 학습 리소스가 증가하고, 메모리 제약에 따라 모든 시퀀스를 학습하기 어려운 상황이 발생한다. 이를 해결하기 위해 Truncation 기법을 사용하여 시퀀스를 일정 길이로 잘라 학습한다.
BPTT (Backpropagation Through Time)
RNN에서의 학습은 BPTT를 통해 이루어진다. BPTT는 일반적인 backward propagation을 시간축으로 확장한 형태로, 각 타임스텝에서 계산된 weight를 이전 타임스텝의 정보와 연결하여 학습하는 방식이다. 이 과정에서 가중치 W를 미분한 gradient를 통해 모델이 학습한다. 타임스텝마다 이 과정이 반복되며, RNN은 시퀀스의 시간적 패턴을 점진적으로 학습한다.
2. Gradient Vanishing 및 Exploding 문제
Vanishing 및 Exploding Gradient 문제 개요
RNN에서 긴 시퀀스를 학습할 때 흔히 발생하는 문제로, gradient가 전파되는 과정에서 소멸하거나(Gradient Vanishing) 폭발(Gradient Exploding)하는 현상이 있다.
문제 원인: Chain Rule
이 문제는 Chain Rule에 의해 발생한다. Chain Rule은 시간에 따라 이전 단계의 gradient에 계속 곱셈이 이루어지기 때문에, 특정 조건에서 값이 기하급수적으로 작아지거나 커질 수 있다. W의 값이 1보다 작으면 gradient가 점점 작아지고, 1보다 크면 커져서 Vanishing 또는 Exploding 문제가 발생한다.
Vanishing Gradient
- Gradient가 1보다 작은 값이 반복 곱해지면, 기하급수적으로 작아져 결국 0에 수렴하게 된다. 이로 인해 모델은 초기에 입력된 정보를 잃게 되어, 긴 시퀀스에서 중요한 패턴을 학습하기 어려워진다.
Exploding Gradient
- 반대로, Gradient가 1보다 큰 값이 반복 곱해지면 기하급수적으로 커져, 모델의 학습이 불안정해지고 과대적합을 일으킬 수 있다.
3. Long-Term Dependency와 LSTM의 도입
Vanishing/Exploding Gradient 문제는 RNN의 장기 의존성(Long-Term Dependency)을 효과적으로 학습하기 어렵게 만든다. Vanilla RNN 구조에서는 이러한 문제가 심각하여 멀리 떨어진 시퀀스 간의 상관관계를 학습하기 어려워진다. 이를 해결하기 위해 LSTM(Long Short-Term Memory) 모델이 도입되었으며, LSTM은 Gradient 문제를 완화하여 RNN의 장기 의존성 문제를 해결하는 데 도움을 준다.
1. 자연어 처리 활용 분야와 트렌드
- 자연어 처리(NLP)란 무엇인가?
NLP는 인간 언어를 컴퓨터가 이해하고 생성할 수 있도록 하는 기술이다. 사람의 언어는 굉장히 복잡하고 문맥에 의존적이기 때문에 이를 컴퓨터가 이해하는 것은 어려운 과제이다. 최근에는 딥러닝과 대규모 데이터의 발전으로 NLP가 크게 진보하고 있다. - 주요 활용 분야
- 정보 검색(Information Retrieval): 구글이나 네이버 같은 검색 엔진에서 사용자가 입력한 검색어에 적합한 웹페이지를 찾는 것이다. NLP는 검색어의 의미를 이해하고 유사한 문서들을 찾아내는 데 사용된다.
- 텍스트 마이닝(Text Mining): 방대한 양의 텍스트에서 유의미한 정보를 추출해내는 과정이다. 예를 들어, 고객 리뷰나 뉴스에서 특정 주제나 감정을 파악해 인사이트를 제공하는데 사용된다.
- 기계 번역(Machine Translation): 영어 텍스트를 한국어로 변환하거나 그 반대로 번역하는 작업이다. 구글 번역이나 파파고 등이 이러한 기술을 활용하며, 기계 번역은 기존의 규칙 기반에서 점차 신경망 기반으로 진화하여 자연스러워지고 있는 추세이다.
- 감성 분석(Sentiment Analysis): 리뷰, 트윗, 블로그 글 등의 텍스트에서 사람들의 감정(긍정적, 부정적)을 파악한다. 기업은 이를 통해 제품에 대한 고객 반응을 분석할 수 있다.
- 질의응답 시스템(Question Answering): 사용자의 질문에 가장 적합한 답을 찾아주는 기술로, 고객 지원 챗봇에 많이 사용된다.
- 대화형 에이전트(챗봇 및 음성 비서): 고객과의 상호작용을 통해 서비스를 제공하며, 일상적인 대화나 정보 제공 기능까지도 수행한다. 그 예로, 애플의 Siri나 구글 어시스턴트 등이 있다.
- 기술 트렌드:
- 딥러닝 및 대규모 사전 학습 모델: 과거의 NLP는 규칙 기반, 통계 기반으로 처리했지만, 이제는 대규모 데이터와 강력한 딥러닝 모델을 통해 NLP가 수행된다. 특히, 사전 학습된 Transformer 모델(BERT, GPT 시리즈 등)은 특정 태스크에 맞춰 추가 학습하지 않고도 높은 성능을 보여준다.
- Transformer 모델의 도입: 2017년의 "Attention is All You Need" 논문에서 제안된 Transformer 구조는 기존의 RNN 계열 모델이 다루지 못했던 긴 문맥을 효과적으로 처리할 수 있는 Self-Attention 메커니즘을 제공한다. 이를 통해 BERT, GPT와 같은 모델들이 다양한 NLP 작업에서 놀라운 성능을 보여주고 있다.
2. 기존의 자연어 처리 기법
- 규칙 기반 접근법: NLP의 초기 모델들은 언어학적 규칙과 문법을 기반으로 했다. 예를 들어, 특정 구문이나 단어 패턴을 감지해 이를 처리했지만, 인간 언어는 예외가 많고 복잡하기 때문에 실제 응용에서의 한계가 많았다.
- 통계 기반 접근법: 이후에는 확률을 사용하는 통계적 모델이 등장했다. N-그램 모델은 특정 단어가 이어질 확률을 바탕으로 다음 단어를 예측하는 방식이다. 예를 들어, "오늘 날씨가" 다음에 나올 확률이 높은 단어를 찾는 방식이다. 그러나 문맥이 길어지면 유효한 단어 예측이 어려워진다는 점이 있다.
- HMM (Hidden Markov Model): HMM은 단어의 순서를 모델링하여 주어진 문장에서 단어가 나타날 확률을 계산한다. HMM은 특정 상태에 기반하여 다음 상태로 전환되는 확률을 예측하지만, 단순한 확률만으로 복잡한 문장을 이해하기에는 한계가 있다.
- 딥러닝 기반 기법:
- RNN (Recurrent Neural Network): RNN은 연속적인 데이터에서 이전 상태의 출력을 다음 상태로 전달하여 문맥을 유지할 수 있다. 그러나 긴 문장에서 정보가 소실되거나 왜곡되는 기울기 소실 문제가 발생하여 완벽히 문맥을 반영하기 어렵다.
- LSTM (Long Short-Term Memory)과 GRU (Gated Recurrent Unit): RNN의 한계를 보완하기 위해 설계된 모델들로, 기억 셀과 게이트 구조를 통해 필요한 정보를 유지하고 불필요한 정보를 버릴 수 있다. 이를 통해 더 긴 문맥을 처리할 수 있지만, 여전히 트랜스포머 모델에 비해 병렬화가 어렵다는 단점이 있다.
3. Word Embedding (1) - Word2Vec
- Word Embedding 개요: 전통적인 NLP 모델에서는 단어를 고유한 인덱스로만 처리했지만, 이는 단어 간 의미 관계를 반영하지 못했었다. Word Embedding은 각 단어를 벡터로 변환하여 단어 간 유사성을 수치화할 수 있다. 즉, 의미가 유사한 단어들은 벡터 공간에서도 가까운 거리에 위치하게 된다.
- Word2Vec: Word2Vec은 단어 벡터를 학습하는 대표적인 모델로, 주어진 중심 단어와 주변 단어를 바탕으로 단어 간 관계를 학습한다.
- Skip-gram 모델: 중심 단어를 바탕으로 주변 단어들을 예측하는 방식이다. 예를 들어, "고양이가"라는 단어가 중심이라면 주변 단어인 "귀엽다"나 "운다"를 예측하는 방식이다. 이 모델은 큰 데이터셋에서 단어 간 의미 관계를 잘 학습한다.
- CBOW (Continuous Bag of Words) 모델: 주변 단어를 통해 중심 단어를 예측하는 방식이다. 여러 주변 단어들이 중심 단어에 대한 정보를 제공하므로 효율적이다. CBOW는 작은 데이터셋에서 더 빠르게 학습할 수 있다.
- Word2Vec의 특징: Word2Vec은 의미적 유사성을 벡터 산술로 표현할 수 있게 한다. 예를 들어, "King - Man + Woman = Queen"이라는 벡터 연산이 가능하여 단어 간의 관계를 시각적으로 이해할 수 있다.
4. Word Embedding (2) - GloVe
- GloVe (Global Vectors for Word Representation): GloVe는 단어 벡터를 학습하기 위해 전역적인 통계 정보를 활용한다. Word2Vec이 각 문맥에서 주변 단어와의 관계에 집중한다면, GloVe는 코퍼스 전체에서 단어 간 동시 출현 빈도를 고려한다.
- GloVe의 원리:
- 단어 벡터 간의 유사성을 수치화할 때 동시 출현 빈도를 기반으로 둔다. 예를 들어, "고양이"와 "애완동물"은 함께 자주 등장하므로 이 둘의 벡터는 가까운 거리에 위치하게 된다. 반대로, "고양이"와 "음악"은 거의 같이 등장하지 않으므로 먼 거리에 위치하게 된다.
- GloVe는 단어 간 관계를 표현할 때 전체 코퍼스의 통계 정보를 반영하여, 단어 사이의 관계와 유사성을 잘 포착한다.
- Word2Vec과의 차이점:
- Word2Vec은 로컬 문맥에서 의미를 학습하는 반면, GloVe는 코퍼스 전체의 통계적 특성을 반영하여 단어 벡터를 학습한다. 이 때문에 GloVe는 전체적인 단어 분포를 더 잘 반영하는 경향이 있다.
- GloVe는 수학적으로 더 해석하기 쉬운 구조를 가지며, 특히 단어 간의 의미적 유사성과 유추 문제에서 성능이 뛰어나다. 예를 들어, GloVe 벡터에서도 "King - Man + Woman = Queen"과 같은 의미적 연산이 가능해진다.
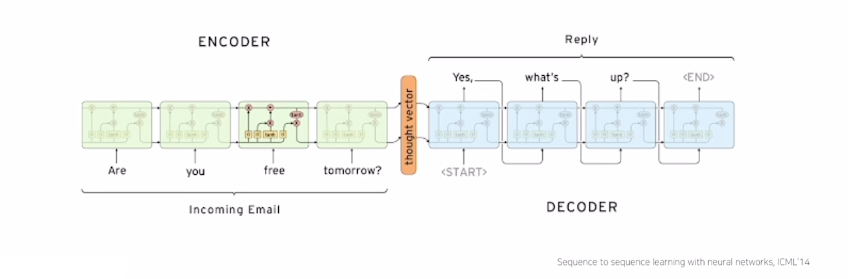
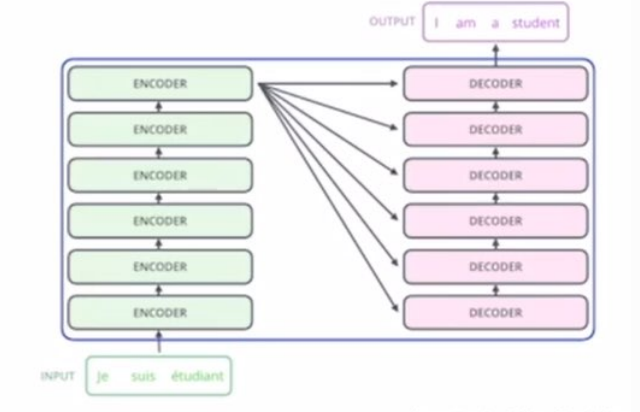
Seq2seq model
- 앞서 배운 RNN 구조에서 입력 및 출력이 모두 sequence인 many to many에 해당한다.
- 단어들의 sequence를 받아 한번에 출력값을 생성하기 때문에 챗봇과 기계번역에 많이 쓰인다.
seq2seq model은 입력문장(단어)인 encoder와 출력문장인 decoder로 이루어져 있다.
- encoder (문장 입력)
thought vector: 모든 입력 문장을 하나로 압축하여 (hidden state) vector를 만든다. 이때 LSTM 모델을 채용한다.
이후 thought vector는 decoder의 첫번째 입력으로 주어져 output 단어를 순차적으로 출력한다.
- decoder (단어 예측 & 출력)
- Start of Sentence (SoS): <Start> 토큰 같은 특수문자를 가장 처음 decoder time step에 넣어 첫 단어 예측
- End of Sentence (EoS): 마지막 <End> token이 생성되면 더 이상 단어를 출력하지 않음
디코더는 <SoS>가 입력되면, 넘어온 thought vector를 이용하여 다음에 등장할 확률이 높은 단어를 예측 → RNN은 첫 번째 단어를 예측하고, 다음 time step의 입력으로 넣음 → EoS가 나오기 전까지 반복 → EoS 나오면 중단
단점 존재
인코더 마지막 히든 스테이트(hidden state)에 모든 인코더 정보를 우겨넣게 되기 때문에 마지막 decoder time step에서의 hidden state vector는 앞에 입력한 단어들에 대해 정보의 손실이 발생한다.
이에 대한 편법으로 input값의 순서를 뒤바꿔 인코더의 입력으로 넣기도 했다.
ex. I love you → you love I
해결방안: Attention
이러한 단점에 대한 해결방안으로 Attention 알고리즘이 등장하게 되었다.
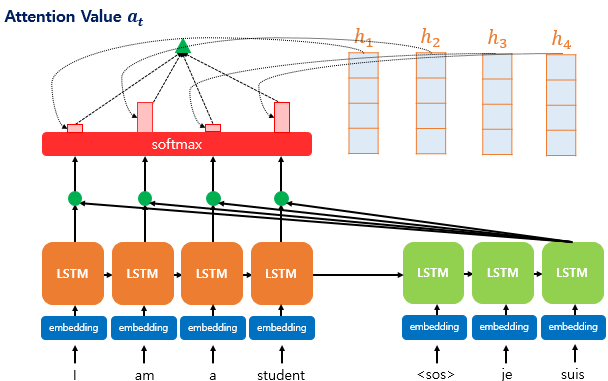
Attention 알고리즘: 디코더에서 출력 단어를 예측하는 time step마다 예측해야 할 단어와 연관이 있는 단어들에게 가중치를 부여하여 다시 한번 참고하는 알고리즘
Attention score: 각 encoder step에서 hidden state vector를 생성 후, 디코더의 각 time step에서 단어를 예측하기 위해 인코더의 모든 은닉 상태가 디코더의 현시점의 은닉 상태 (h)와 얼마나 유사한지를 판단하는 값. decoder의 time step마다 encoder hidden state vector와의 유사도(내적)를 계산한 것이 attention score.
Attention vector: 위에서 계산 한 attention score를 softmax 에 통과시켜 생성한다. 각 encoder hidden state vector에 대한 가중평균이며, decoder hidden state vector와 attention output vector를 concat하여 다음 단어 예측의 input으로 사용
티쳐포싱(Teacher forcing)
LSTM 모델의 특성상 특정 decoder time step에서 잘못된 예측값을 다음 decoder time step 입력으로 넣을 경우, 그 이후 모든 decoder time step들이 꼬이게 된다 → 심각한 오류 야기
Teacher forcing: 매 time step 마다 이전 decoder의 출력값이 아닌 ground-truth(정답)을 입력으로 넣는 방법
- 장점 : 디코더에서 추론(inference)할때, 틀린값이 입력값으로 들어가지 않으므로 학습이 빨라진다.
- 단점 : 주어진 데이터를 가지고 학습할때와, 실제 환경에서 테스트할때의 환경이 다르다.
(그러므로 학습에 초기에만 teacher forcing을 사용하고 어느 정도 정확도가 높아지면 다시 예측값을 넣어주는 방법을 사용한다.)
Luong Attention
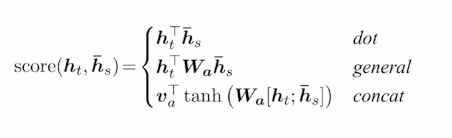
- Luong - dot : 간단한 내적을 통한 유사도(어텐션) 측정하는 기법으로, 학습가능한 파라미터가 존재하지는 않는다.
- Luong - general : 유사도를 구하고자하는 두 벡터 사이에, 학습가능한 파라미터로 구성된 행렬을 사용한다.
- Luong - concat : 유사도를 구하고자하는 두 벡터를 concat하여 선형변환(비선형성(선형변환(x)))으로 감싸서 계산을 진행한다.
Attention mechanism의 장점
- 성능 향상
Attention을 사용하면 각 타임스텝마다 입력 시퀀스에서 중요한 부분을 선택적으로 참조할 수 있어서, 번역과 같은 복잡한 자연어 처리 작업에서 성능이 크게 향상된다. 특히, 입력과 출력 간의 연관성이 복잡하거나 변동이 심한 경우에 유리하다. - Bottleneck 문제 완화
일반적인 Seq2Seq 모델에서는 인코더가 입력 문장의 전체 정보를 고정된 크기의 thought/context 벡터 하나에 압축해서 디코더로 넘기기 때문에, 문장이 길어질수록 정보가 손실되는 문제가 발생했다. 이를 bottleneck 문제라고 하는데, attention mechanism은 디코더가 인코더의 출력 벡터 전체를 대상으로 필요한 정보를 가중치로 조절해서 가져올 수 있게 하여, 이 문제를 효과적으로 완화해 줌. - Gradient Vanishing 문제 완화
Attention Mechanism을 사용하면, 디코더가 인코더의 모든 타임스텝을 참조할 수 있어, 멀리 있는 단어들의 정보도 효과적으로 사용할 수 있다. 이는 특히 RNN 기반 Seq2Seq 모델에서 오차역전파 과정에서의 gradient vanishing 문제를 완화하는 데 도움이 된다. 이는 역전파 과정이 attention 구조를 통해 한번에 역전파 되기 때문이다.
Decoding 출력값 생성 기법
1. Greedy decoding
매 decoding time step에서 순차적으로 실행하며, 예측 단어들 중 가장 높은 확률을 가지는 단어를 택해 decoding을 진행한다. 다시 말해, time step 현시점에서 가장 좋아 보이는 단어를 그때그때 선택하여 최적의 score 선택하는 방식이다.
문제점 - 만약, 단어를 잘못 생성했다면? 최적의 예측값을 생성해 낼 수 없다.
2. Exhaustive search
가능한 모든 경우의 수를 탐색하여 가장 높은 확률을 갖는 시퀀스를 찾는 방식
- 단어를 하나씩 생성하여 확률값 순차적으로 곱함

y: 출력
x: 입력
P(y_1|x): y_1에 대한 확률값
위 식을 통해 가능한 모든 경우의 수를 따진다. 단, 시퀀스 길이가 t일때 고를 수 있는 단어의 가짓수 v의 t승이 되는데, 시퀀스 길이가 커질 수록 계산량이 매우 크기 때문에 실시간 처리에는 비효율적이다.
3. Beam Search
위에서 설명한 Greedy decoding과 Exhaustive search를 조합한 차선책으로, 매 time step 마다 정해놓은 k개의 가짓수 (경우의 수) 만을 고려한다.
여기서 k (beam size)는 보통 5~10의 값 선택하며, 현 타임 스텝을 기준으로 <Start> 토큰 이후 등장한 단어들을 점수 순으로 나열하여 가장 높은 k개의 후보들만 생존시킨다.
여기서 score를 계산하는 방법은 다음 식과 같다:

각 time step 마다 log 확률을 사용하여 누적된 확률을 계산하는데, log 값이 단조 증가하므로 확률값이 커질수록 log 값이 커져 큰 가설이 유지
모든 탐색을 진행한 후 가설들 중 가장 스코어가 높은 값을 최종 결과물의 예측값으로 선정한다. 단, 문장이 짧을 수록 더 높은 스코어가 나오기 때문에, 타임 스텝의 개수로 최종 스코어를 나눠준다:
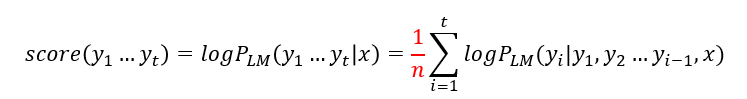
이처럼 Beam Search 방식은 생성하는 속도와 성능을 고려한 위 두 메서드의 중간책이라고 볼 수 있다.
자연어 처리 태스크의 평가지표
Precision, Recall, F-measure
- Precision (정밀도): 예측한 결과 중에서 실제로 맞는 비율을 나타낸다. (맞은 단어의 수 / 예측한 문장의 길이)
- Recall (재현율): 관련 있는 것으로 분류된 항목들 중 실제 검색된 항목들의 비율을 나타낸다.(맞은 단어의 수 / 정답 문장의 길이)
- F-measure (F1 점수): Precision과 Recall의 조화평균. F1 = 2 * (Precision * Recall) / (Precision + Recall)
평균 방식
- 산술평균: 모든 값의 단순 합을 값의 수로 나누는 방식
- 기하평균: 값들의 곱의 루트를 취하는 방식이다. Precision과 Recall의 기하평균으로 F-measure를 구하는 방법도 있다.
- 조화평균: 주로 Precision과 Recall처럼 두 값이 균형을 이룰 때 성능을 평가할 수 있어. 조화평균은 큰 값보다 작은 값에 더 민감하게 반응하여, 둘 중 하나가 낮으면 평균도 낮아지기 때문에 균형을 강조하는 평가에 사용된다.
모든 경우에서 산술평균 >= 기하평균 >= 조화평균 의 값을 가진다.
N-gram
N-gram은 NLP에서 주어진 텍스트를 단어나 문자 단위로 N개씩 나누는 방식이다.
예) "I am happy"라는 문장에서 2-gram(바이그램)은 "I am", "am happy"
N-gram은 특히 문장 내에서 단어나 구의 연속적인 패턴을 찾을 때 유용하며, 자연어 생성, 기계 번역, 텍스트 마이닝 등에서 문장의 유창함을 평가할 때 쓰인다.
BLEU (Bilingual Evaluation Understudy)
BLEU는 주로 기계 번역의 품질을 평가하는 지표로, 생성된 문장과 정답 문장 사이의 유사도를 N-gram을 기반으로 측정한다.
N-gram Precision: 생성된 문장과 기준(reference) 문장에서 일치하는 N-gram의 개수를 세어 유사도를 계산해. 예를 들어, 1-gram, 2-gram, 3-gram 등의 precision을 각각 구할 수 있다.
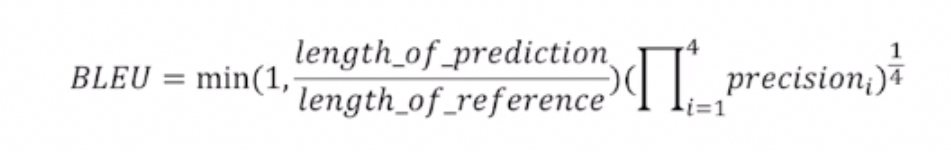
Brevity Penalty (길이 패널티): BLEU는 예측 문장이 너무 짧아도 높은 점수를 줄 가능성이 있어, 예측 문장이 기준 문장보다 짧으면 패널티를 준다. 길이 패널티는 BP = e^(1 - r/c)로 계산하는데, 여기서 r은 기준 문장의 길이, c는 예측 문장의 길이를 뜻한다. 예측 문장이 짧으면 BP < 1이 되고, 점수에 페널티를 준다.
BLEU Score: 최종적으로 여러 N-gram의 Precision을 기하평균으로 구하고, 길이 패널티를 곱해서 최종 점수를 계산함. BLEU 점수는 0부터 1 사이의 값으로, 높을수록 번역 품질이 좋음을 의미한다.
* 단어들의 일치도가 높을지라도 정답문장과 연속적으로 단어가 일치하지 않는다면 BLEU score값이 0이 나올 수도 있다. (단어 일치율이 높지만 순서가 맞지 않은 경우)
1. Transformer
▶ Transformer란?
Transformer는 Seq2seq 모델의 성능을 개선한 모델이다.
이전에는 'Seq2seq with Attention' 으로 기본 Attention 모델이 Seq2seq 모델에 추가옵션으로 사용되었지만, Transformer 모델에는 Attnetion 모델 자체가 주요 부분을 차지한다.
즉, 순수하게 Attention 모델만으로 sequence 데이터를 입력받고, 출력하는 구조를 Transformer 구조라고 한다.
장점은 총 2가지로 나눌 수 있다.
<장점>
1. self-attention 모델을 사용하여 입력 sequence에서 각 단어가 다른 단어들과 얼마나 관련이 있는지를 계산하여 문장 내 모든 단어들 간의 관계를 따질 수 있다.
2. Attention 만으로 시퀀스를 처리하여, 긴 문장 역시 잘 처리 할 수 있게 되었다.
▶ Long-Term-Dependency를 해결한 bi-directional RNN 모델
RNN은 타임스텝 수만큼 정보가 전달 되기 때문에, 멀리 있는 스텝까지 전달이 되는 과정에서 정보 유실을 겪을 수 있다.
이러한 문제를 Long-Term Dependency라고 부른다.
이를 해결하기 위해 bi-directional RNN과 Transformer가 해결책으로 등장하게 되었다.
우선 첫번째 해결책부터 알아보자.
결론적으로 말하자면 Bi-directional RNN은 Forward RNN과 Backward RNN를 결합해서 사용한다.
Forward RNN은 정보의 진행방향이 항상 왼쪽에서 오른쪽이므로 'I go home'이라는 문장이 있으면 I에는 go,home에 대한 정보는 담을 수 없다.
Backward RNN 은 정보의 진행방향이 오른쪽에서 왼쪽으로 흐른다.
Forward RNN 방식과는 다르게 별개의 RNN을 구현하게 되는데, 이 경우는 I도 go,home에 대한 정보를 가질 수 있다.
이처럼 Forward RNN과 Backward RNN을 병렬적으로 활용해 양쪽 방향으로도 정보를 포함할 수 있게 된다.
따라서, hidden state vector도 ht^f와 ht^b를 concat 해줌으로써 정보가 2배인 벡터를 가질수 있게 된다.

▶ Long-Term-Dependency를 해결한 Transformer 모델 구조 & 원리
1) 크게 바라본 Transformer 구조
우선 ,기존 Attention 모델과 비슷하게 Encoding 부분에서 생성되는 과정이긴 한데, 좀 더 유연하게 Attention 모델이 고안되었다.
크게 3가지로 나뉘는데, input vector, Attention 모듈, output(즉, encoding hidden state가 생성됨) 로 나뉜다.

기본 Attention 모델의 주요 원리를 정리해보자.
input vector 값을 기반으로 각 time step 별 encoder hidden state vector가 도출되고, decoder RNN 부분에서 각 time-step 별로 decoder hidden state vector와 encoder hidden state vector 값을 내적 하여 유사도를 구한다.
이렇게 구한 각각 내적값에 대해 softmax를 통과시켜 확률값으로 만들어 준 후, 다시 encoder hidden state vector에 가중평균의 원리로 계산을 하여 최종적으로 context vector를 얻었다.
다만, 여기서 문제점은 h1^d와 각 time-step별 encoder hidden state 벡터를 내적 할때, 자기 자신(즉,t=1 일때 encoder hidden state vector)과도 내적을 하게 되는데 다른 encoder hidden state vector와 내적을 할 때보다 값이 크게 나온다.
따라서, 이러한 문제점도 개선하여 'self-train Attention 모델'을 고안하였다.
self-Attention 모델은 입력 vector의 sequence 자체에서 Query,Key,value vector를 모두 생성하여, 하나의 입력 시퀀스 내에서 각 단어가 어떻게 관련 있는지 계산한다.
기존 attention 모델은 decoder와 encoder의 어느 부분에 주목할지 결정했지만, 이렇게 self-attention 모델을 고안함으로써 다른 단어와의 관계도 비교 할 수 있게 되었다.
2) 세부 원리
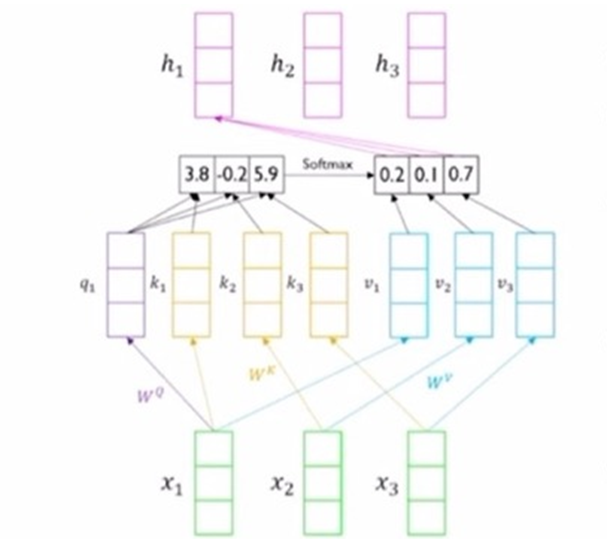
'I go home' 이라는 문장이 있을 때, I 에대한 h1 encoder hidden state vector를 도출 하고자 했다고 하자.
그러면 입력 vector 로부터 query, key, value vector를 모두 구할 수 있는데 그 기능은 아래와 같다.
1. Query vector
주어진 벡터에 대해 어느 벡터의 정보를 선별적으로 가져올지 기준이 되는 벡터이다.
즉, 현재 단어가 다른 단어들과 얼마나 관련있는지 알고자 할 때 사용한다.
EX) 'I'란 단어의 정보가 들어있는 x1이 선형 변환 matrix인 Wq 와 곱해져 query vector로 만들어짐
2. Key vector
내적을 통해 유사도가 계산되는, query 벡터와 내적이 되는 벡터이다.
즉, 각 단어가 가진 정보를 다른 단어들이 얼마나 중요하게 여기는지를 판단해준다.
EX) Key vector는 x1,x2,x3의 벡터 각각이 Wk matrix와 곱해져 생성된다. 추후, query vector와 내적을 통해 유사도를 계산하게 될것이다.
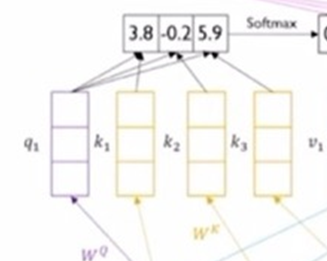
3. Value vector
가중평균을 구할 때 쓰이는 벡터이다.
최종적으로 모델이 참고하는 정보이고 query vector와 key vector의 내적 결과가 softmax 함수에 통과 된 후 나온 결과를 이 vector와 곱하게 된다.
각 value vector * softmax한 벡터들을 곱하면 h1 가중평균의 원리로 h1 encoding hidden state vector가 도출됨.
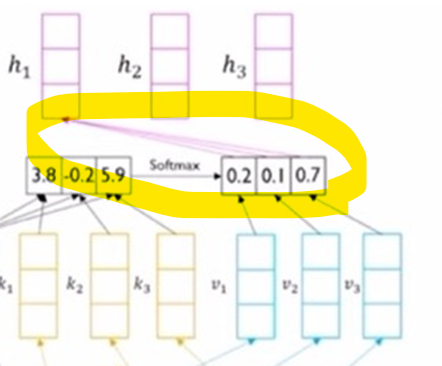
여기서 주의할 점은 주어진 x1,x2,x3 벡터가 query,key,value로 탈바꿈될 때 적용되는 선형변환 matrix가 Wq,Wk,Wv로 서로 각각 다르다.
즉, 주어진 같은 벡터 내에서도(x1이라고 하면) q1,k1,v1로 바뀔 때 적용되는 W matrix가 서로 다르다.
따라서, 하나의 입력 벡터로써 3가지 역할의 vector들이 도출된다.
query 벡터는 고정되었다고 해도 key와 value 벡터들은 갯수가 각각 동일해야한다.
이런 구조를 통해 각 단어에 대한 모든 단어들과의 관계를 적절히 담아 encoding hidden state vector를 얻을 수 있다.
2. Transformer 구조에서 내적을 하는 방식과 scaling을 해주는 이유
▶ Attention 모듈의 입력값과 그 함수
앞 과정을 보면 가중치는 Query vector와 Key vector 간의 내적값을 softmax 함수에 씌인후 계산된다.
query vector와 key vector는 내적 연산이 가능해야하기 때문아 dk로 같은 차원의 벡터를 갖는다.
value vector의 차원은 dv 라고 하는데 꼭 query vector와 key vector의 차원과 꼭 같지 않아도 된다.
이유는 value vector와 softmax 한 vector 를 곱하여 가중평균 계산을 하기 때문이다.
아래 공식은 Attention 모듈의 공식을 보여준다.

입력값으로는 하나의 query vector, key vector와 value vector pair 들의 집합이 들어간다.
이때, K와 V가 대문자인 이유는 각각의 row 벡터들을 합쳐놓은 행렬로 가정하기 때문이다
← I,go,home에 대한 key와 value vector들의 pair 쌍들의 집합
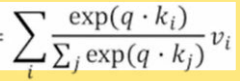
특히, 이부분은 value vector에 대한 가중평균을 구하는 공식이다.
즉, softmax를 통과한 값에 value vector들을 곱해준다.
먼저 분모에 들어가는 값을 살펴보자.
query vector와 key vector 각각 간의 exponontial 함수를 적용해 내적을 하는 과정이다.
→ (exponential function은 softmax 함수의 일종임)
분자에는 query와 1부터 i번째의 내적값을 순차적으로 계산하고 1번째 ~ i번째 value vector를 곱해준다.
이 과정을 큰 시그마를 씌어서 나타낸다.
▶ 세부 원리
일반 Attention은 단일 query vector 하나로써 계산을 하는데, 좀 더 유연하게 다음 공식을 수정할 수 있다.
단일한 query vector가 아닌 다수의 query vector로 이루어진 Q 행렬로서, query 벡터가 여러개 제시되었을 때 확장해서 행렬 연산을 수행할 수 있다.


이렇든 각 행렬들은 row vector들이 모여있는 matrix로 우선 정의가 된다.
1) Q*K^T 계산
위 파란색 네모처럼 Q를 3 by dk로, K의 Transpose 한 것을 dk by 4로 가정한다면, 다음과 같은 3 by 4 결과값의 matrix가 나오게 된다.
결국엔 row 1은 1번째 query 벡터와 각 key vector 와 내적한 값, row2는 2번째 query 벡터와 각 key vector 와 내적한 값, row3은 3번째 query 벡터와 각 key vector와 내적한 값이 된다.

2) softmax(Q*K^T)

그 이후 softmax를 씌어주는데, 각각의 row 벡터에 대해 softmax 연산을 수행하는 row-wise 연산을 한다. 그러면 이렇게 row 별 가중치를 담은 행렬이 나온다.
3) softmax(Q*K^T) * V
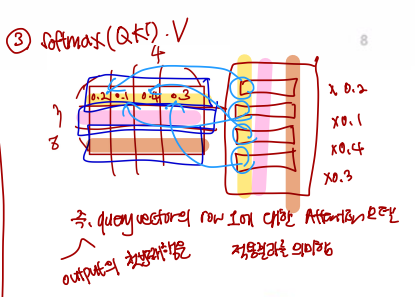
softmax 를 해서 구한 값과 value vector 들을 곱해주게 되는데, 결과값의 첫번째 행은 query vector 1에 대한 Attention 모델 적용 결과를 나타낸다.
▶ Scaling의 이유

다만, 저 식의 아래 부분을 보게 되면 보통 차원의 루트를 씌운 값을 나눠주고 softmax를 적용해준다.
이것을 scaling 이라고 하는데 그 이유는 dk가 커질 수록 내적 값도 증가하여 그 분산도 증가하게 되기 때문이다.
분산이 큰 경우 softmax의 확률 분포가 큰쪽에 몰릴 수 있다.
따라서, scaling 값으로 나눠주면 각 차원이 몇이든지 상관없이 분산이 항상 동일하게 유지되게 된다.
scaling 작업은 Attention 모델에서 꼭 필요한 작업이다.
1. Long-Term Dependency
- 문제점: 전통적인 RNN이나 LSTM과 같은 순환 신경망은 이전 시점의 정보를 다음 시점으로 전달하는 방식으로 작동한다. 이는 순차적으로 데이터를 처리하기 때문에, 문장이 길어질수록 초기 입력의 정보가 소실되거나 왜곡되는 기울기 소실 문제가 발생한다. 이를 Long-Term Dependency 문제라고 한다.
- Transformer의 해결 방법: 트랜스포머 모델에서는 RNN을 사용하지 않고 Self-Attention 메커니즘을 통해 이 문제를 해결한다. Self-Attention은 입력 문장의 모든 단어가 서로 어떤 관계를 갖고 있는지를 계산하는 방식으로 작동하여, 이전 단어에 대한 정보를 장거리에서도 쉽게 전달할 수 있다. 이 방식 덕분에 트랜스포머는 문장의 길이와 상관없이 문맥 정보를 효율적으로 학습할 수 있다.
2. Scaled Dot-Product Attention
- Self-Attention 기본 구조: Self-Attention은 Query (Q), Key (K), Value (V) 세 가지 벡터를 사용해 단어 간의 유사도를 계산한다.
- Query: 특정 단어가 다른 단어와 얼마나 관련이 있는지를 찾기 위해 사용된다.
- Key: 모든 단어가 갖는 특성을 표현하며, Query와 내적(dot product)하여 단어 간 유사도를 구합한다.
- Value: 최종적으로 단어에 대한 정보를 담는 벡터로, Query와 Key의 유사도를 계산하여 가중합된다.
- Dot-Product의 스케일링: Query와 Key 간의 유사도 계산은 벡터의 내적을 통해 이루어진다. 이때, 벡터 차원이 커질수록 내적의 값이 커지므로, 소프트맥스 함수의 출력이 치우칠 수 있다. 이를 방지하기 위해 벡터 차원의 제곱근으로 나눠 값을 스케일링한다.
- 계산 과정:
- Query와 Key의 내적을 계산하여 각 단어의 유사도를 구한다.
- 유사도를 스케일링하고, 소프트맥스(softmax) 함수를 적용하여 각 단어에 대한 가중치를 산출한다.
- 이 가중치를 Value 벡터에 곱해 최종 출력을 생성한다.
- 결과: Scaled Dot-Product Attention은 문장 내 각 단어가 서로에게 얼마나 주목해야 하는지를 결정한다. 이를 통해 단어 간 의미적 연결을 학습하고, 문맥을 반영하는 벡터를 생성하게 된다.
3. Multi-Head Attention
- 필요성: 한 번의 어텐션만으로는 문장의 다양한 의미적 관계를 충분히 표현하기 어렵다. Multi-Head Attention은 여러 개의 Self-Attention 헤드를 병렬로 적용해 단어 간 관계를 여러 관점에서 파악하도록 돕는다.
- 작동 방식:
- 입력 데이터는 여러 헤드(head)로 복사됩니다. 각 헤드는 고유의 가중치 행렬을 적용하여 입력을 다른 관점에서 변환한다.
- 각 헤드는 독립적으로 Scaled Dot-Product Attention을 수행하여 다양한 문맥 정보를 추출한다.
- 여러 헤드의 출력을 Concatenate (연결)하여 하나의 벡터로 결합하고, 최종 가중치 행렬을 곱하여 최종 출력을 생성한다.
- 장점:
- Multi-Head Attention을 통해 모델은 문장에서 여러 의미적 관계를 동시에 학습할 수 있다. 예를 들어, 한 헤드는 주어와 목적어의 관계를 포착하고, 다른 헤드는 형용사와 명사의 관계를 학습하는 방식이다.
- 이 방법을 통해 트랜스포머는 단어 간 복잡한 관계를 더욱 정교하게 학습하고, 긴 문장에서도 중요한 정보를 효과적으로 반영할 수 있다.