3조: 김도균 김예원 정원준
0. 분석 배경
https://dacon.io/competitions/official/235864/data 데이콘 [영화 리뷰 감성분석 AI해커톤]
1. 분석 목적
긍정 혹은 부정으로 분류되는 네이버 리뷰 데이터를 통해 영화 리뷰의 감성(긍정/부정)을 분류
2. 데이터 설명
(1) ratings_train.csv: 영화 리뷰 데이터
- id: 각 리뷰를 구분하는 고유 ID
- review: 영화 리뷰 텍스트
- label: 리뷰의 감성 라벨
- 0: 부정적 리뷰
- 1: 긍정적 리뷰
(네이버 영화 리뷰 데이터는 실제 네이버 영화에 사용자들이 남긴 리뷰를 가공한 데이터입니다.)
데이터 출처 : https://github.com/e9t
e9t - Overview
data hacker; loves geeks, smiling, learning, community action, people that see the bright side of things - e9t
github.com
3. 개념 공부
- Data Set
(1) Train set: 모델을 학습시키기 위한 data set
모델을 학습시키는 데에는 유일하게 train set만 이용한다!
(2) Validation set: 학습이 이미 완료된 모델의 성능을 검증하기 위한 data set
이 데이터로는 학습을 시키지 않는 데 유의
4. 코드 분석
(1) 데이터 불러오기



(2) Data Set 나누기

데이터셋을 훈련(train)과 검증(validation) 데이터셋으로 분할
기본적으로 75%는 train, 25%는 validation 데이터로 나눔

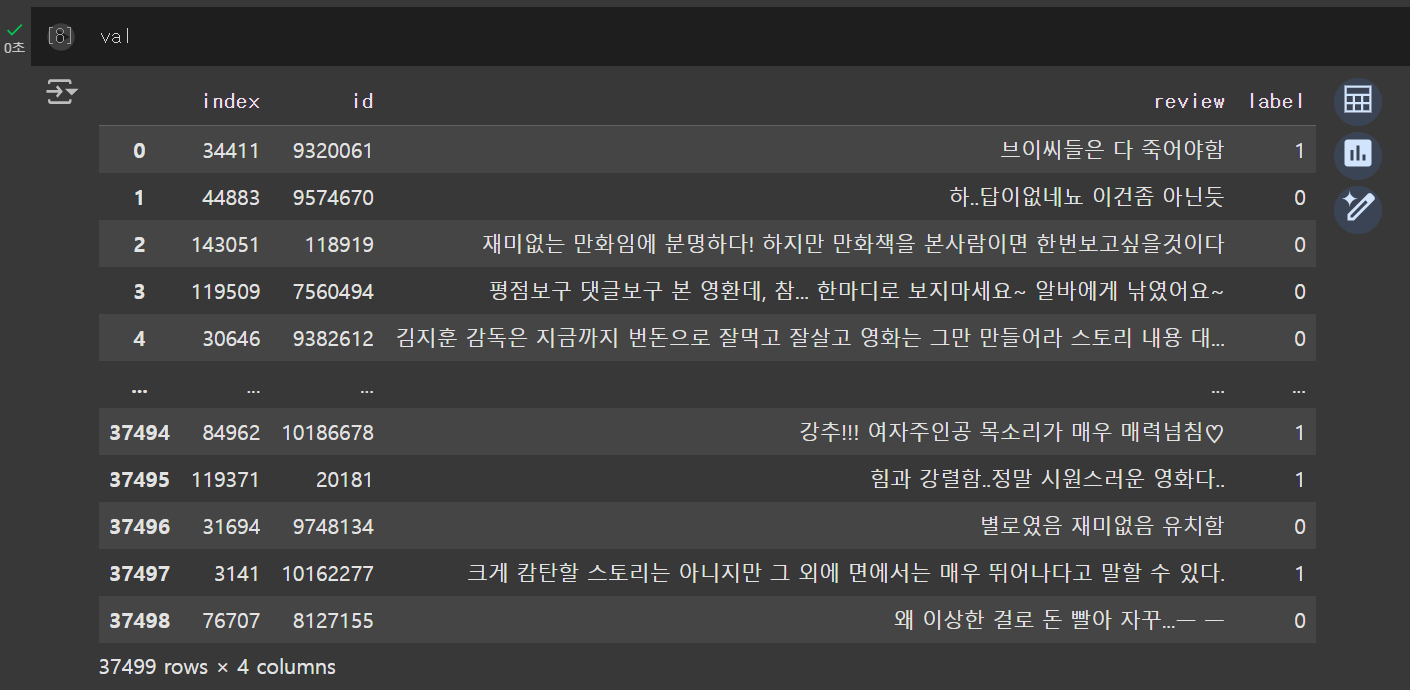
(3) 데이터 전처리
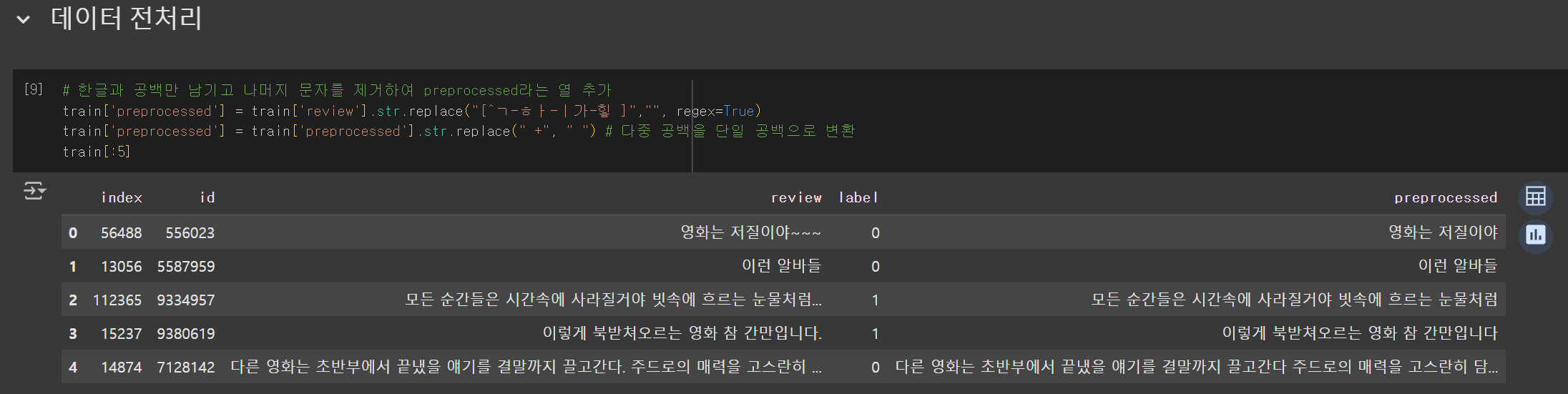
- 정규 표현식:
- [^ㄱ-ㅎㅏ-ㅣ가-힣 ]: 한글 자음, 모음, 완성형 한글 문자와 공백만 남김.
나머지 문자(숫자, 영문자, 특수기호)는 제거.
- [^ㄱ-ㅎㅏ-ㅣ가-힣 ]: 한글 자음, 모음, 완성형 한글 문자와 공백만 남김.
- 다중 공백 제거:
- " +" 패턴을 사용하여 연속된 공백을 단일 공백으로 변환.

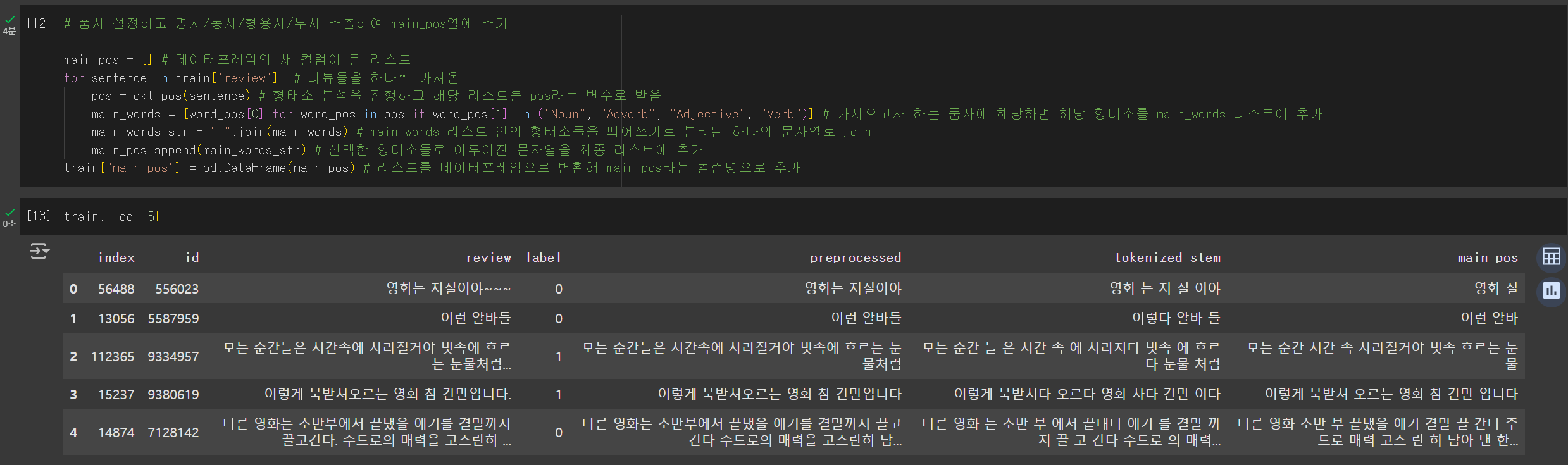
KoNLPy 라이브러리의 Okt 형태소 분석기를 사용하여 형태소 분석 및 어간 추출을 수행한 후, 결과를 데이터프레임에 추가

(4) 벡터화

(5) 모델 학습

로지스틱 회귀(Logistic Regression) 모델을 사용하여 학습
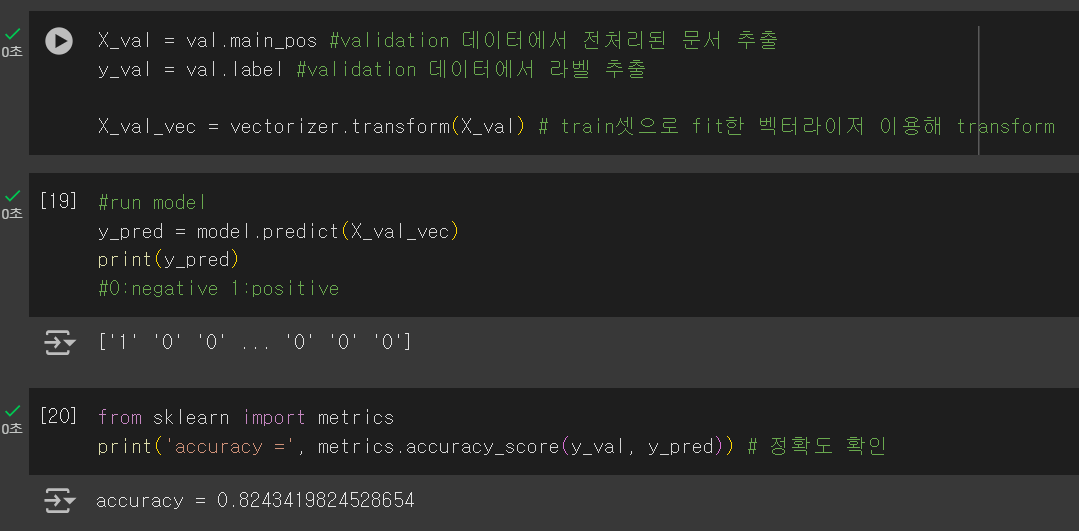
(6) 모델 성능 검증 (validation set 사용)

(7) test 셋에 모델 적용
test 셋이 txt 파일로 이루어져 있었기에, 이를 csv파일로 변환하고 위와 똑같은 전처리를 진행하여 모델을 학습시켰다.

그러나 정확도가 53%로 현저히 낮아진 모습이다.
(8) 정확도 높이기 위한 과정
다음과 같은 방법으로 피드백을 진행하였다.
(1) 학습 셋, 검증 셋 비율 조정 => 7.5:2.5 -> 7:3 -> 6:4
(2) 학습 column을 main_pos에서 tokenized_stem으로 변경
그러나 정확도는 유의미할 정도로 변화하지 않았다.