팀명 : 누오챙현
참가주제 : Track1
⦿추진 배경 및 필요성
1. R&D과제 선정의 중요성 증가 : 정부는 국가적으로 중요한 과제와 전략 기술에 대한 연구 및 개발 방향을 제시하기 위해 "임무중심 R&D 혁신체계"를 수립했습니다. 이 체계는 국가적으로 중요한 과제에 초점을 맞추어 연구 및 개발을 추진하는 첫 단계입니다. 이와 관련하여, 2022년에 과학기술정보통신부가 임무중심 R&D 혁신체계를 어떻게 구축할 것인지에 대한 방안을 심의하고 의결했다고 발표했습니다.
2. 기술 지식의 급속한 확장 : 산업 및 기술 분야에서의 지식은 계속해서 확장하고 진화합니다. 기업과 연구 기관은 최신 기술 동향을 파악하고 이를 활용하는 데 어려움을 겪을 수 있습니다.
3. 과학 기반의 의사 결정 강화 : 과학적인 데이터와 분석을 기반으로 한 R&D 과제 선정은 의사 결정의 정확성과 신뢰성을 향상시킵니다. 이로 인해 프로젝트 성공 확률이 높아집니다.
⦿아이디어 요약
1. 산업별 중요 특허 키워드 추출 및 R&D 과제 지원 : 특허 키워드 추천 모델을 활용하여 각 산업 분야에서 중요한 특허 키워드를 추출하고 성능을 분석하여 최적 모델을 선정합니다. 이후, 비슷한 산업 분야에서 R&D 과제를 수행하는 기업에게 성공한 기업들의 중요 특허 키워드를 추천하여 연구와 개발에 도움을 제공합니다.
2. R&D 과제 키워드 네트워크 분석 : R&D 공고 명칭에서 키워드를 추출하고, 이를 이용하여 공고와 관련된 성공한 R&D 과제의 키워드를 연결하여 키워드 네트워크 분석을 수행합니다. 이를 통해 기술 혁신과 연구 과제 간의 관계를 시각화하고, 새로운 아이디어와 협력 기회를 발견합니다.
⦿추진방안
1. 중요한 임무와 목표 기반의 R&D 전략 로드맵 수립 : 임무중심 R&D 프로젝트는 명확한 임무와 관련된 중점 기술을 도출하고, R&D 전략로드맵을 작성하여 목표를 달성하는 방향을 설정합니다.
2. 국가전략과 사회적 우선 순위에 맞는 기술 적용 : 국가의 전략과 사회적 우선 순위에 따라 기술을 적용하여 국가와 기업이 핵심 과제를 해결하고 기술 혁신을 주도합니다.
3. R&D 투자 확대와 제도 개선 : R&D 투자를 늘리고, 예비타당성 조사 등의 제도를 개선하여 프로젝트의 효율성을 높이며 결과물을 구현하는데 도움을 줍니다.
⦿코드 방향성
1. 산업별로 중요한 특허 키워드를 추출하는 모델을 사용하여 성능 분석을 한 후 가장 좋은 모델을 선정해 비슷한 산업에서 R&D 과제를 수행하고 있는 기업에게 R&D과제를 성공한 기업들의 중요한 특허 키워드를 추출하여 시각화합니다.
2. R&D 공고 명에서 키워드를 추출하여 같은 키워드를 가지고 있는 R&D과제 중 성공한 과제의 키워드를 연결하여 키워드 네트워크 분석을 진행합니다.
⦿활용 DB 목록
1. 기업 정보 빅데이터
| ⬛ | 기업정보 요약 | ⬛ | 9. 국가 R&D 과제 |
| □ | 2. 기업정보 상세 | □ | 10. 국가 R&D 성과 |
| □ | 3. 경영진 정보 | ⬛ | 11. 국가 R&D 연구보고서 |
| □ | 4. 신용등급 정보 | □ | 12. 실용신안 정보 |
| □ | 5. 재무제표 정보 | □ | 13. 상표권 정보 |
| □ | 6. 특허정보요약 | □ | 14. 디자인권 정보 |
| ⬛ | 7. 특허정보상세 | □ | 15. 온라인 뉴스 |
| □ | 8. 패밀리특허정보 | □ | 16. 취업포탈 뉴스 |
2. 추가 융합 DB
http://kssc.kostat.go.kr/ksscNew_web/kssc/common/ClassificationContent.dogubun=1&strCategoryNameCode=001&categoryMenu=007&addGubun=no 통계청 - ‘한국표준산업분류’
⦿분석 기법
| □ | Regression | □ | lightGBM | □ | Gradient Boost | □ | AdaBoost |
| □ | DNN | □ | Random Forest | □ | Decision Tree | □ | Naive Bayes |
| □ | SVM | □ | LSTM | □ | K-means | □ | DBSCAN |
| ⬛ | 기타: ( TF-IDF, NetworkX ) | ||||||
1. 데이터 전처리
① ‘특허정보상세_train‘ 데이터에서 ’BusinessNum’이 같은 행의 ‘patentTitle’열의 값들을 리스트로 묶어주었습니다.
② ‘국가R&D연구보고서_train’ 데이터에서 보고서 결과가 있는 ‘ProjectNumber’열과 ‘국가 R&D과제‘ 데이터의 ’ProjectNo’열을 합쳐서 R&D를 성공한 기업의 정보를 통합시킴. 이후 ‘BusinessNum’열이 겹치는 행들의 ‘KeywordKR’열의 값을 리스트로 합쳤습니다.
③ 1번의 ‘BusinessNum’열과 2번의 통합시킨 데이터의 ‘BusinessNum’열이 겹치는 행들을 합친 후 이 데이터프레임과 ‘기업정보요약_train’의 ‘indCd1’열과 ‘indNM’열을 ‘BusinessNum’열로 합쳤습니다. 이 데이터를 앞으로 ‘R&D_특허_합본.csv’로 저장하였습니다.
2. 형태소 분석
① 텍스트 분석을 통해 자연어 처리를 수행하면서 중요한 형태소를 추출했습니다. TF-IDF와 Gensim의 CBOW 및 Skip-gram을 활용하여 문맥과 의미를 파악하고, KeyBERT와 YAKE를 이용하여 핵심 키워드를 도출했습니다. 자체적으로 성능분석을 한 결과 TF-IDF를 이용한 단어의 중요도 파악과 KoNLPy 의 Okt 라이브러리로 빈도분석을 통한 특허 키워드 추출이 가장 정확하다는 것을 체감하고 이를 채택하였습니다.
② 이후 Okt, word2vec, Counterm word_tokenize, nltk 등의 형태소 분석기를 사용하여 ‘R&D_특허_합본.csv’데이터의 ‘indNm’열, ‘patentTitle’열의 값들을 특수문자, 숫자, 1글자 단어, 결측치는 제외하고 토큰화하는 작업을 했고 이를 각각 ‘indNmCounts’, ‘patentTitle_counts’열로 저장했습니다.
3. 미리 선별한 산업 키워드 분류
‘한국표준산업분류’ 사이트에서 정리되어 있는 산업종 중 ‘R&D_특허_합본.csv’의 ‘indNmCounts’열의 키워드들과 비교하여 해당 산업종들을 ‘농업 임업 어업 광업 제조업 전기 가스 증기 공기 공급업 수도 하수 폐기물 원료 재생업 건설업 도매 소매업 운수 창고업 숙박 음식점업 정보통신업 금융 보험업 부동산업 전문 과학 기술 서비스업 사업시설 관리 지원 임대 공공 행정 국방 사회보장 교육 보건업 사회복지 예술 스포츠 여가 가구 자가 소비‘으로 산업 종류 키워드를 분류했습니다.
4. 산업별 특허정보 주요 키워드 분석 – TF-IDF(Term Frequency-Inverse Document Frequency) 사용
① indNmCounts' 열에서 앞서 산업 종류 키워드를 분류한 것 중 특정 단어(해당 보고서의 예시- ’제조업‘)가 포함된 행을 추출하여 새로운 데이터프레임 생성했습니다.
② 해당 데이터프레임에서 'patentTitle_counts'열의 각 행에서 특허 정보 키워드 단어들을 추출하여 ‘vocab’ 리스트에 저장했습니다.
’tqdm‘라이브러리를 불러와 단어 집합(vocab)의 단어를 하나씩 가져온 후 def tf(t, d): return d.count(t) 함수를 사용하여 TF 값을 계산하여 ’result’ 리스트에 추가하고 tf_ = pd.DataFrame(result, columns=vocab)로 새로운 데이터프레임을 만들었습니다.
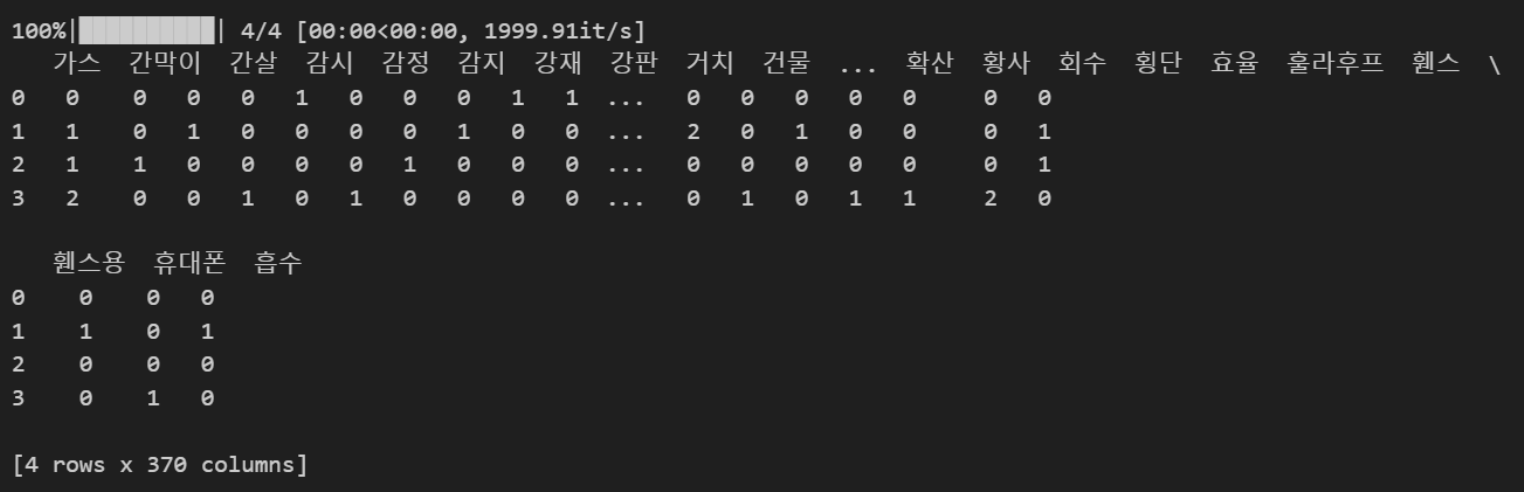
③ 이후 idf값을 계산했습니다. idf값은 모든 특허문서에 해당 단어가 자주 등장하게 된다면 idf의 분모값(한 단어가 모든 특허 문서에서 등장하는 횟수)이 올라가 idf값이 낮아질 것이고, 반대로 모든 특허문서에 해당 단어가 적게 등장한다면 idf값은 높지만 tf(특허당 단어의 빈도수)값은 낮아지기 때문에 추후 tf-idf값이 낮아지기 때문에 가지치기 당합니다. 모든 단어에 대해서 IDF값을 구한 후 ‘idf_’데이터프레임에 저장했습니다.
최종적으로 각 단어에 대해서 TF-IDF 값을 계산하면 각 단어의 TF-IDF 값을 tfidf_df에 저장했습니다.
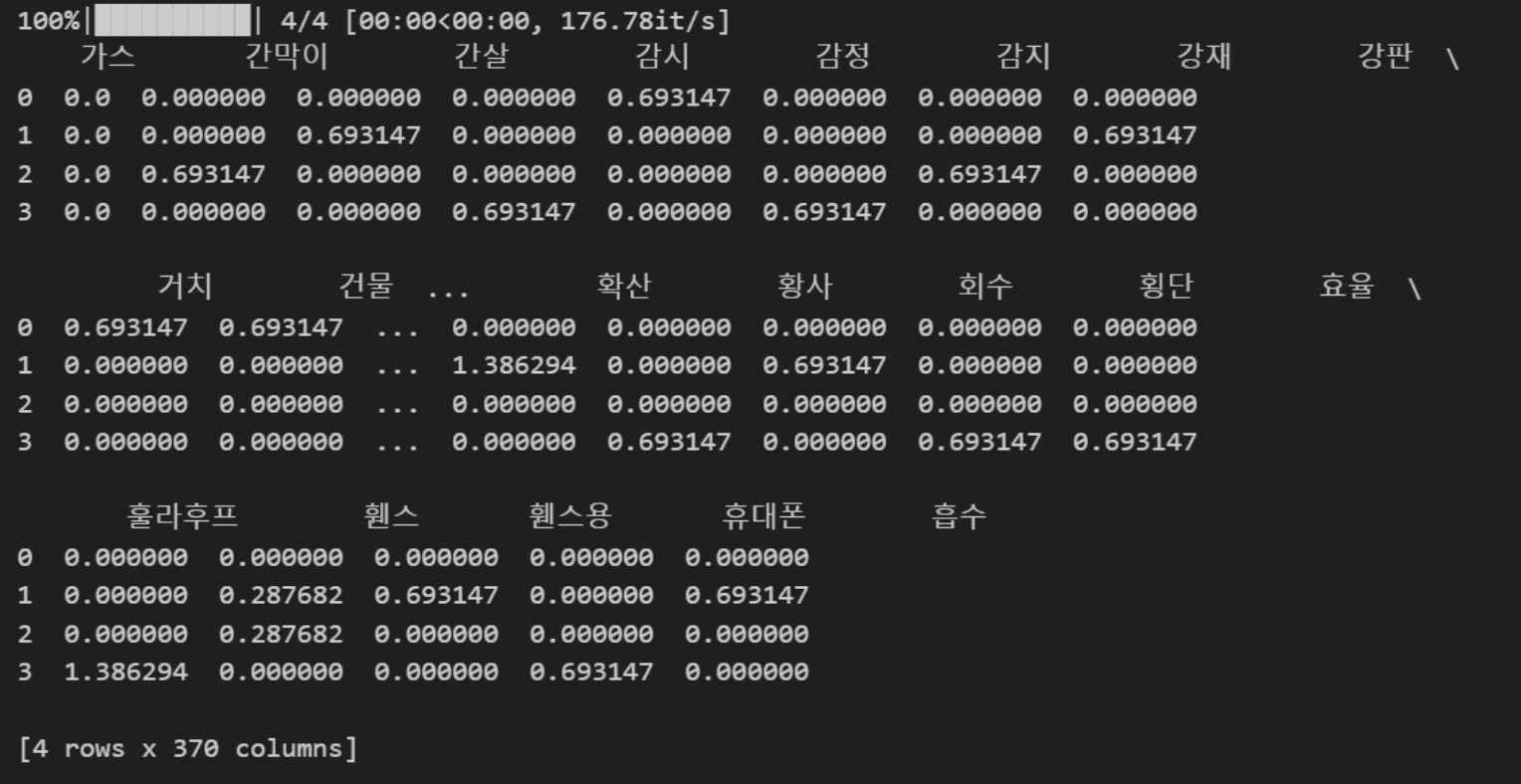
마지막으로 단어별로 TF_IDF를 합친 값이 큰 순서대로 해당 산업에 중요도가 높은 키워드이므로 이를 시각화하였습니다.

6. 네트워크 분석
‘국가 R&D 과제’와 ‘국가 R&D 성과’를 이용하여 R&D공고의 키워드와 성공한 연구의 워드의 관계를 시각화했습니다. ‘국가 R&D 과제’와 ‘국가 R&D 성과’의 결측값을 제거했습니다. ProjectNo를 기준으로 두 개의 데이터를 병합한 후 중복값을 전부 제거합니다. R&D 공고를 나타내는 'BudgetProjectName'을 KoNLPy 의 Okt 이용하여 키워드를 추출하여 BudgetKeyword로 저장합니다. 키워드 추출 이후의 성능향상과정은 공고의 특성 상 필요하지 않아서 수행하지 않았습니다. ‘국가 R&D 과제’의 'KeywordKR'열에 특수문자가 구분자로 포함되어 있어 모든 특수문자를 콤마로 바꾸어주었습니다. BudgetKeyword열과 KeywordKR 열의 값을 콤마로 구분하여 리스트로 저장하고 모든 BudgetKeyword열의 키워드와 KeywordKR 열의 키워드 조합에 대한 빈도수를 계산합니다. 그리고 키워드 2개와 빈도수를 데이터프레임으로 만듭니다. 그리고 NetworkX를 이용하여 공고이름을 입력하면 공고명에서 키워드를 추출하여 관련된 단어들을 시각화하여 보여줍니다.
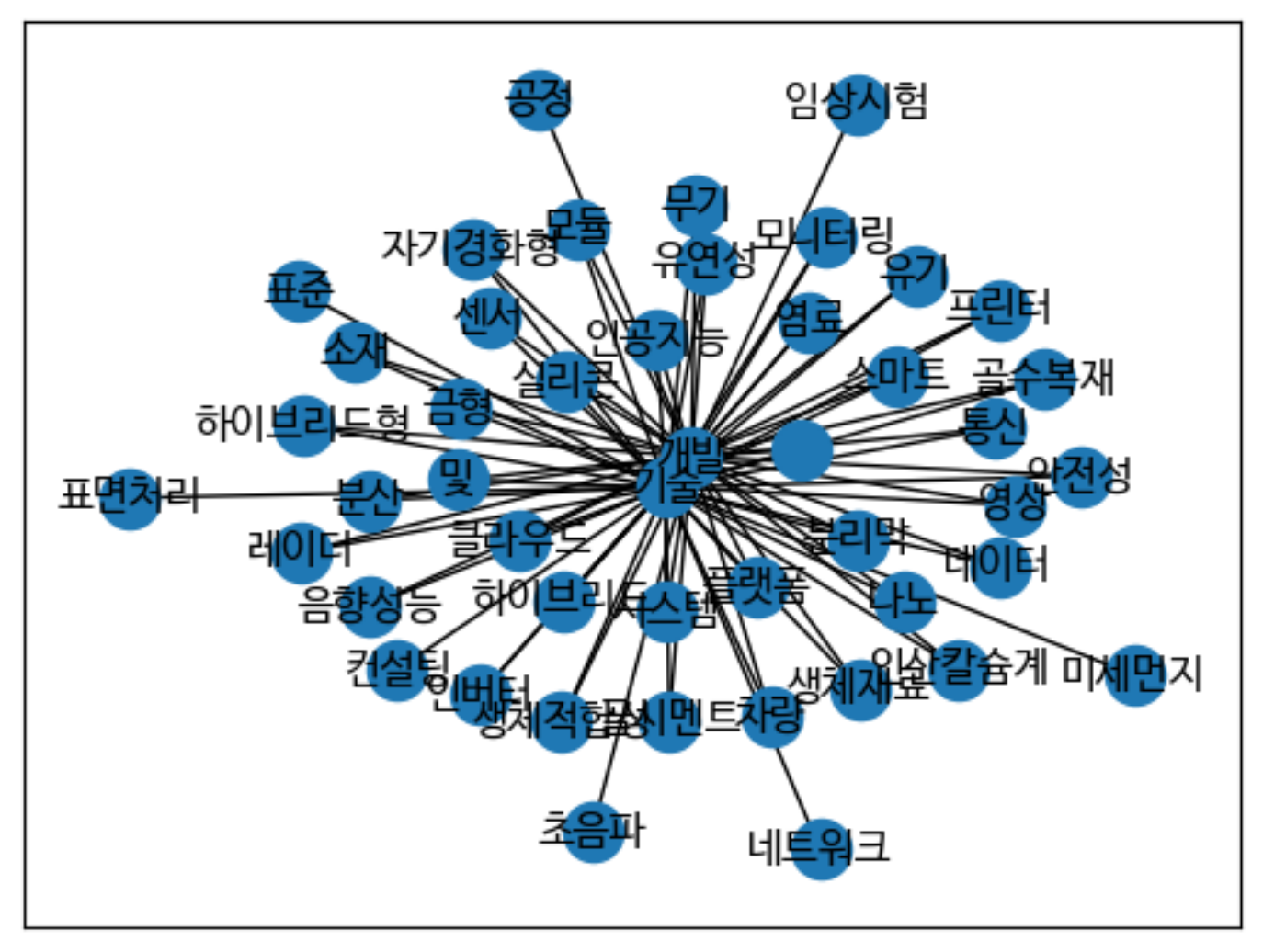
⦿아이디어 활용방안
1. 기업의 R&D 전략 개선 : 이 아이디어를 활용하여 기업은 경쟁사의 성공적인 R&D 과제와 관련된 중요한 특허 키워드를 추출할 수 있습니다. 이를 통해 기업은 자사의 R&D 전략을 개선하고 경쟁력을 강화할 수 있습니다.
2. 연구 및 개발 프로젝트의 효율성 향상 : 이 모델은 유용한 특허 키워드를 추천함으로써 기업이 특정 산업 분야에서의 R&D 프로젝트를 더 효율적으로 수행할 수 있게 도와줍니다. 이는 비용 절감과 연구 시간 단축에 기여할 것입니다.
3. 기술이전 및 협력 기회 찾기 : 특허 키워드 네트워크 분석을 통해 관련 기술이나 협력 기회를 찾는 것이 가능합니다. 다른 기업 또는 연구 기관과의 협력을 통해 기술의 공유와 발전을 촉진할 수 있습니다.
4. 정부 및 연구기관의 R&D 지원 : 정부와 연구 기관은 이 모델을 사용하여 특정 산업분야에서 R&D 자금을 효과적으로 배분할 수 있습니다. 이를 통해 국가의 기술 혁신 및 경제 성장을 지원할 수 있습니다.
⦿기대효과
1. 기술 혁신 촉진 : 이 아이디어를 활용하면 기업과 연구 기관은 중요한 특허 키워드를 신속하게 식별하고 이를 기반으로 혁신적인 기술 개발을 추진할 수 있습니다. 이는 기술 혁신을 가속화하고 경쟁력을 향상시킬 것입니다.
2. 연구 및 개발 효율성 향상 : 특허 키워드 추천 모델을 통해 연구자들은 관련 키워드를 놓치지 않고 효과적으로 연구 주제를 설정할 수 있습니다. 이로써 연구 프로세스의 효율성이 향상되고 연구 성과가 향상될 것입니다.
3. 산업 간 협력 강화 : 특허 키워드 네트워크 분석을 통해 다른 산업 분야에서의 기술 및 지식을 활용할 수 있는 기회를 찾을 수 있습니다. 이는 산업 간 협력을 촉진하고 교차 분야 혁신을 가능케 합니다.
4. 정책 결정 지원 : 정부 및 연구 기관은 이 아이디어를 활용하여 R&D 자금을 효과적으로 할당하고 산업 분야별 기술 혁신을 촉진할 수 있습니다. 이는 국가 경제의 지속적인 성장을 지원할 것입니다.
5. 지식 공유와 기술 이전 : 특허 키워드 추천 모델은 관련 기술과 지식을 공유하고 이전하는데 도움을 줄 것입니다. 이는 기술 생태계의 발전을 촉진하고 기술의 보급과 확산을 도모할 것입니다.
"특허상품 개발을 위한 키워드 추천" 아이디어는 현대 기술 및 연구 생태계에 큰 가치를 제공할 것으로 기대됩니다. 이 아이디어를 구체화하고 구현한다면 기업, 연구 기관, 정부, 그리고 전반적으로 사회적 이익을 추구하는 모든 당사자에게 혁신적인 잠재력을 제공할 것입니다.
'공모전 > DMC 빅데이터 아이디어 오디션' 카테고리의 다른 글
| [2023 DMC 빅데이터 아이디어 오디션] 생존분석 모델을 이용한 국가 RnD 프로젝트의 성공률 예측 (2) | 2023.12.05 |
|---|
