주제
빅데이터응용학과 재학생들이 졸업 후 나아가게 될 진로 중 가장 많은 학생들이 선택할 데이터 사이언스 분야의 세부 직종별 급여의
수준에 대해 조사해보고, 시각화해보며 직종과 급여의 상관관계에 대해서 알아보기로 했다. 데이터 사이언스 분야에서도 꽤 세분화된 직종이 있으며, 직종에 따라 급여 차이의 폭이 얼마나 큰지도 조사해보고 결과를 도출하였다.
1. 글씨체 다운로드

시각화된 그래프에 출력할 폰트를 설치하고, 런타임을 재시작해준다.
2. 구글 드라이브 연동

시각화할 파일을 드라이브에서 python으로 불러오기 위해 구글 드라이브와 연동시킬 수 있는 함수를 만들어준다.
3. 데이터 불러오기, 전처리

구글 드라이브와 연동하여 불러온 파일을 열기 위해서는 파일 안의 데이터를 불러오고, 전처리하는 과정을 거쳐야 한다. 이때 python에서는 pandas, numpy 모듈과 파일 데이터의 시각화를 위해 matplotlib 모듈이 필요하다. 데이터를 불러온 뒤에는 plt, dt 등의 모듈을 사용하여 표기한다.
파일을 불러오기 위해서는 파일의 정확한 경로를 입력하여 해당 파일이 정확하게 처리될 수 있도록 입력해야 한다.
(파일 못불러온거 오류 항목(?)에 넣기)
dt_salary_data라는 새로운 변수를 지정하여 csv파일을 읽어들이고, 처리된 파일에서 분석할 요소들을 찾아 분류한다.
*csv 파일: Excel의 텍스트 전용 파일의 형식이며, 쉼표로 구분되어 있다. 파일 내부에는 숫자와 문자만 입력할 수 있고, 이 숫자와 문자 안에 포함된 데이터를 표로 만들 수 있다.
4. 분석하고자 하는 속성 추출
'세부 직종' 별 '급여'를 알기 위해 'experience_level'과 'salary'를 지정하여 불러운다.
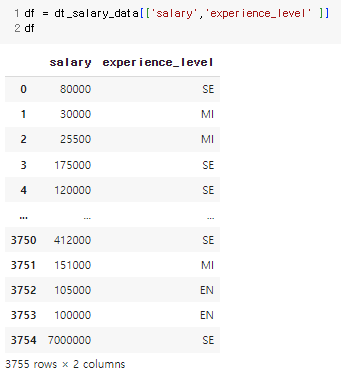
5. 같은 직종으로 분류화
MI, SE, EN, EX 4가지의 항목들로 experience_level들이 퍼져있으니 MI을 담을 빈 리스트를 생성하고, for문을 돌면서 'experience_level'에 'MI'가 있으면 빈 리스트에 추가하는 코드를 짰다. 다른 experience_level도 이와 같이 프로그래밍해준다.


새로운 list_data에 같은 experience_level의 인덱스 리스트를 합치고, loc[] 함수를 이용하여 같은 experience_level에 해당하는 row값('salary')을 추출한다. 그리고 reset_index() 함수를 사용하여 인덱스를 초기화시켜 0부터 시작하도록 한다. 결과는 아래 사진과 같이 나온다.

6. 같은 experience_level끼리 평균 salary구하기
EN - Entry level : 초보, 입문
MI - Mid Level : 중간 등급
SE - Senior level : 상위 등급
EX - Executive Level : 최상위 등급

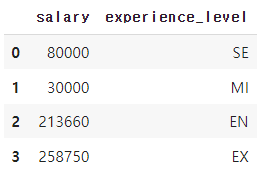
특정 experience_level의 salary 평균을 소수 첫째 자리까지 나타내는 코드를 짰다.

drop_duplicates() 함수를 이용하여 'processor_name' 열을 기준으로 df에서 중복된 행을 제거한다. 따라서 각 experience_level마다 하나의 행이 출력된다. 그리고 인덱스를 0부터 시작하도록 초기화시킨다. 아래 사진은 그 결과이다
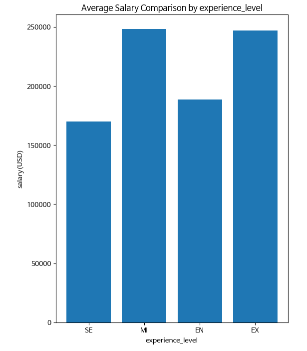
7. 그래프 그리기
x축에 experience_level, y축에 평균 salary을 지정하였다

'Project > 2023_데이터 시각화' 카테고리의 다른 글
| CODE 데이터 시각화 프로젝트 #6 (0) | 2023.05.29 |
|---|---|
| Code 데이터 시각화 프로젝트 #1 (0) | 2023.05.29 |

