작성자 : 옥근우
작성일 : 2023.04.02
타이타닉호가 침몰하는 사진을 출력하기 위해 Ipython.display 라이브러리를 import 하고 이미지를 주소로 불러왔습니다.
Ipython.display 라이브러리는 Ipython(우리가 사용하는 jupyter notebook이 Ipython입니다.)에서 다양한 미디어(이미지, 오디오, 비디오 등)를 출력할 수 있도록 해주는 라이브러리입니다. 우리는 특히 사진을 출력하기 위해 라이브러리에서 Image만 import 하였습니다.


필요한 라이브러리들을 import 하고 train.csv와 test.csv파일을 pandas 라이브러리를 이용하여 읽은 다음 각각 train과 test라는 변수에 저장하였습니다.

import 한 라이브러리들과 역할은 다음과 같습니다.
pandas : 데이터 분석을 위한 라이브러리로, 데이터를 다루기 쉽게 만들어주는 도구입니다.
matplotlib : 데이터 시각화를 위한 라이브러리로, 다양한 그래프와 차트를 그려준다.
missingno : 결측치 시각화를 위한 라이브러리로, 결측치의 위치와 분포를 한눈에 파악할 수 있도록 도와준다.
다음으로는 읽어온 train.csv와 test.csv파일의 형태, 크기, 자료형들을 파악하였습니다.
우선 .head()를 활용하여 데이터의 첫 5행을 살펴보았습니다.


실행 결과 train.csv에는 PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked로 총 12개의 열이 있음을 확인할 수 있습니다. 각 행이 의미하는 바는 다음과 같습니다.


실행결과 train에서 Survived 행을 제외한 모든 행이 포함되어 음을 확인할 수 있습니다. 이는 최종 목표가 test 데이터셋의 정보들을 활용하여 탑승자의 Survived 값을 추정하는 것이기 때문입니다.
다음으로는 .shape()를 활용하여 데이터의 크기를 알아보았습니다.

⇒ (891, 12)
train 데이터셋은 891개의 행과 12의 열로 이루어져 있음을 확인할 수 있습니다.

⇒ (418, 11)
test 데이터셋은 418개의 행과 12개의 열로 이루어져 있음을 확인할 수 있습니다.
다음으로 .info()를 활용하여 데이터셋에 대한 정보(자료형, null의 개수)를 확인하였습니다.

⇒
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
Age와 Cabin column에 결측치가 많이 존재함을 확인할 수 있습니다.

⇒
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
test 데이터셋 또한 동일한 형식으로 이루어져 있으며, 마찬가지로 Age와 Cabin column에 결측치가 많이 있음을 확인할 수 있습니다.
결측치를 시각화해보았습니다. 코드와 결과는 다음과 같습니다.


위에서 확인하였듯 Age와 Cabin에 결측치가 많음을 다시 한번 확인할 수 있습니다.
다음으로 생존율을 시각화해 보았습니다. 코드와 결과는 다음과 같습니다.


다음으로는 시각화를 위한 함수를 새로 정의하였습니다.
bar_chart()는 변수에 따른 생존자의 수와 사망자의 수를 시각화하는 함수입니다.

new_chart는 변수에 따른 생존자와 사망자의 비율을 시각화하는 함수입니다.

위에서 정의한 함수를 이용하여 Sex, Pclass, SibSp, ParCh, Embarked에 따른 통계를 시각화하였습니다.
<Sex>


female이 생존자 수도, 생존율도 높음을 확인할 수 있습니다.
<Pclass>


등급에 따른 생존자 수는 큰 차이가 없지만 생존율은 등급이 높을수록 생존율도 높음을 확인할 수 있습니다.
<SibSp>


<ParCh>


<Embarked>


탑승 항구에 따른 생존율은 Cherbourg > Queenstown > Southampton 순서임을 확인할 수 있습니다.
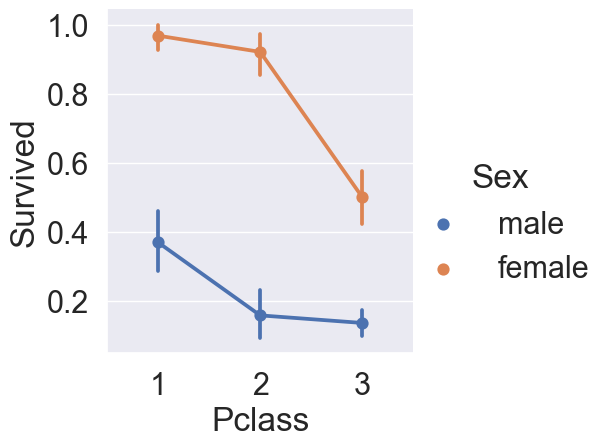
seaborn 라이브러리의 catplot을 활용하여 Sex, Pclass에 따른 생존율을 시각화해보았습니다.
코드와 결과는 다음과 같습니다.

seaborn 라이브러리의 kdeplot을 활용하여 나이에 따른 생존자수와 사망자수를 시각화해 보았습니다.
코드와 결과는 다음과 같습니다.


20~40대 탑승자가 가장 많았으며 10대를 기점으로 10대 이하에는 생존자 > 사망자 이지만 10대 이상에서는 생존자 < 사망자 임을 확인할 수 있습니다.
또한 나이에 따른 생존율을 시각화해 보았습니다.
코드와 결과는 다음과 같습니다.


나이가 어릴수록, 젊을수록 높은 생존율을 보임을 확인할 수 있습니다.
seaborn 라이브러리의 violinplot을 활용하여 Pclass와 Age에 따른 분포, Sex와 Age에 따른 분포를 시각화해 보았습니다.
코드와 결과는 다음과 같습니다.


위에서 확인한 대로 높은 등급일수록, 젊을수록, 여성일수록 생존자가 많음을 다시 한번 확인할 수 있습니다.
마지막으로 탑승 항구와 여려 변수들을 복합적으로 시각화해보았습니다.
코드와 결과는 다음과 같습니다.


(1) - 전체적으로 봤을 때, S에서 가장 많은 사람이 탑승했음을 확인할 수 있습니다.
(2) - C와 Q는 남녀의 비율이 비슷하고, S는 남자가 더 많음을 확인할 수 있습니다.
(3) - 생존확률이 S 경우 많이 낮음을 확인할 수 있습니다
(4) - Class별로 살펴본 결과 C가 생존확률이 높은 건 클래스가 높은 사람이 많이 타서 그런 것임음을 확인할 수 있습니다. 마찬가지로 S는 3rd class 가 많아서 생존확률이 낮게 나옴을 확인할 수 있습니다.
4. Feature Engineering
작성자: 이채영
작성일: 2023.04.03
Feature Engineering 이란?
Feature engineering은 기계 학습 모델링에서 사용되는 입력 데이터를 구성하는 프로세스를 말합니다.
이는 데이터 분석 단계에서 수행되며, 다양한 기술과 알고리즘을 사용하여 데이터를 변환하고, 결측값을 처리하고, 이상치를 제거하고, 데이터를 정규화하는 등의 작업을 수행합니다.
어떻게 타이타닉이 침몰했는지에 관한 그림을 불러오고 확인합니다.
Image(url= "https://static1.squarespace.com/static/5006453fe4b09ef2252ba068/t/5090b249e4b047ba54dfd258/1351660113175/TItanic-Survival-Infographic.jpg?format=1500w")
Third Class이 있던 배의 뱃머리부터 침몰한 것을 볼 수 있고, Pclass 정보가 탑승객의 생존여부에 큰 영향을 끼칠 것으로 예상됩니다.
시작하기에 앞서 train 데이터셋의 정보를 확인합니다.
train.head()
◈4-1. Name
name 데이터을 보면 특정 데이터에는 Mr, Mrs, Miss 와 같이 이름에서 연령을 유추해볼 수 있는 정보들이 담겨있습니다.
train_test_data = [train, test] # combining train and test dataset
for dataset in train_test_data:
dataset['Title'] = dataset['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)str.extract() 함수를 사용하여 정규표현식을 이용해 이름에서 호칭을 추출합니다.
즉, 이 코드에서는 공백으로 시작하고, 하나 이상의 알파벳 대소문자로 이루어진 문자열 뒤에 마침표가 오는 패턴을 찾아 추출합니다. 이는 일반적으로 이름의 뒤에 나오는 호칭의 형태를 따르기 때문에, 대부분의 경우 이름과 함께 쓰인 호칭을 추출할 수 있습니다.
train['Title'].value_counts() #'Title'열에서 각각의 값들이 몇 번씩 나오는지 세기
test['Title'].value_counts() #'Title' 열에서 각각의 값들이 몇 번씩 나오는지 세기
※ Title map
Mr : 0
title_mapping = {"Mr": 0, "Miss": 1, "Mrs": 2,
"Master": 3, "Dr": 3, "Rev": 3, "Col": 3, "Major": 3, "Mlle": 3,"Countess": 3,
"Ms": 3, "Lady": 3, "Jonkheer": 3, "Don": 3, "Dona" : 3, "Mme": 3,"Capt": 3,"Sir": 3 }
for dataset in train_test_data:
dataset['Title'] = dataset['Title'].map(title_mapping) #새로운 'Title'칼럼 만들기train.head()
test.head()
# delete unnecessary feature from dataset
train.drop('Name', axis=1, inplace=True)
test.drop('Name', axis=1, inplace=True)Mr, Mrs, Miss 을 제외하곤 Name 열이 필요없으므로 train데이터셋과 test데이터셋에서 제거합니다.
train.head()
◈4-2. Sex
문자형 변수를 male : 0 / female : 1로 매핑합니다.
sex_mapping = {"male": 0, "female": 1}
for dataset in train_test_data:
dataset['Sex'] = dataset['Sex'].map(sex_mapping)bar_chart('Sex')
new_chart('Sex')
train.head()
◈4-3. Age
# fill missing age with median age for each title (Mr, Mrs, Miss, Others)
train["Age"].fillna(train.groupby("Title")["Age"].transform("median"), inplace=True)
test["Age"].fillna(test.groupby("Title")["Age"].transform("median"), inplace=True)'train' 데이터프레임에서 'Title' 열을 기준으로 그룹화한 후, 각 그룹에서 'Age' 열의 중앙값을 구한 뒤, 결측치를 해당 그룹의 중앙값으로 대체합니다.
'Age'열에 대해 그래프를 그립니다.
facet = sns.FacetGrid(train, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.show()
train.info()
'Age'에서 177의 null값들이 중앙값으로 채워진 것을 확인할 수 있습니다.
test.info()
'Age'에서 86의 null값들이 중앙값으로 채워진 것을 확인할 수 있습니다.
※4-3.2 Binning
숫자 연령을 범주형 변수로 변환하고 구간화합니다.
feature vector map:
child: 0
young: 1
adult: 2
mid-age: 3
senior: 4
for dataset in train_test_data:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 26), 'Age'] = 1
dataset.loc[(dataset['Age'] > 26) & (dataset['Age'] <= 36), 'Age'] = 2
dataset.loc[(dataset['Age'] > 36) & (dataset['Age'] <= 62), 'Age'] = 3
dataset.loc[ dataset['Age'] > 62, 'Age'] = 4
train.head()
bar_chart('Age')
new_chart('Age')

◈4-4. Embarked
상관관계가 있을 것 같은 Pclass에 따른 Embarked를 확인합니다.
Pclass1 = train[train['Pclass']==1]['Embarked'].value_counts()
Pclass2 = train[train['Pclass']==2]['Embarked'].value_counts()
Pclass3 = train[train['Pclass']==3]['Embarked'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = ['1st class','2nd class', '3rd class']
df.plot(kind='bar',stacked=True, figsize=(10,5))
1,2,3 class에서 S embark가 50퍼센트가 넘는 걸 볼 수 있습니다.
따라서 비어있는 값들을 S embark로 채웁니다.
for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S') #fill out missing embark with S embark
train.head()
embarked_mapping = {"S": 0, "C": 1, "Q": 2} #숫자형으로 변환
for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].map(embarked_mapping)
작성자: ★심민준★
작성일: 2023.04.03
◈ 4-5 Fare
Fare는 타이타닉호 탑승자들의 티켓값을 나타낸 데이터로 객실등급이 좋을수록 티켓값이 비싸지는것은 당 연하기에 fare데이터와 Pclass데이터 사이에는 상관관계가 있다고 생각할 수 있습니다.
- fare데이터에 존재하는 결측값들을 채워넣기 위해 Pclass와 fare간의 상관관계가 있다는 것을 이용했습니다.
- pclass정보에는 nan값이 없었다. 그래서 Pclass 가 1등급인 사람들의 fare값의 중간값을 1등급인데 fare가 nan인 사람에게 채워 넣는 방식으로 결측값을 제거했습니다.
# fill missing Fare with median fare for each Pclass
train["Fare"].fillna(train.groupby("Pclass")["Fare"].transform("median"), inplace=True)
test["Fare"].fillna(test.groupby("Pclass")["Fare"].transform("median"), inplace=True)
train.head(50)
- 그래프 확인 결과 저렴한 티켓을 산 사람들이 비싼 티켓을 산 사람들에 비해 많이 사망했음을 알 수 있습니다.
facet = sns.FacetGrid(train, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Fare',shade= True)
facet.set(xlim=(0, train['Fare'].max()))
facet.add_legend()
plt.show()
- xlim을 통해 그래프의 범위를 축소하여 두 개의 그래프가 접하는 특이점이 있는 부분을 관찰해보았습니다.
- 그 결과 30달러보다 싼 티켓을 산 사람들은 생존자보다 사망자가 더 많았던 반면 30달러 이상의 티켓을 산 사람들은 생존확률이 더 높았다는 것을 확인할 수 있었습니다.
facet = sns.FacetGrid(train, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Fare',shade= True)
facet.set(xlim=(0, train['Fare'].max()))
facet.add_legend()
plt.xlim(0, 30)
- fare 데이터 역시도 머신러닝을 위해 age데이터를 처리할 때 사용했던 binning기술 이용해서 데이터를 수치화했습니다.
for dataset in train_test_data:
dataset.loc[ dataset['Fare'] <= 17, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 17) & (dataset['Fare'] <= 30), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 30) & (dataset['Fare'] <= 100), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 100, 'Fare'] = 3- 티켓값이 비싸질수록 생존확률이 높아짐을 확인할 수 있습니다.
train.head()
new_chart('Fare')
◈ 4-6 Cabin
cabin은 객실의 방번호를 나타내는 데이터입니다. cabin데이터의 공통적인 특징은 알파벳 한글자로 데이터가 시작되고 뒤에는 방번호가 적혀있다는 것입니다.
train.Cabin.value_counts()

for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].str[:1] #맨 첫 글자인 알파벳만 확인- 객실 1등급에는 cabin데이터 가장 앞 글자가 abcde인 것만 존재한다는 정보를 확인할 수 있습니다.
Pclass1 = train[train['Pclass']==1]['Cabin'].value_counts()
Pclass2 = train[train['Pclass']==2]['Cabin'].value_counts()
Pclass3 = train[train['Pclass']==3]['Cabin'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = ['1st class','2nd class', '3rd class']
df.plot(kind='bar',stacked=True, figsize=(10,5))
Feature Scaling
feature scaling은 feature가 무의미해지는 것을 방지해주는 전처리 작업
머신러닝 classifier는 데이터 분석 시 숫자값을 이용하고 계산 시 Euclidean distance를 사용한다.
즉 숫자의 범위가 비슷하지 않으면 데이터를 과대 혹은 과소평가하여 제대로 된 분석이 이루어지지 않기에 분석 시 적절한 가중치를 부여하는 것이 중요합니다.
- 지금까지 다른 변수들은 0123과 같은 형태로 3까지의 일정한 간격의 정수로 각 변수들을 수치화했습니다.
- 그러나 cabin변수는 변수값이 너무 많아 동일 간격으로 최대한 3에 가깝게 그러나 3은 넘지 않도록 수치를 부여하기 위해 0.4간격으로 숫자를 지정했습니다.
cabin_mapping = {"A": 0, "B": 0.4, "C": 0.8, "D": 1.2, "E": 1.6, "F": 2, "G": 2.4, "T": 2.8} #feature scaling (머신러닝 기법법)
for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].map(cabin_mapping)- nan값이 177개나 되기 때에 결측값 처리가 매우 중요합니다.
- Cabin데이터는 Pclass데이터와 밀접한 관계가 있음을 이용하여 각 클래스별 cabin의 중앙값을 결측값에 채웠습니다.
# fill missing Fare with median fare for each Pclass
train["Cabin"].fillna(train.groupby("Pclass")["Cabin"].transform("median"), inplace=True)
test["Cabin"].fillna(test.groupby("Pclass")["Cabin"].transform("median"), inplace=True)결측값 처리 시 median쓰는 이유는 mean으로 했을 때보다 분석 정확도가 높게 나왔기 때문
◈ 4-7 FamilySize
sibsp값+parch값=형제 수+부모님+아이 수 =가족 수 라는 것을 이용해 만든 새로운 데이터
train["FamilySize"] = train["SibSp"] + train["Parch"] + 1# +1한 이유는 가족 수에 본인도 포함하기 위해서이다.
test["FamilySize"] = test["SibSp"] + test["Parch"] + 1- 그래프 확인 시 혼자탔을 때 가장 많이 사망했음을 알 수 있고 가족이 1명이라도 있으면 살 확률이 더 높다는 것을 확인할 수 있습니다.
facet = sns.FacetGrid(train, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'FamilySize',shade= True)
facet.set(xlim=(0, train['FamilySize'].max()))
facet.add_legend()
plt.xlim(0)
수치화시키는 맵핑과정
family_mapping = {1: 0, 2: 0.4, 3: 0.8, 4: 1.2, 5: 1.6, 6: 2, 7: 2.4, 8: 2.8, 9: 3.2, 10: 3.6, 11: 4}
for dataset in train_test_data:
dataset['FamilySize'] = dataset['FamilySize'].map(family_mapping)train.head()
◈ Data Drop
티켓, sibsp, parch,passengerId 데이터는 머신러닝 분석 시 쓸모없는 데이터이므로 제거했습니다.
features_drop = ['Ticket', 'SibSp', 'Parch']
train = train.drop(features_drop, axis=1)
test = test.drop(features_drop, axis=1)
train = train.drop(['PassengerId'], axis=1)
◈ 피어슨 상관계수로 변수들간의 관계 파악
두 변수간의 Pearson correlation 을 구하면 (-1, 1) 사이의 값을 얻을 수 있습니다. -1로 갈수록 음의 상관관계, 1로 갈수록 양의 상관관계를 의미하며, 0은 상관관계가 없다는 것을 의미합니다. 구하는 수식은 아래와 같습니다.

- Sex 와 Pclass 가 Survived 에 상관관계가 어느 정도 있음을 볼 수 있습니다.
- 가장 강한 상관관계를 가지는 것은 당연하게도 fare와 Pclass입니다.
또한 우리가 여기서 얻을 수 있는 정보는 서로 강한 상관관계를 가지는 feature들이 없다는 것입니다.이는 우리가 모델을 학습시킬 때, 불필요한 feature 가 없다는 것을 의미합니다. 만약 완벽한 상관관계, 즉 비례 혹은 반비례 관계인 1 또는 -1 의 상관관계를 가진 feature A, B 가 있다면 우리가 얻을 수 있는 정보는 그 두 feature 사이의 연관성이라는 정보밖에 얻을 것이 없을 것입니다.
heatmap_data = train[['Survived', 'Pclass', 'Sex', 'Fare', 'Embarked', 'FamilySize', 'Age']]
colormap = plt.cm.RdBu
plt.figure(figsize=(14, 12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(heatmap_data.astype(float).corr(), linewidths=0.1, vmax=1.0,
square=True, cmap=colormap, linecolor='white', annot=True, annot_kws={"size": 16})
del heatmap_data
◈ 머신러닝 준비
데이터 학습을 위해 train 데이터프레임에서 Survived정보를 제거하고 target이라는 빈 데이터프레임에 그 Survived정보만을 담습니다. 즉 train은 머신러닝을 하기 위한 컴퓨터의 문제집이고 target은 분석결과의 정확도를 판단할 수 있는 답지라고 생각하면 됩니다.
train_data = train.drop('Survived', axis=1)
target = train['Survived']
train_data.shape, target.shape

작성자: 전서경
작성일: 2023.04.03
Modelling
분류 모델(Classifier Module)이란?
레이블이 달린 학습 데이터로 학습한 후, 새로 입력된 데이터가 어느 그룹에 속하는 지를 찾아내는 방법입니다.
따라서 분류 모델의 결괏값은 언제나 학습했던 데이터의 레이블 중 하나가 됩니다.
자료출처:tcpschool
분류 알고리즘 종류
KNN (k-nearest neighbor), Decision Tree(의사결정 트리), Random Forest, Naive Bayes, SVM (Support Vector Machine) 등이 있습니다.
# Importing Classifier Modules - 대표적인 분류 알고리즘
from sklearn.neighbors import KNeighborsClassifier #KNN (k-nearest neighbor) 불러오기
from sklearn.tree import DecisionTreeClassifier #Decision Tree(의사결정 트리) 불러오기
from sklearn.ensemble import RandomForestClassifier #Random Forest 불러오기
from sklearn.naive_bayes import GaussianNB #Naive Bayes (나이브 베이즈) 불러오기
from sklearn.svm import SVC #SVM (Support Vector Machine) 불러오기
import numpy as np #numpy 불러오기다양한 분류 알고리즘을 불러옵니다.
train.info() #train 데이터셋 확인train 데이터셋의 정보를 확인해봅니다.
[결과]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null int64
3 Age 891 non-null float64
4 Fare 891 non-null float64
5 Cabin 891 non-null float64
6 Embarked 891 non-null int64
7 FamilySize 891 non-null float64
8 Title 891 non-null int64
dtypes: float64(4), int64(5)
memory usage: 62.8 KBtrain 데이터셋은 9개의 컬럼과 891개의 row로 이루어진 것, Null 값이 존재하지 않다는 것을 확인할 수 있습니다.
Cross Validation (K-fold)
K-Fold Cross Validation(K- 겹 교차 검증)이란?
교차 검증이란 쉽게 말해 데이터를 여러 번 반복해서 나누고 여러 모델을 학습하여 성능을 평가하는 방법입니다.
이렇게 하는 이유는 데이터를 학습용/평가용 데이터 세트로 여러 번 나눈 것의 평균적인 성능을 계산하면, 한 번 나누어서 학습하는 것에 비해 일반화된 성능을 얻을 수 있기 때문입니다.
자료출처:tcpschool
1. k=10으로 가정한다면 train data를 10등분하는 것. ex) 891개의 row를 지닌 train 데이터셋의 경우 한 등분 당 89.1개씩
2. 순서대로 돌아가면서 1등분은 validation으로 사용, 나머지 9등분을 train으로 사용.
3. 따라서 10번의 validation 결과로 나온 accuracy를 평균으로 한 것 = validation accuracy score
from sklearn.model_selection import KFold #KFold 불러오기
from sklearn.model_selection import cross_val_score #교차검증을 위한 cross_val_score
k_fold = KFold(n_splits=10, shuffle=True, random_state=0) #10등분으로 나누기기kNN
kNN이란?
기존의 데이터 중 가장 가까운 k개를 바탕으로 새로운 데이터를 예측하고 분류하는 알고리즘입니다
판별하려는 데이터와 인접한 데이터 k개를 찾아 그중 빈도수가 가장 높은 데이터를 범주로 분류합니다.

clf = KNeighborsClassifier(n_neighbors = 13) #최근접 이웃 수를 13으로 지정
scoring = 'accuracy'
score = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring) #cross_val_score 사용하여 교차검증한 데이터 score에 저장
print(score) #점수 확인분류 알고리즘을 kNN 모듈로 지정 후 k(n_neighbors)를 13개로 지정합니다.
교차검증을 수행하는 cross_val_score 함수를 사용하여 score에 저장한 후 점수를 확인합니다.
결과는 아래와 같습니다.
[결과]
[0.81111111 0.7752809 0.83146067 0.83146067 0.85393258 0.83146067
0.82022472 0.80898876 0.83146067 0.80898876]
# kNN Score
round(np.mean(score)*100, 2) #점수 평균내기[결과]
82.04Decision Tree
Decision Tree란?
주어진 입력값들의 조합에 대한 의사결정규칙(rule)에 따라 출력값을 예측하는 모형으로 트리구조의 그래프로 표현합니다.

clf = DecisionTreeClassifier() #분류법으로 DecisionTree 사용
scoring = 'accuracy'
score = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring) #cross_val_score 사용하여 교차검증한 데이터 score에 저장
print(score) #점수 확인분류 알고리즘을 Decision Tree로 지정합니다.
교차검증을 수행하는 cross_val_score 함수를 사용하여 score에 저장한 후 점수를 확인합니다.
결과는 아래와 같습니다.
[결과]
[0.76666667 0.80898876 0.7752809 0.76404494 0.87640449 0.7752809
0.83146067 0.82022472 0.74157303 0.78651685]
# decision tree Score
round(np.mean(score)*100, 2) #점수 평균내기[결과]
79.46Random Forest
Random Forest란?
Decision tree가 여러개 모여 Forest를 이룬 것입니다. 이때 Decision tree보다 작은 Tree가 여러개 모이게 되어, 모든 트리의 결과들을 합하여 더많은 값을 최종결과로 하는 것입니다.
clf = RandomForestClassifier(n_estimators=13) #분류법으로 RandomForest 사용, tree의 갯수는 13개
scoring = 'accuracy'
score = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring) #cross_val_score 사용하여 교차검증한 데이터 score에 저장
print(score) #점수 확인분류 알고리즘을 RandomForest로 지정합니다.
교차검증을 수행하는 cross_val_score 함수를 사용하여 score에 저장한 후 점수를 확인합니다.
결과는 아래와 같습니다.
[결과]
[0.8 0.86516854 0.82022472 0.78651685 0.85393258 0.79775281
0.82022472 0.80898876 0.7752809 0.78651685]
# Random Forest Score
round(np.mean(score)*100, 2) #점수 평균내기[결과]
81.15Naive Bayes
Naive Bayes란?
베이즈 정리에 기반을 둔 알고리즘 모델로, 이것은 각각의 사건들이 일어날 확률들을 측정합니다.
P(A ¦ B) = (P(A ∩ B)) / (P(B))를 설명한다면 다음과 같습니다.
1. 전제: 두 사건 A, B가 있고, 사건 B가 발생한 이후에 사건 A가 발생한다고 가정합니다.
2. 정의: 사건 B가 일어난 후 사건 A가 일어날 확률입니다.
이렇게 정리를 한 상태에서 복잡하게 섞여 있는 문제를 비슷한 성격을 가진 특성(feature)으로 분류하는 것입니다.
clf = GaussianNB() #분류법으로 Naive Bayes 사용
scoring = 'accuracy'
score = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring) #cross_val_score 사용하여 교차검증한 데이터 score에 저장
print(score) #점수 확인[결과]
[0.85555556 0.73033708 0.75280899 0.75280899 0.70786517 0.80898876
0.76404494 0.80898876 0.86516854 0.83146067]
# Naive Bayes Score
round(np.mean(score)*100, 2) #점수 평균내기[결과]
78.78SVM
SVM이란?
서포터 벡터 머신은 기본적으로 Decision Boundary라는 직선이 주어진 상태입니다.
그어진 decision boundary를 기준으로 boundary 위에 있다면, dead. 아래에 있다면 survived로 분류하는 방식입니다.
clf = SVC() #분류법으로 SVC(서포터벡터머신신) 사용
scoring = 'accuracy'
score = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring) #cross_val_score 사용하여 교차검증한 데이터 score에 저장
print(score) #점수 확인[결과]
[0.83333333 0.79775281 0.83146067 0.82022472 0.84269663 0.82022472
0.84269663 0.85393258 0.84269663 0.86516854]
round(np.mean(score)*100,2) #점수 평균내기[결과]
83.5Testing
clf = SVC() #가장 높은 점수가 나온 SVC사용
clf.fit(train_data, target)#train_data:입력데이터,target:해당 데이터 클래스 레이블(정답)
test_data = test.drop("PassengerId", axis=1).copy() #예측할 때 "PassengerId" 열이 필요하지X
prediction = clf.predict(test_data) #clf.predict -> test_data를 입력으로 받아 SVM 모델에서 클래스 레이블을 예측하는 함수, 예측값 prediction에 저장장train_data는 입력 데이터이며, target은 해당 데이터의 클래스 레이블(정답)입니다.
SVM은 주어진 데이터를 최적으로 분류하는 결정 경계를 찾는 알고리즘이므로, 모델은 train_data와 target을 이용하여 클래스 간 경계를 찾는 과정을 거칩니다.
submission = pd.DataFrame({
"PassengerId": test["PassengerId"], #"PassengerId" 열은 test 데이터프레임의 "PassengerId" 열과 동일한 값
"Survived": prediction #"Survived" 열은 앞서 clf.predict() 함수에서 예측한 클래스 레이블
})
submission.to_csv('submission.csv', index=False) #데이터 프레임을 csv파일로 저장submission = pd.read_csv('submission.csv')
submission.head()[결과]

'Study > Kaggle competition' 카테고리의 다른 글
| Kaggle competiton #1 : Titanic survivor predictions (0) | 2023.04.12 |
|---|---|
| Kaggle Competition #4 (1) | 2023.04.04 |
| Kaggle competition #2 (0) | 2023.04.03 |
| Kaggle competition #5 : House Price prediction (0) | 2023.03.23 |



