1.
import matplotlib.pyplot as plt: 그래프 그리기를 위한 matplotlib의 pyplot 모듈을 불러오고, 이를 plt로 지정합니다.
plt.rc('font', family='NanumBarunGothic'): plt의 글꼴을 'NanumBarunGothic'으로 설정합니다. 이는 한글 글꼴을 지정하는 것으로, 한글이 깨지는 것을 방지합니다.
plt.rcParams['axes.unicode_minus'] = False: plt의 글꼴에서 유니코드 마이너스 기호를 제거합니다. 이는 한글이 깨지는 것을 방지합니다.
from matplotlib import font_manager, rc: matplotlib의 글꼴 관련 모듈을 불러옵니다.
covid19_raw = pd.read_csv('/content/drive/MyDrive/python_code/code1/코로나바이러스감염증-19_확진환자_발생현황.csv', encoding = 'cp949'): 한글로 된 csv 파일을 불러옵니다. 파일 경로는 '/content/drive/MyDrive/python_code/code1/' 디렉토리 안에 있으며, 파일 이름은 '코로나바이러스감염현황_발생현황.csv'입니다. 파일은 'cp949'로 인코딩되어 있습니다.
모듈 또는 패키지 설명
pandas 데이터를 다루기 위한 패키지
numpy 수학적 계산을 위한 패키지
matplotlib.pyplot 그래프 그리기를 위한 패키지
font_manager, rc 그래프에 적용할 글꼴 관련 모듈
pd.read_csv() csv 파일을 불러오는 함수
plt.rc() matplotlib의 기본 설정을 변경하는 함수
plt.rcParams[] pyplot의 기본 설정을 변경하는 함수
2.
covid19_raw라는 변수에 할당된 데이터프레임의 정보를 출력하는 함수이다.
함수 호출 시 해당 데이터프레임의 각 컬럼에 대한 정보를 보여주며, 각 컬럼의 데이터 수, 결측치 여부, 데이터 타입 등을 확인할 수 있다. 이를 통해 데이터의 전반적인 구성과 결측치 여부 등을 파악할 수 있다.
3.
해당 코드는 Pandas DataFrame인 df에서 일자 컬럼에서 '2021'을 포함하는 값을 찾아 해당 행의 인덱스를 list_2021에 추가하는 코드입니다.
list_2021 = []: 빈 리스트를 만듭니다.
for i in range((len(df['일자']))): df['일자']의 길이만큼 반복합니다.
if '2021' in df['일자'][i]:: df['일자'][i]에 '2021'이 포함되어 있다면, 즉 해당 날짜가 2021년이면 아래 코드를 실행합니다.
list_2021.append(i): 해당 날짜가 2021년이라면, 해당 행의 인덱스 i를 list_2021에 추가합니다.
결과적으로 list_2021에는 df에서 '일자' 컬럼 값 중에서 2021년에 해당하는 행의 인덱스가 저장됩니다.
+ 22년도도 마찬가지
구분 설명
list_2021 = [] 빈 리스트 list_2021을 생성
for i in range((len(df['일자']))) df['일자']의 길이만큼 반복문을 실행
if '2021' in df['일자'][i]: df['일자']의 i번째 요소에 '2021'이 포함되어 있으면
list_2021.append(i) i 값을 list_2021 리스트에 추가
4.
해당 코드는 2021년과 2022년의 데이터만을 추출하는 과정이다. 먼저, 2021년과 2022년의 데이터의 인덱스를 추출한 후, 두 리스트를 합친다. 그 다음, loc() 함수를 사용하여 df 데이터프레임에서 2021년과 2022년에 해당하는 데이터만을 추출하여 df_21_22라는 새로운 데이터프레임으로 만든다. reset_index(drop=True)는 데이터프레임의 인덱스를 처음부터 다시 설정하는 것으로, drop=True를 하면 이전에 있던 인덱스는 버리고, 0부터 새로운 인덱스를 부여한다.
따라서, 해당 코드는 아래와 같이 정리할 수 있다.
코드 설명
list_21_22 = ... 2021년과 2022년의 데이터의 인덱스 리스트를 합친다.
df_21_22 = ... df 데이터프레임에서 2021년과 2022년에 해당하는 데이터만을 추출하여 df_21_22 데이터프레임을 만든다.
5.
df_21_22['일자'] = pd.to_datetime(df['일자']) '일자' 컬럼을 datetime 타입으로 변환하여 df_21_22 데이터프레임에 저장
df_pivot = df_21_22.pivot_table(index='일자',values = ['사망(명)']) df_21_22 데이터프레임에서 '일자'를 인덱스로, '사망(명)'을 값으로 하는 pivot_table 생성
df_pivot pivot_table을 반환하여 출력
6.
monthly_covid = df_pivot.resample('M').sum() 일자별로 정리된 데이터를 월별로 묶어 합계를 계산하여 새로운 데이터프레임으로 만든다.
데이터프레임 monthly_covid는 각 월별로 해당 월에 기록된 사망자 수의 합계를 보여준다.
7.
해당 코드는 matplotlib를 이용해 시계열 그래프를 그리는 코드입니다. 주요 내용은 다음과 같습니다.
monthly_covid의 컬럼명을 df_name에 저장합니다.
plt.figure()를 이용해 그래프의 크기를 설정합니다.
for문을 통해 monthly_covid에서 컬럼을 하나씩 가져와 각 컬럼에 해당하는 그래프를 그립니다.
plt.plot()을 이용해 데이터를 가져와 그래프를 그립니다.
plt.legend()를 이용해 범례를 표시합니다.
plt.title(), plt.xlabel(), plt.ylabel()를 이용해 각각 그래프의 제목과 x축, y축의 제목을 설정합니다.
plt.xticks()를 이용해 x축의 간격을 설정하고 글씨를 90도로 돌려 표시합니다.
1.
해당 코드는 covid19_raw라는 DataFrame에서 '전체'라는 부분 문자열을 포함하는 열(column)의 인덱스를 찾아 list_total이라는 리스트에 저장하는 역할을 합니다. 코드의 내용을 자세히 살펴보겠습니다.
list_total이라는 빈 리스트를 초기화합니다. 이 리스트는 '전체'라는 부분 문자열을 포함하는 열의 인덱스를 저장할 용도로 사용됩니다.
range() 함수를 사용하여 covid19_raw.columns의 길이에 대한 범위를 생성합니다. 이는 열의 인덱스를 순회하기 위한 범위를 생성하는 것입니다.
for 루프를 통해 각 열의 인덱스에 대해 순회합니다.
if 문을 사용하여 covid19_raw.columns[i]에서 '전체'라는 부분 문자열이 있는지 확인합니다.
만약 '전체'라는 부분 문자열이 포함되어 있다면, 해당 인덱스 i를 list_total에 추가합니다.
이렇게 하면 list_total에는 '전체'라는 부분 문자열을 포함하는 열의 인덱스가 모두 저장되게 됩니다.
2.
해당 코드는 '전체'가 포함된 컬럼을 리스트로 저장하고, 추가적으로 '자치구 기준일'이라는 컬럼을 리스트에 추가하는 역할을 합니다. 아래는 코드의 해석입니다:
covid19_raw.columns[list_total]을 통해 '전체'가 포함된 컬럼의 인덱스를 사용하여 해당 컬럼들의 이름을 추출합니다.
list() 함수를 사용하여 추출한 컬럼 이름들을 리스트로 변환합니다.
choose라는 리스트에 list() 함수로 변환한 컬럼 이름 리스트를 추가합니다.
.append() 메서드를 사용하여 '자치구 기준일'이라는 문자열을 choose 리스트에 추가합니다.
결과적으로, choose 리스트에는 '전체'가 포함된 컬럼의 이름과 '자치구 기준일'이라는 문자열이 저장됩니다.
3.
해당 코드는 choose 리스트에 해당하는 컬럼들을 covid19_raw DataFrame에서 추출하여 df_total이라는 새로운 DataFrame으로 저장하는 역할을 합니다. 아래는 코드의 해석입니다:
covid19_raw.loc[:, choose]를 사용하여 covid19_raw DataFrame에서 choose 리스트에 해당하는 컬럼들을 추출합니다.
loc 메서드는 행과 열을 라벨로 지정하여 DataFrame의 일부를 선택하는 데 사용됩니다.
:은 모든 행을 선택하고, , choose는 choose 리스트에 해당하는 컬럼들을 선택합니다.
추출한 결과를 df_total이라는 새로운 DataFrame으로 저장합니다.
결과적으로, df_total DataFrame에는 covid19_raw DataFrame에서 choose 리스트에 해당하는 컬럼들이 추출되어 저장됩니다. 이를 통해 원본 DataFrame에서 원하는 컬럼들로 이루어진 새로운 DataFrame을 생성할 수 있습니다.
4.
해당 코드는 df_total DataFrame의 '자치구 기준일' 컬럼에서 '2021'과 '2022'가 포함된 값의 인덱스를 list_2021과 list_2022에 저장하는 역할을 합니다. 아래는 코드의 해석입니다:
list_2021이라는 빈 리스트를 초기화합니다. 이 리스트는 '2021'이 포함된 값의 인덱스를 저장할 용도로 사용됩니다.
range() 함수를 사용하여 df_total['자치구 기준일']의 길이에 대한 범위를 생성합니다. 이는 '자치구 기준일' 컬럼의 인덱스를 순회하기 위한 범위를 생성하는 것입니다.
for 루프를 통해 각 인덱스 i에 대해 순회합니다.
if 문을 사용하여 df_total['자치구 기준일'][i]에서 '2021'이 포함되어 있는지 확인합니다.
만약 '2021'이 포함되어 있다면, 해당 인덱스 i를 list_2021에 추가합니다.
이후, 위의 과정을 '2022'에 대해서도 동일하게 수행하며, '2022'이 포함된 값의 인덱스를 list_2022에 저장합니다.
이렇게 하면 list_2021에는 '2021'이 포함된 값의 인덱스가 저장되고, list_2022에는 '2022'이 포함된 값의 인덱스가 저장됩니다.
5.
해당 코드는 list_2021과 list_2022의 합집합을 구하고, 이를 사용하여 df_total DataFrame에서 해당 인덱스에 해당하는 행들을 추출하여 df_21_22이라는 새로운 DataFrame으로 저장하는 역할을 합니다. 아래는 코드의 해석입니다:
list_2021과 list_2022를 합집합 연산자인 +를 사용하여 합칩니다. 이렇게 하면 '2021'과 '2022'가 포함된 값의 인덱스가 모두 포함된 리스트인 list_21_22가 생성됩니다.
df_total.loc[list_21_22,]를 사용하여 df_total DataFrame에서 list_21_22에 해당하는 행들을 추출합니다.
loc 메서드를 사용하여 특정 인덱스를 기반으로 DataFrame의 행을 선택할 수 있습니다.
list_21_22는 list_2021과 list_2022의 합집합으로, 해당 인덱스에 해당하는 행들이 선택됩니다.
, 뒤의 빈 슬라이싱은 모든 열을 선택하도록 합니다.
reset_index(drop=True)를 사용하여 추출한 행들의 인덱스를 재설정합니다.
reset_index() 메서드를 사용하여 인덱스를 재설정할 수 있습니다.
drop=True를 지정하여 이전 인덱스를 삭제하고 새로운 연속된 정수 인덱스를 생성합니다.
추출한 결과를 df_21_22이라는 새로운 DataFrame으로 저장합니다.
결과적으로, df_21_22 DataFrame에는 df_total DataFrame에서 '2021'과 '2022'가 포함된 값의 인덱스에 해당하는 행들이 추출되어 저장됩니다. 이를 통해 '2021'과 '2022'에 해당하는 데이터로 이루어진 새로운 DataFrame을 생성할 수 있습니다.
6.
choose 리스트에서 '자치구 기준일' 값을 제거합니다. 이는 '전체' 값을 column으로 활용하고자 '자치구 기준일' 값을 제외하기 위한 작업입니다.
df_21_22['자치구 기준일'] 열의 데이터 타입을 pd.to_datetime() 함수를 사용하여 날짜 형식으로 변환합니다.
pd.to_datetime() 함수는 날짜/시간 형식의 데이터를 Pandas의 DateTime 형식으로 변환하는데 사용됩니다.
이 경우 '자치구 기준일' 열의 값을 날짜 형식으로 변환하여 df_21_22 DataFrame의 해당 열을 업데이트합니다.
df_21_22 DataFrame을 pivot_table 함수를 사용하여 피벗 테이블 형식으로 변환합니다.
pivot_table 함수를 사용하면 데이터프레임을 피벗 테이블로 변환할 수 있습니다.
index='자치구 기준일'은 '자치구 기준일'을 인덱스로 사용하도록 지정합니다.
values=choose는 choose 리스트에 해당하는 컬럼들을 값으로 사용하도록 지정합니다.
결과적으로, df_pivot에는 df_21_22 DataFrame을 피벗 테이블로 변환한 결과가 저장됩니다. 이를 통해 '자치구 기준일'을 인덱스로 하고, choose 리스트에 해당하는 컬럼들을 값으로 가지는 피벗 테이블을 얻을 수 있습니다.
7.
df_pivot DataFrame을 월별로 묶어서 데이터를 정리합니다.
resample('M')을 사용하여 월별 리샘플링을 수행합니다. 여기서 'M'은 월(month)을 나타내는 빈도 코드입니다.
resample 메서드는 날짜/시간 기반의 인덱스를 가진 DataFrame에서 리샘플링 작업을 수행할 수 있도록 해주는 메서드입니다.
'M'은 월 단위로 리샘플링하는 옵션을 나타냅니다.
last() 메서드를 사용하여 각 월별 그룹에서 마지막 데이터를 선택합니다.
last() 메서드는 각 그룹 내에서 가장 마지막 데이터를 선택하는 역할을 합니다.
결과적으로, monthly_covid에는 df_pivot DataFrame을 월별로 묶어서 정리한 결과가 저장됩니다. 각 월의 마지막 데이터가 포함된 DataFrame이 생성됩니다.
즉, monthly_covid는 df_pivot DataFrame의 데이터를 월 단위로 묶어서 정리한 결과를 담고 있습니다.
8.
monthly_covid DataFrame의 컬럼들을 df_name 변수에 저장합니다.
그래프의 크기를 (20, 10)으로 설정합니다.
df_name의 각 컬럼에 대해 반복문을 실행합니다.
반복문 내에서 plt.plot(monthly_covid[df], label=df)를 사용하여 각 컬럼에 해당하는 데이터를 가져와서 그래프를 그립니다.
monthly_covid[df]는 monthly_covid DataFrame에서 df에 해당하는 컬럼의 데이터를 선택합니다.
label=df를 통해 그래프의 범례에 해당 컬럼의 이름인 df를 표시합니다.
plt.legend()를 사용하여 범례를 표시합니다.
plt.title('서울시 구별 코로나 확진자 추이', fontsize=20)를 통해 그래프의 제목을 설정합니다.
plt.xlabel('월별', fontsize=13)을 사용하여 x축의 레이블을 설정합니다.
plt.ylabel('확진자수', fontsize=14)를 사용하여 y축의 레이블을 설정합니다.
plt.xticks(monthly_covid.index.to_list(), rotation=90)을 통해 x축의 눈금을 설정합니다.
monthly_covid.index.to_list()는 monthly_covid DataFrame의 인덱스를 리스트로 변환하여 x축 눈금의 위치를 지정합니다.
rotation=90은 x축의 눈금 레이블을 90도 회전하여 글씨가 세로로 표시되도록 합니다.
결과적으로, df_name에 있는 각 컬럼에 해당하는 데이터를 그래프로 그리고, 그래프에 제목, 축 레이블, 범례, 눈금 등을 추가하여 서울시 구별 코로나 확진자 추이를 시각화합니다.
- import 모듈 as 이름 : 모듈을 이름으로 지정항상 모듈을 타이핑 하는 번거로움을 줄이기 위하여 사용
- rc함수: 글꼴 변경하는 함수matplotlib는 기본 글꼴이 영문 글꼴, 깨짐 방지 위해 글씨체 변경 필요
- rcParams: 미리 지정해놓은 스타일을 사용하지 않고 그래프에 새로운 스타일 지정축(axis)과 레이블(label)을 표시할 때 마이너스 기호(-)가 깨지는 것을 방지 matplotlib에서는 기본적으로 마이너스 기호(-)를 표시할 때 유니코드(unicode)를 사용 유니코드에서는 마이너스 기호가 일반적으로 '-'(하이픈)이 아닌 '−'(마이너스 기호)로 표시됩니다. but, 일부 폰트에서는 이 유니코드 마이너스 기호가 지원X -> 마이너스 기호가 깨져서 보일 수 있음 이 코드 사용시 기본적으로 사용하는 유니코드 대신 ASCII 코드의 '-'(하이픈)를 사용하도록 강제할 수 있음 -> 마이너스 기호가 깨지는 현상을 방지
- Non-null Count: 각 열(column)의 데이터 개수
- Dtype: 각 열(column)의 데이터 타입
- df.loc[row,column]: row,column 인덱싱 하기 , :를 넣으면 전체 인덱싱 의미함
- reset_index() 메소드를 사용하여 새로운 인덱스(index)를 생성
- drop메서드: 데이터프레임에서 열을 삭제하는 메서드
- pd.to_datetime() 함수: 시간 형식의 object 자료형 column을 datetime 형식으로 손쉽게 바꿀 수 있음
- pd.pivot_table()괄호안에는 기본적으로 DataFrame명, index를 넣어야 함
- DataFrame명
- index = ['그룹핑하고 싶은 칼럼명1','그룹핑하고 싶은 칼럼명2',....]index는 하나일 경우에는 index = '계정코드'와 같이 넣을 수 있으며, 두 개 이상일 경우에는 리스트의 형태로 넣을 수 있음
- resamle(), W = weekly frequency : 주간 빈도
- plot() 함수: 다양한 기능을 포함 -> 임의의 개수의 인자를 받을 수 있음
- label: 해당 그래프를 나타내는 범례(legend)의 이름을 설정합니다. df는 해당 열(column) 이름이므로, 이를 범례 이름으로 설정
- .to_list() 함수: Pandas Index 객체를 리스트로 변환하는 함수
글 드라이브 연동
- 실행시 구글 계정 로그인 팝업창이 나타남 -> 로그인 후 인증코드 복사 후 authorization code를 입력하라는 빈 칸에 입력 -> Mounted at /content/drive 메시지 출력이 뜬다면 드라이브 마운트에 성공
- for 모듈 import 변수/함수/클래스/*
- 모듈의 일부만 가져올 때 사용
글 드라이브 연동
- 실행시 구글 계정 로그인 팝업창이 나타남 -> 로그인 후 인증코드 복사 후 authorization code를 입력하라는 빈 칸에 입력 -> Mounted at /content/drive 메시지 출력이 뜬다면 드라이브 마운트에 성공
- for 모듈 import 변수/함수/클래스/*
- 모듈의 일부만 가져올 때 사용
서울과 수도권의 1949년부터 2010년까지 인구증가율

위 도표의 데이터는 'Seoul_pop2.csv' 파일에 아래와 같이 저장되어 있다.
### 1949년부터 2010년 사이의 서울과 수도권 인구 증가율(%)
# 구간,서울,수도권
1949-1955,9.12,-5.83
1955-1960,55.88,32.22
1960-1966,55.12,32.76
1966-1970,45.66,28.76
1970-1975,24.51,22.93
1975-1980,21.38,21.69
1980-1985,15.27,18.99
1985-1990,10.15,17.53
1990-1995,-3.64,8.54
1995-2000,-3.55,5.45
2000-2005,-0.93,6.41
2005-2010,-1.34,3.71이제 위 파일을 읽어서 서울과 수도권의 인구증가율 추이를 선그래프로 나타내 보자.
단계 1: csv 파일 읽어드리기
확장자가 csv인 파일은 데이터를 저장하기 위해 주로 사용한다.
csv 파일을 읽어드리는 방법은 csv 모듈의 reader() 함수를 활용하면 매우 쉽다
import csv
with open('data/Seoul_pop2.csv') as f:
reader = csv.reader(f)
for row in reader:
if len(row) == 0 or row[0][0] == '#':
continue
else:
print(row)
['1949-1955', '9.12', '-5.83']
['1955-1960', '55.88', '32.22']
['1960-1966', '55.12', '32.76']
['1966-1970', '45.66', '28.76']
['1970-1975', '24.51', '22.93']
['1975-1980', '21.38', '21.69']
['1980-1985', '15.27', '18.99']
['1985-1990', '10.15', '17.53']
['1990-1995', '-3.64', '8.54']
['1995-2000', '-3.55', '5.45']
['2000-2005', '-0.93', '6.41']
['2005-2010', '-1.34', '3.71']
csv.reader 함수의 리턴값은 csv 파일의 내용을 줄 별로 리스트로 저장한 특별한 자료형이다. 여기서는 위 예제처럼 사용하는 정도만 기억하면 된다.
year_intervals = []
Seoul_pop = []
Capital_region_pop = []
with open('data/Seoul_pop2.csv') as f:
reader = csv.reader(f)
for row in reader:
if len(row) == 0 or row[0][0] == '#':
continue
else:
year_intervals.append(row[0])
Seoul_pop.append(float(row[1]))
Capital_region_pop.append(float(row[2]))
3. 그래프 그리기
# 그래프를 그릴 도화지 준비하기
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# x축에 년도, y축에 인구수가 있는 선 그래프 만들기
plt.plot(range(12), Seoul_pop, color='green', marker='o', linestyle='solid', \
label='Seoul')
plt.plot(range(12), Capital_region_pop, color='red', marker='o', linestyle='solid', \
label='Capital Region')
plt.xticks(range(12), year_intervals, rotation=45) # 글씨 45도 각도로 돌리기
plt.title("Population Change") # 그래프 제목 설절하기
plt.ylabel("Percentage") # y축 이름 설정하기
plt.legend()
plt.show()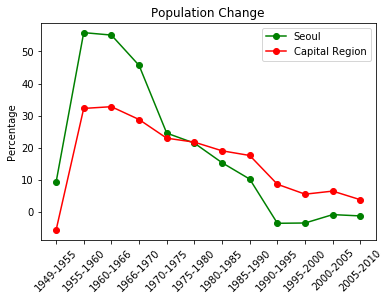
'Study > Code Reading' 카테고리의 다른 글
| Code Reading #5 (0) | 2023.05.15 |
|---|