주제
회기역 시간별 지하철 인원 분석
통학을 하는 대부분의 학생들 중 대다수가 학교를 올 때 지하철 1호선이나 경의중앙선을 이용하여 회기역에서 하차를 한다. 경희대학교 학생이라면 출퇴근시간과 오전 등교시간에 매우 혼잡한 회기역의 모습을 본 경험이 있을 것이다. 우리 조원들 중 4명 중 3명은 매일마다 편도 한 시간~두 시간이 걸리며 통학을 하는 "통학러"인 학생들로서, 매우 혼잡한 상태의 지하철과 회기역의 고단함을 누구보다 잘 아는 사람들이다.
우리는 월별, 호선별, 역별, 시간대별 승하차 인원 수가 나와있는 데이터 파일을 활용하여, 최근의 회기역의 시간대별 혼잡도를 한눈에 파악하고, 이러한 문제들과 학생들의 불편함을 해결할 수 있는 인사이트를 도출하려고 한다.
1. 글씨체 다운로드
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf시스템에 나눔 글꼴을 설치하고, Matplotlib 라이브러리의 캐시를 갱신한다. 이후에는 Matplotlib을 사용하여 그래프나 플롯을 생성할 때 나눔 글꼴을 선택해 적용한다.
2. 구글 드라이브 연동
from google.colab import drive
drive.mount('/content/drive')출력되는 URL 링크를 클릭하여 Google 계정에 로그인하고, 인증 코드를 복사하여 Colab에 붙여넣어 Google 드라이브를 마운트한다.
3. 데이터 불러오기, 전처리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font',family='NanumbarunGothic')
plt.rcParams['axes.unicode_minus']=False
from matplotlib import font_manager, rc
rail_p=pd.read_csv('/content/drive/MyDrive/서울시 지하철 호선별 역별 시간대별 승하차 인원 정보.csv',encoding = 'cp949')Python 프로그램에서 Pandas, NumPy, Matplotlib 라이브러리를 가져오며, 한글 글꼴을 설정하여 데이터 시각화를 위한 준비를 하고, rail_p라는 변수에 CSV 파일을 읽어들인다.
rail_p
rail_p.info()
rail_p.columns
df= rail_p[['사용월','지하철역','07시-08시 승차인원','07시-08시 하차인원', '08시-09시 승차인원', '08시-09시 하차인원', '09시-10시 승차인원','09시-10시 하차인원', '10시-11시 승차인원', '10시-11시 하차인원', '11시-12시 승차인원','11시-12시 하차인원', '12시-13시 승차인원', '12시-13시 하차인원', '13시-14시 승차인원','13시-14시 하차인원', '14시-15시 승차인원', '14시-15시 하차인원', '15시-16시 승차인원','15시-16시 하차인원', '16시-17시 승차인원', '16시-17시 하차인원', '17시-18시 승차인원','17시-18시 하차인원', '18시-19시 승차인원', '18시-19시 하차인원', '19시-20시 승차인원','19시-20시 하차인원', '20시-21시 승차인원', '20시-21시 하차인원', '21시-22시 승차인원','21시-22시 하차인원', '22시-23시 승차인원', '22시-23시 하차인원', '23시-24시 승차인원','23시-24시 하차인원']]우리 조는 2023년 3월 회기역의 07시부터 24시까지의 승하차인원에 대해 알아보고 싶었기 때문에, rail_p의 column들 중 '사용월', '지하철역', '07시-08시 승차인원', '07시-08시 하차인원', '08시-09시 승차인원', '08시-09시 하차인원', '09시-10시 승차인원','09시-10시 하차인원', '10시-11시 승차인원', '10시-11시 하차인원', '11시-12시 승차인원','11시-12시 하차인원', '12시-13시 승차인원', '12시-13시 하차인원', '13시-14시 승차인원','13시-14시 하차인원', '14시-15시 승차인원', '14시-15시 하차인원', '15시-16시 승차인원','15시-16시 하차인원', '16시-17시 승차인원', '16시-17시 하차인원', '17시-18시 승차인원','17시-18시 하차인원', '18시-19시 승차인원', '18시-19시 하차인원', '19시-20시 승차인원','19시-20시 하차인원', '20시-21시 승차인원', '20시-21시 하차인원', '21시-22시 승차인원','21시-22시 하차인원', '22시-23시 승차인원', '22시-23시 하차인원', '23시-24시 승차인원', '23시-24시 하차인원'만 추출하여 데이터프레임으로 만들었다.
df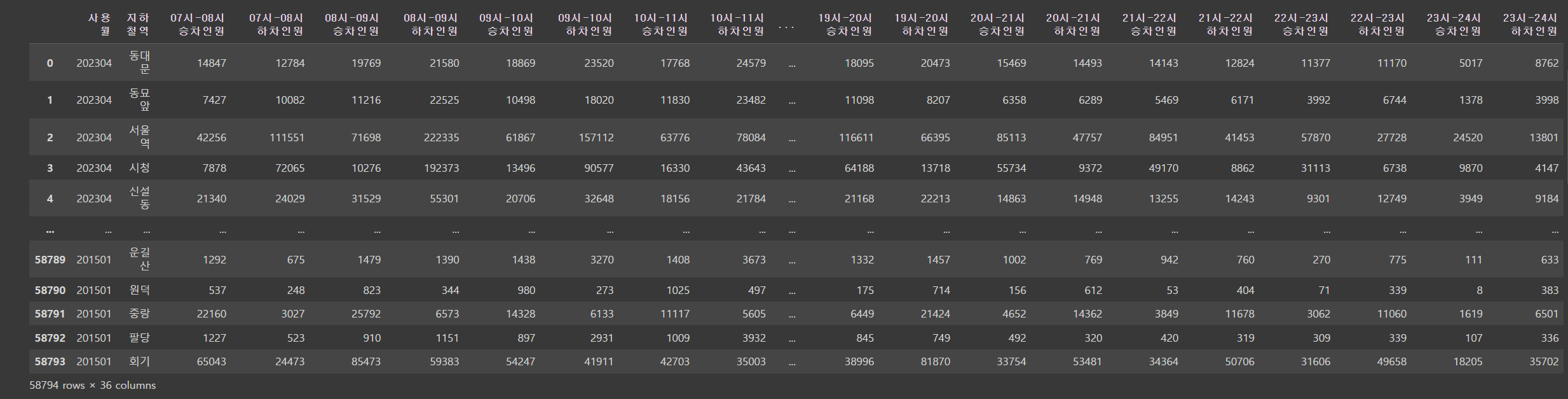
4. '지하철역'에서 '회기'에 해당하는 값만 추출
list_1 = []
for i in range((len(df['지하철역']))):
if '회기' in df['지하철역'][i]:
list_1.append(i)우리 조가 알아보고자 한 역은 회기역이기 때문에, '지하철역'의 전체 데이터에서 '회기'가 해당하는 인덱스만 추출하여 list_1에 저장하였다.
df_1 = df.loc[list_1,].reset_index(drop=True)df에서 '회기'에 해당하는 row 값만을 추출하고, 인덱스를 초기화해 0부터 시작하도록 하였다.
df_1
df=pd.DataFrame(df_1)
result=df[df['사용월'].astype(str).str.contains('202303')]또한, df_1 중 '사용월'이 '202303'에만 해당하는 값을 추출하고 싶어 astype 함수를 사용하여 result 라는 새로운 데이터프레임을 생성했다.
* astype 함수 : 원하는 컬럼의 type을 바꾸는 함수
result
5. pivot table 만들기
df_pivot=result.pivot_table(index='사용월',values=['지하철역','07시-08시 승차인원','07시-08시 하차인원', '08시-09시 승차인원', '08시-09시 하차인원', '09시-10시 승차인원','09시-10시 하차인원', '10시-11시 승차인원', '10시-11시 하차인원', '11시-12시 승차인원','11시-12시 하차인원', '12시-13시 승차인원', '12시-13시 하차인원', '13시-14시 승차인원','13시-14시 하차인원', '14시-15시 승차인원', '14시-15시 하차인원', '15시-16시 승차인원','15시-16시 하차인원', '16시-17시 승차인원', '16시-17시 하차인원', '17시-18시 승차인원','17시-18시 하차인원', '18시-19시 승차인원', '18시-19시 하차인원', '19시-20시 승차인원','19시-20시 하차인원', '20시-21시 승차인원', '20시-21시 하차인원', '21시-22시 승차인원','21시-22시 하차인원', '22시-23시 승차인원', '22시-23시 하차인원', '23시-24시 승차인원','23시-24시 하차인원'])주어진 데이터프레임(result)을 활용하여 2023년 3월 회기역의 07시부터 24시까지 지하철 승하차인원을 정리한 결과인 df_pivot 데이터프레임을 만들었다.
df_pivot
6. 시간대별 승차인원과 하차인원 합치기
time_list = [None] * len(df_pivot.columns)
for i in range(len(df_pivot.columns)):
time_list[i] = df_pivot.columns[i][:7]
time_list = list(set(time_list))
sorted_list = sorted(time_list)
sum_list = []
for i in sorted_list:
name_index = []
for j in df_pivot.columns:
if i in j:
name_index.append(j)
time = 0
for n in name_index:
time += df_pivot[n]
time = int(time)
sum_list.append(time)
df_sum = pd.DataFrame(sum_list, sorted_list)
df_sum.columns = [['회기역 이용자 수']]우리 조는 회기역의 시간대별 지하철 이용 인원을 알아보고자 한 것이기 때문에, 승차 인원과 하차 인원을 구분하지 않고 시간대별 승차 인원과 하차 인원을 합쳐서 시간대별 지하철 이용 인원을 나타내기로 하였다. 따라서, 위 코드를 통해 시간대별 승차 인원과 하차 인원을 합친 데이터프레임 df_sum을 생성하였다.
df_sum
7. 그래프 그리기
df_name=df_sum.columns
plt.figure(figsize=(17,10))
for df in df_name:
plt.plot(df_sum[df],label=df)
plt.legend()
plt.title('시간대별 회기역 지하철 이용자 수',fontsize=20)
plt.xlabel('시간대별',fontsize=13)
plt.ylabel('이용자수',fontsize=14)
plt.xticks(df_sum.index.to_list() , rotation=0)
예상대로 출근 시간과 오전 수업이 겹치는 08-09시 시간대와 퇴근 시간인 18-19시 시간대에 회기역이 가장 붐빈다는 것을 알 수 있었다.
이를 통해 경희대학교 학생들이 조금 더 원활하게 등교를 하기 위해서는 1교시 수업 수강신청을 지양하는 방법이 있다. 또한 18시에 끝나는 강의가 있다면 바로 귀가하는 것보다 한 두시간 정도 학교에 남아서 복습을 하고 귀가하는 것이 더 좋은 방법이라는 결론을 얻었다.
원론적인 정책적 해결 방법은 08-09시와 18-19시에 다니는 1호선과 경의중앙선을 증차하며, 배차 간격를 줄여서 인구를 유동적으로 옮기는 방법이 있을 것이다. 더하여 동대문 마을 버스를 증차하여, 회기역 지하철에서 하차하였지만, 남아서 기다리는 인구를 조절하는 방법도 회기역의 혼잡도를 줄일 수 있는 방법이라는 결론을 내렸다.
'Project > 2023_데이터 시각화' 카테고리의 다른 글
| CODE 데이터 시각화 프로젝트 #5 (0) | 2023.05.30 |
|---|---|
| Code 데이터 시각화 프로젝트 #1 (0) | 2023.05.29 |

