1조: 남유한, 오소민,임현우.최민슬
1. 주제
엑소브레인(Exobrain) 데이터셋을 활용한 글로벌 역사 및 대중 문화 MRC 모델 개발

※ 본 티스토리 프로젝트 내용은 ETRI API 인증을 받아 학습 목적으로 사용되었으며, 동아리 활동 중 MRC 프로젝트 학습을 위해 작성되었고, 상업적 용도로 사용되지 않음을 명확히 밝힘.
코딩 파일
2. 주제 선정 배경
선정한 엑소브레인 데이터셋은 한국의 역사와 문화뿐만 아니라 다양한 나라의 정보도 포함하고 있어, 글로벌 상식을 포괄하는 모델을 만들 수 있는 귀중한 자료였다. 따라서, 이 자료를 활용해서 글로벌화된 현대 사회에서 한국뿐만 아니라 전 세계 역사, 대중문화, 사회적 사건에 대한 포괄적이고 정확한 이해를 구현하는 MRC 모델을 구축하고자 했다. 엑소브레인 데이터셋을 활용하여, 다양한 문화적 배경을 아우르는 질의응답 시스템을 개발함으로써, MRC 모델을 직접 구현해보는 것에 의미를 두기로 했다.
3. 데이터 변환
데이터는 한국전자통신연구원(ETRI)에서 개발한 엑소브레인(Exobrain) 데이터셋을 활용하였다.
ETRI에서 제공한 데이터셋 중 엑소브레인 질문 및 검색결과를 활용했는데, " 에임 아담스의 스크린 데뷔 작은 무엇인가?", "히로시마 나가사키 원자 폭탄 투하가 일어난 것은 언제인가?" 와 같은 질문을 담고 있다.
다만, 부스트 코스에서 학습 한 코드를 이 데이터셋에 녹여내려고 하였으나, 데이터 형식이 맞지 않아 어려움을 겪었다. 그래서 SQuAD(Standford Question Answering Dataset) 형식으로 바꿔 데이터 변환을 진행하였다.


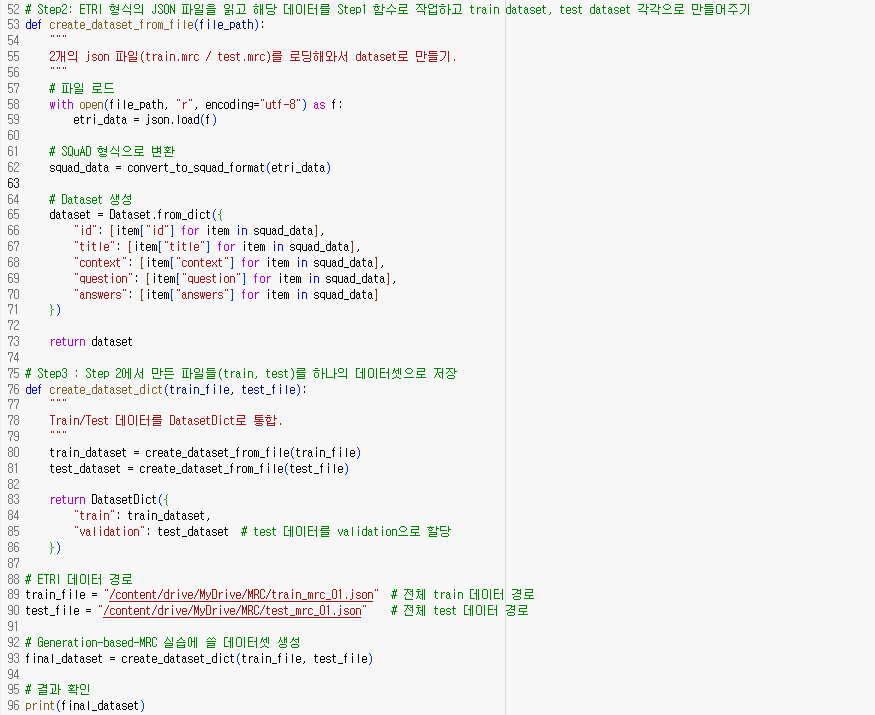
ETRI 데이터 형식은 다음과 같으며, 이를 SQuAD 형식으로 변환하는 작업을 진행하였다. 먼저, answer_start를 공백과 특수문자까지 포함하여 계산하는 단위로 변환하는 함수를 정의하였다. SQuAD 형식에서는 공백과 특수문자를 포함해 answer_start를 계산하지만, ETRI 형식은 이를 제외하고 한글 음절 단위로만 계산하였다. 따라서, 공백과 특수문자를 포함한 정확한 answer_start를 도출하는 과정을 추가하였다.
그 다음으로, ETRI 데이터를 SQuAD 형식으로 변환하는 함수를 정의했다. ETRI 형식의 JSON 파일을 변환하는 작업을 실행하고, 이를 각각 train_dataset과 test_dataset으로 분리하는 작업을 진행하였다. 마지막으로 이렇게 변환된 train과 test 데이터를 하나의 데이터셋으로 통합하여 저장하는 과정을 거쳤다. 이로써, 모델에 바로 적용할 수 있는 데이터 형식이 완성되었다.

4. 모델 구축 및 분석
데이터셋은 위의 데이터 변환을 거친 train,test 데이터를 사용하였고, MRC 모델로는 google에서 제공하는 mt5-small 모델을 사용하였다. MRC 방식으로는 Extraction-based model, Generation-based-model이 있는데, 우리조는 주어진 입력에 대해 정답을 포함한 새로운 문장을 만드는 Generation-based-model 방식을 차용하였다.
4-1 관련 패키지 설치 및 준비 ~ 4-2 Pretrained 모델 및 tokenizer 불러오기

관련 패키지로는 Huggingface_hub,Transformer,Protobuf,Evaluate 를 가져왔다.
차례대로 SQuAD 형식으로 변환한 datasets와 문장 단위로 토큰화 해주는 nltk의 punkt tokenizer를 불러왔다. evaluate에 들어있는 squad metric도 불러와주었다. Dataset 형식은 아래와 같다. train dataset에는 11010개 행이 있고, test dataset은 1326개 행이 존재했다.



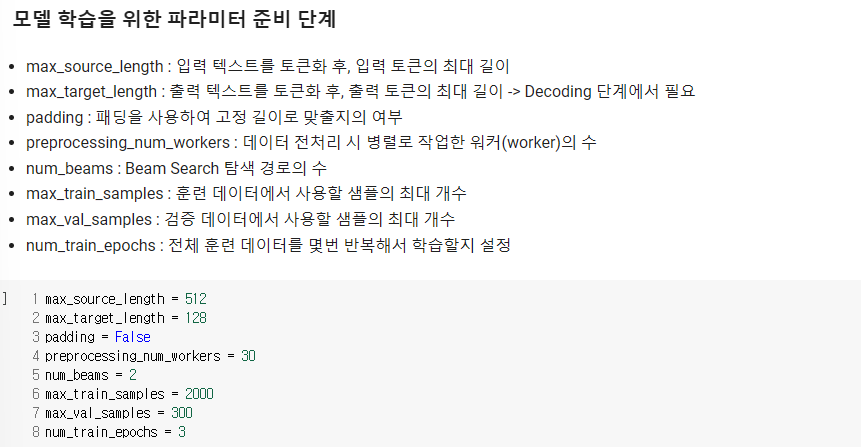
모델은 goggle에서 사용하는 mt5-small 모델을 가져왔으며, Pretrained 된 모델을 객체로 저장하는 작업을 실행하였다. 이 단계에서 모델 학습을 위한 파라미터 8가지도 정의해주었다.

4-3 데이터 전처리 단계
print(datasets['train'][0]){'id': 'etri_2604', 'title': '제2차 세계 대전 개요', 'context': '- 히로시마·나가사키 원자폭탄 투하 (1945년 8월 6일, 9일)', 'question': '히로시마 나가사키 원자폭탄 투하가 일어난 것은 언제인가?', 'answers': {'answer_start': [21], 'text': ['1945년']}}

4-4 모델 학습 및 검증 준비

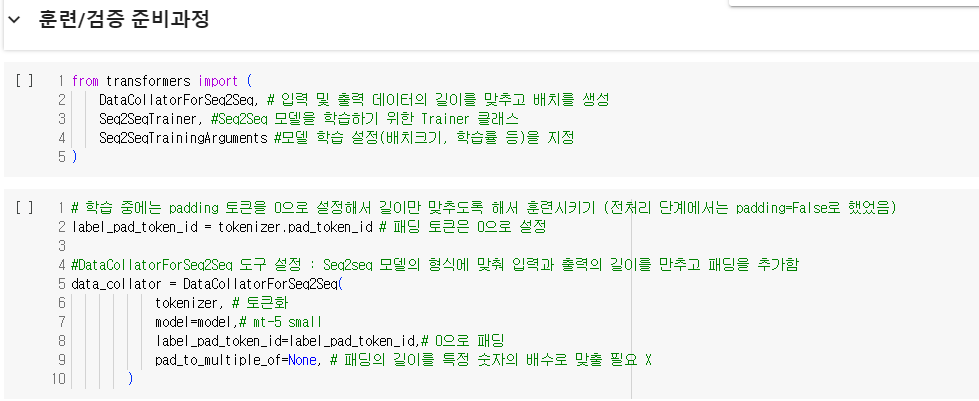

평가 metric로는 SQuaD metric를 가져왔다. 이 메트릭스는 EM과 F1 score이 지표로 사용된다.
EM 모델은 생성한 답변이 정답과 정확히 동일한 경우에만 점수를 부여하기 때문에 Generation-based-model에는 맞지 않는다. 따라서, F1 score을 기반으로 정확도를 평가해보려고 한다. 모델을 학습시키기 전에 compute_metrics라는 함수를 정의해주었다. 이함수는 모델의 예측값과 정답데이터를 decoding(해독)하여 SQuAD 평가 지표로 성능을 평가한다. 먼저,입력값으로는 모델이 생성한 예측값(preds)와 정답(labels)로 구성된다. 예측값이 튜플 형식일 경우, 첫번째 요소만 사용한다. 그다음 예측값(preds)와 정답(labels)를 decoding 하고 앞에서 정의한 postprocess_text 함수로 텍스트 후처리를 해준다. 결과값으로는 metrics 지표를 출력해준다.

4-5 학습, 검증, 평가 진행
학습/검증/평가에 필요한 설정은 다음과 같이 정의했다. 위에서 정의한 파라미터를 Seq2SeqTrainer에 넘겨주어 학습을 진행하였다. 실제 학습은 사이트에서 API 키를 받아와 실행하였다.



TrainOutput(global_step=750, training_loss=11.705498046875, metrics={'train_runtime': 202.2513, 'train_samples_per_second': 29.666, 'train_steps_per_second': 3.708, 'total_flos': 2169815235379200.0, 'train_loss': 11.705498046875, 'epoch': 3.0})Trainer의 훈련 정보를 뽑아본 결과, 총 750번의 업데이트를 수행하였으며 훈련 평균 손실값은 약 11.7054가 나왔다. 손실값이 이렇게 큰 이유는 훈련량이 부족한 거 일수도 있다. 훈련 시간은 총 202.25초가 걸렸으며 전체 데이터셋을 3번 반복하였다.
metrics도 돌려보고 결과를 뽑아보니, EM은 Extration-based-model이 아니므로 0이 나올 것을 예상하고 있었다. 다만, f1값이 약 1.13으로 점수가 매우 낮은 편임을 나타냈다. 이는 모델이 적절히 학습되지 않았거나 데이터셋이 너무 복잡했을 가능성이 높다.

{'eval_loss': 6.962640285491943, 'eval_exact_match': 0.0, 'eval_f1': 1.1349206349206349, 'eval_runtime': 8.2673, 'eval_samples_per_second': 36.287, 'eval_steps_per_second': 4.596, 'epoch': 3.0}
5. 학습 과정 중 오류 발생 → 이유가 무엇일까 (한계점)
[1] 라이브러리 호환성 문제 (해결함)
온라인 강의에서 사용된 학습 자료가 오래되어 최신 패키지와 호환되지 않는 문제가 발생하였다. 이를 해결하기 위해 아래와 같이 라이브러리를 최신 버전으로 재설치하는 과정을 거쳤다.
# 필요한 라이브러리
!pip uninstall -y datasets huggingface_hub transformers # 호환성 문제 때문에 삭제 했다가 다시 깜
!pip install datasets transformers huggingface_hub # 최신 버전으로 재설치
!pip install protobuf==3.20.3 # 데이터 직렬화/역직렬화
!pip install evaluate # 평가 metric 제공 지표
[2] 예측 값 출력 문제 (해결하지 못함)
모델의 train 과정은 진행되었으나, 질문에 대한 답에 해당하는 Decoded prediction 리스트의 결과값이 빈값으로 출력되는 것을 확인할 수 있었다.
Sample predictions vs Labels:
Prediction 0:
Lable 0: 리 군의 국소적 구조를 나타내는 대수 구조
Match: False
Prediction 1:
Lable 1: 오타와
Match: False
Prediction 2:
Lable 2: 하루나 아이
Match: False
...
이에 학습 및 테스트 데이터 부족이 원인이 아닐까 생각하였고, 기존(train 1000개, test 100개)의 10배로 데이터를 늘려서 해결하고자 하였다. 추가로 데이터가 증가함에 따라 GPU 용량이 초과되는 관계로 Colab Pro를 결제하여 진행하였다. 하지만 동일하게 비정상적으로 preditction과 metric 결과가 출력되었다.
[3] 원인 분석
모델이 답변을 정상적으로 출력하지 못하고 빈칸으로 채워진 결과가 반복되는 이유는 다음과 같이 예상해볼 수 있다.
1. 학습 데이터가 양적으로 늘어났지만, 질적 적합성이 낮았을 가능성
2. 학습률, 배치 크기 등의 하이퍼파라미터가 비효율적으로 설정되었거나, 적합하지 않은 값으로 지정되었을 가능성
3. 사용한 Pretrained model이 우리가 사용한 데이터와 도메인이 지나치게 달라 적응하지 못했을 가능성
4. tokenizer가 데이터를 잘못 처리했을 가능성
[4] 해결 방안 모색 추가 연구 방향성
우선 기본적으로 모델 Fine-tuning시 학습률, 배치 크기 등 하이퍼 파라미터를 적절하게 조정하여 시도하고, 학습 진행 중에 loss와 validation loss값을 추적하며 과정을 자세히 살펴보면 좋을 것 같다. pretrained model과 우리가 사용하고자 하는 데이터 간의 도메인 적합성을 확인하고, 필요에 따라 augmentation을 진행하면 데이터에 대한 모델의 적응력이 높아질 것이다. 또한 적절한 prediction 값이 출력된다면, metric 계산도 정상적으로 이루어질 것으로 예상한다.
6. 출처
[그림1]
출처: 송주상, 사람처럼 대화하는 AI 나올까? 구어체 언어분석 API 등장, Chosun, 2020.08.07, https://it.chosun.com/news/articleView.html?idxno=2020080603782
사람처럼 대화하는 AI 나올까? 구어체 언어분석 API 등장
한국전자통신연구원(ETRI)이 인공지능(AI)과 더 편하게 대화할 수 있는 한국어 기반 기술을 공개했다.언어 특화 인공지능(AI) ‘엑소브레인’의 구어체 언어분석 API다.공개된 기술은 문어체를 주
it.chosun.com
[데이터셋]
한국전자통신연구원_엑소브레인 QA Datasets 목록, 공공데이터포털,
https://www.data.go.kr/data/15094633/fileData.do
한국전자통신연구원_엑소브레인 QA Datasets 목록_20211115
한국어 분석 및 질의응답 기술을 개발하고 있는 엑소브레인 과제를 수행하면서 구축한 언어처리 학습데이터(엑소브레인 QA Datasets) 목록입니다. 다양한 지식산업 환경에서 전문가 수준의 질의응
www.data.go.kr
[MRC 강의]
https://www.boostcourse.org/ai333
딥러닝으로 만드는 질의응답 시스템 (MRC)
부스트코스 무료 강의
www.boostcourse.org