안녕하세요 DMC 1조 입니다. 저희 주제에 대해 소개해드릴게요!
그 전에, 공모전에 대해 간략히 먼저 소개해드릴게요.

공모 주제 : 기업정보를 활용한 아이디어 제안 (자유공모)
심사 및 선발 방법 :
- 서류 서면 평가(8팀 선발) : 아이디어 기획서, 소스코드 제출
- 본선 평가(6팀 선발) : 서류 평가 그대로 본선 평가, 최종 발표팀 선발
- 최종 발표 : 서류 내용 바탕으로 발표자료 준비
제공 데이터 셋 : 10,000개 기업
| 1. 기업정보 요약 | 9. 국가 R&D 과제 |
| 2. 기업정보 상세 | 10. 국가 R&D 성과 |
| 3. 경영진 정보 | 11. 국가 R&D 연구보고서 |
| 4. 신용등급 정보 | 12. 실용신안 정보 |
| 5. 재무제표 정보 | 13. 상표권 정보 |
| 6. 특허정보요약 | 14. 디자인권 정보 |
| 7. 특허정보상세 | 15. 온라인 뉴스 |
| 8. 패밀리특허정보 | 16. 취업포탈 뉴스 |
기업과 관련된 원천 데이터 및 타 데이터와 융합을 통하여 사업화 가능성이 높은 아이디어를 제안하라
위 문장이 저희가 공모전을 하며 맞닥드린 첫 문장이었습니다.(보기만 해도 막막하죠..;;)
주제를 떠올림에 있어 저희 팀의 사고 흐름은 이러합니다.
주제를 보고 : 사업화 가능성이 높은 아이디어? -> 기업들이 우리 아이디어를 써먹어야 해 -> 기업의 문제를 해결할 수 있는? -> 대기업보단 중소기업이 문제가 많겠지 => '중소기업' 타겟
데이터를 보고 : RnD 데이터가 많네 -> 중소 기업도 RnD? -> 문제점이 많아!? -> 중소기업의 RnD를 살리자!!
본격적으로 저희 아이디어에 대해 설명드리겠습니다.

저희 주제는 이렇습니다. 특히 국가 RnD 프로젝트를 맡는 중소기업의 성공률을 예측해보는 것입니다.
추진 배경 및 필요성

1. 연구개발 규모 대비 수익성이 현저히 떨어진다.
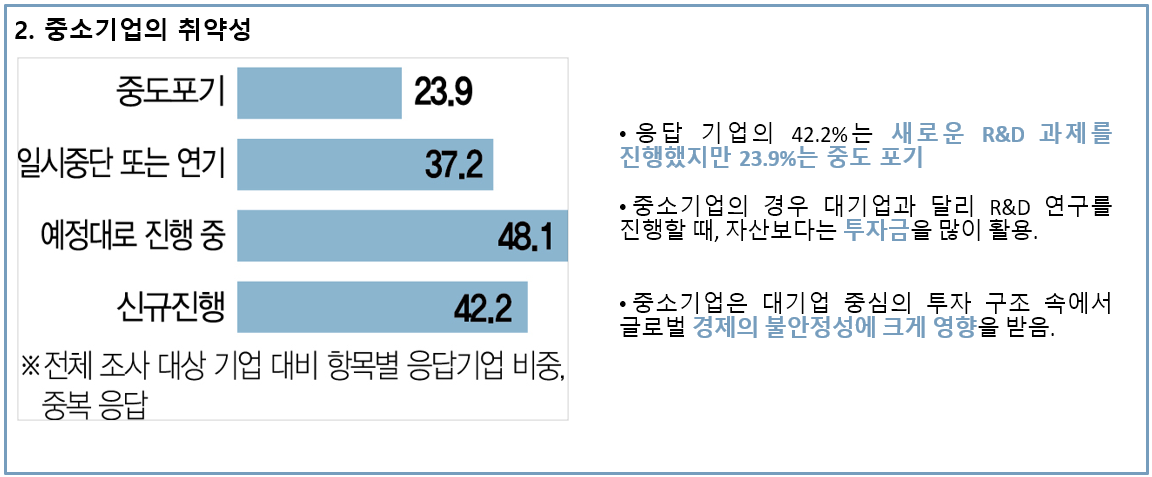
2. 중소기업의 경우 RnD를 진행함에 있어, 자산보다는 투자금을 활용하기 때문에 경제 상황의 영향을 크게 받는다.
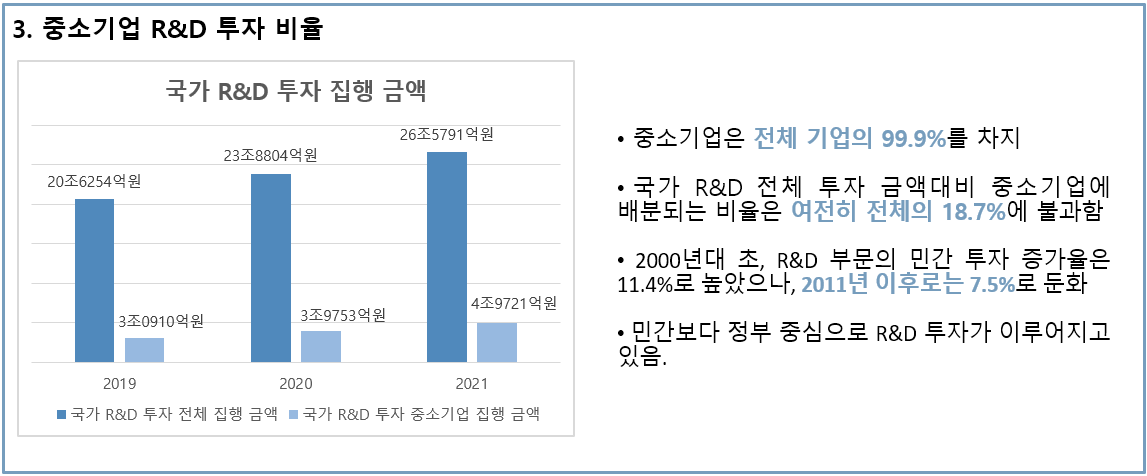
3. 정부 중심의 투자 구조이며, 규모도 적은 편이다.
요악하면, 우리나라의 RnD는 시장성에 맞지 않는 경우가 많아 실속이 없는 상황입니다. 이에 대한 해결책이 중소기업 RnD 의 성장이지만, 대기업 중심의 투자 구조로 인해 중소기업 RnD 성장이 거의 불가합니다.
데이터 전처리
활용한 raw데이터는 다음과 같습니다.
| 1. 기업정보 요약 | 9. 국가 R&D 과제 |
| 2. 기업정보 상세 | 10. 국가 R&D 성과 |
| 3. 경영진 정보 | 11. 국가 R&D 연구보고서 |
| 4. 신용등급 정보 | 12. 실용신안 정보 |
| 5. 재무제표 정보 | 13. 상표권 정보 |
| 6. 특허정보요약 | 14. 디자인권 정보 |
| 7. 특허정보상세 | 15. 온라인 뉴스 |
| 8. 패밀리특허정보 | 16. 취업포탈 뉴스 |

기업의 재무안정성을 구하기 위한 전처리 과정입니다.
1. row 데이터인 재무제표정보 데이터는 동일한 회사 정보가 여러 행으로 구성되어 있는데요. 각 회사당 최신 년도 데이터만 뽑고, accNm 열의 값들을 열로 나타내었고 그 값들을 accAmt(금액) 으로 채웠습니다.
2. 이를 바탕으로 Altman Z-sccore를 통해 재무 안정성을 계산했습니다.
Altman Z-score는 1968년에 개발된 금융 지표로, 기업의 파산 가능성을 예측하기 위해 사용되었는데요, 여기서는 1983년 제시된 revised Altman Z-score 계산 방식을 사용했습니다.

1. 다음은 기업정보요약 데이터 전처리 인데요, BusinessNum와 기업 규모분류, 업종분류의 컬럼을 추출한 후 중소기업만 뽑았습니다.
2. 이 데이터는 업종이 약 631개로 굉장히 세분화되어 있어, 한국표준산업분류표 분류체계의 키워드를 바탕으로 업종을 재분류하였습니다.

RnD, 특허, 상표, 디자인권 등 지식 재산권 데이터 전처리 과정입니다.
각 데이터들에서 제목, 내용 요약, 본문 등 특허 관련 혹은 RnD 관련된 내용에 대해 한 문장으로 병합하였습니다
(RnD 과제 데이터를 예시로 들면, RnD 데이터의 각 컬럼 값을 모두 합쳐 한 문자열로 나타낸 것입니다.)
이러면 한 문자열이 하나의 RnD과제 혹은 지식재산권을 나타내게 되고, 이를 각 회사 별로 정리하여 아래의 전처리 후 데이터를 생성하였습니다.
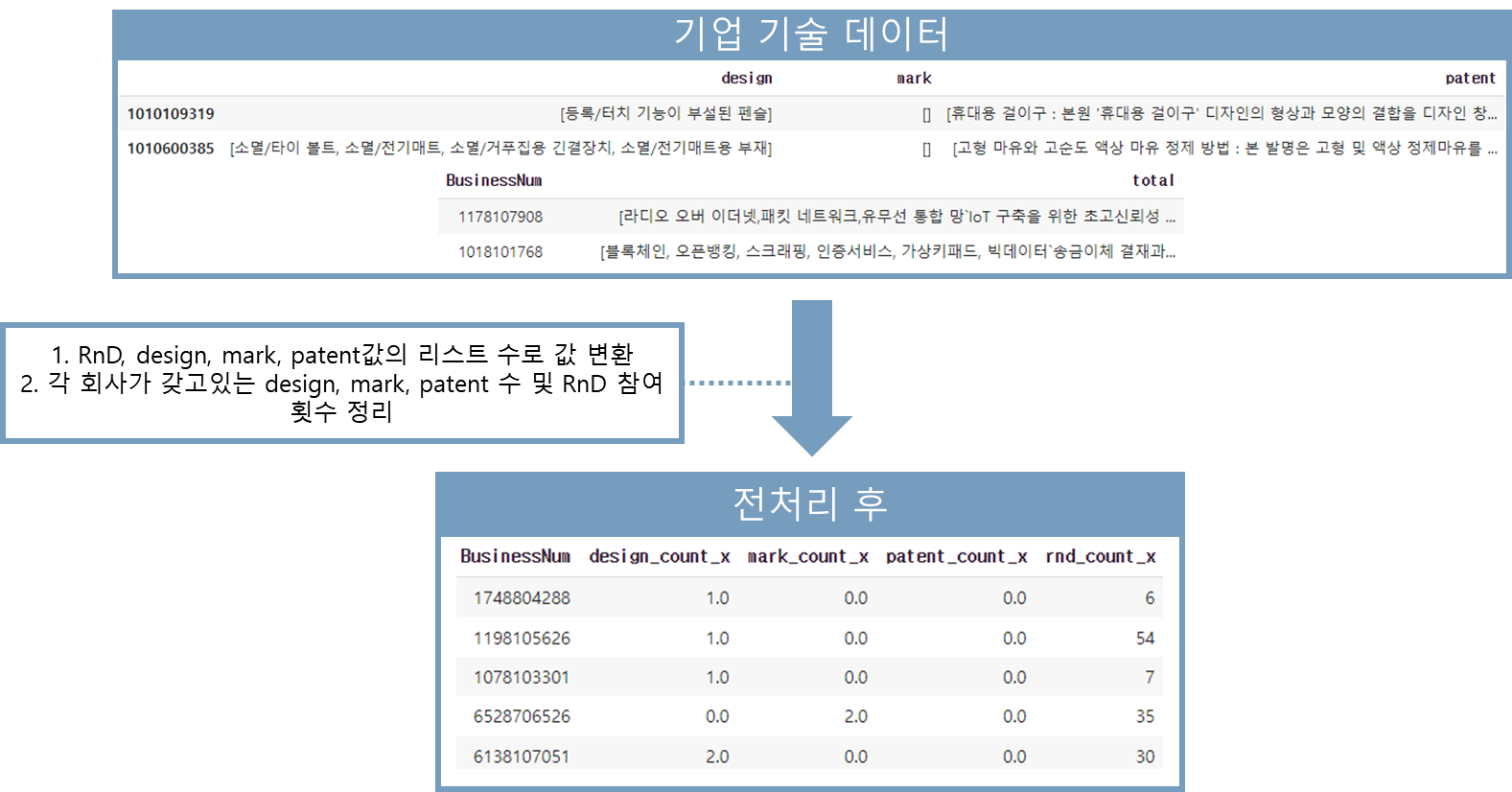
위에서 정리한 기술 데이터를 바탕으로 각 기업이 갖고 있는 지식 재산권의 개수 및 RnD 연구 개수를 count 하였습니다.
(이는 각 기업의 기술 상태에 대한 정량적으로 평가요소가 됩니다.)

앞서 만들었던 정량적 평가로는 RnD 및 지식재산권 기술의 의미를 담기에 부족함이 있어 보였고, 이에 정성적 평가요소를 만들었습니다.
chatgpt api를 활용한 기업 기술 및 RnD의 키워드를 추출
위에서 요약한 모든 문장에 대해, Chat gpt에게 5개 이하의 키워드로 요약해주라고 요구하는 코드를 작성하였습니다.
다음으로, 해당 키워드의 내용들과 RnD과제 제목의 내용을 비교하여 중복되는 키워드에 대해 점수화하였습니다.
(예를 들어, RnD 과제에 ‘가상’이라는 키워드가 존재할 경우, ‘가상’ 키워드를 가진 기업에 1점을 부여하는 방식입니다.)

'국가 RnD 성과', '국가 RnD 연구보고서'라는 raw 데이터에 존재하는 RnD 과제의 경우 RnD의 성공사례로 가정하였습니다.(즉, RnD 리스트의 RnD과제들 중 위 데이터에 있는 과제들은 연구에 성공한 과제들인 것입니다.)
> RnD 성공여부 정리 : 성공은 1, 실패는 0으로 표시하였습니다.
> RnD 총 연구기간 정리 : 각 RnD 과제에 대해 시작날짜와 끝 날짜를 정리하였습니다.
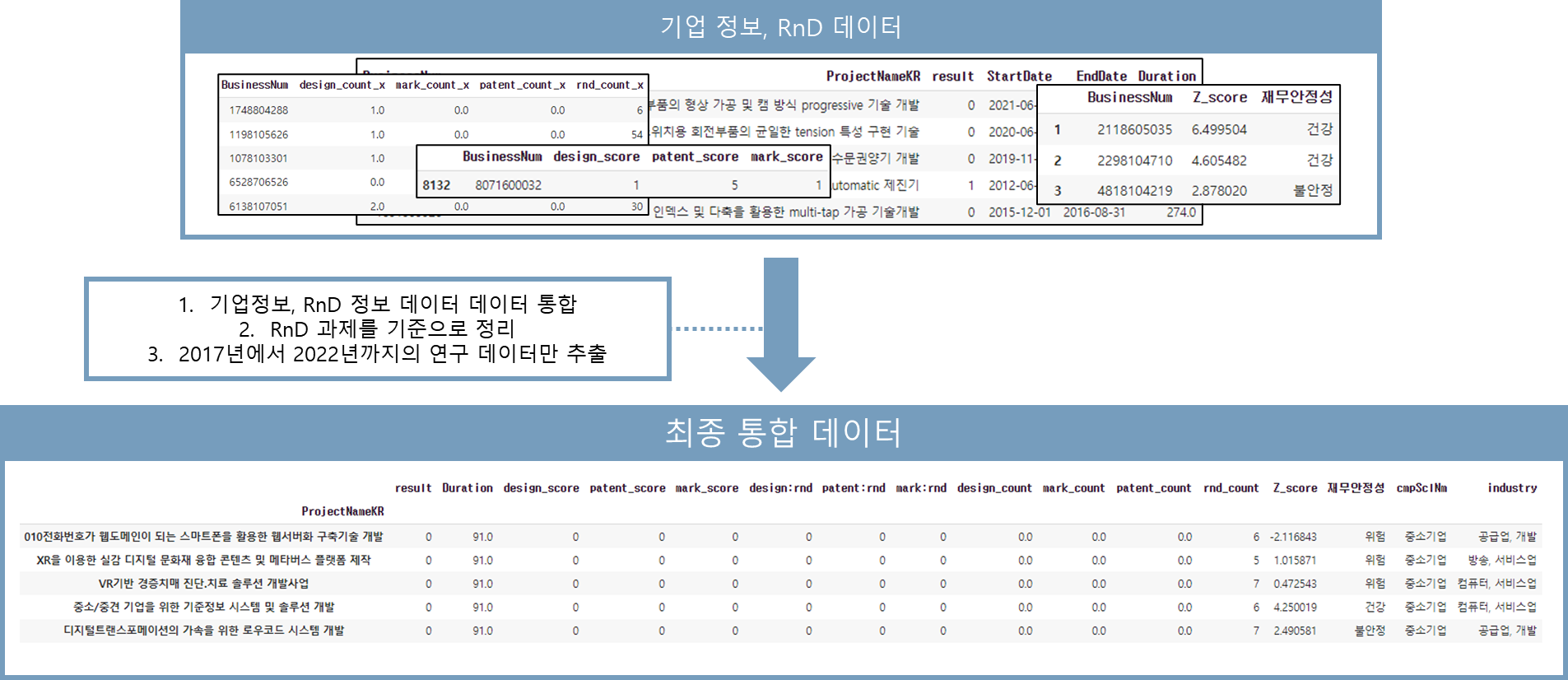
1. RnD 과제를 기준으로 정리하였고, RnD 과제 데이터에서 해당 RnD를 수행한 기업의 정보를 병합하는 방식으로 데이터를 생성하였습니다.
2. 최종 데이터들 중 생존분석을 위해 2017년부터 2022년의 데이터만 추출하였습니다.
최종 데이터의 컬럼
| 컬럼 | 설명 |
| result | rnd 성공 여부 |
| duration | 연구의 총 기간 |
| ~~ score | rnd제목과 각 특성의 키워드가 겹치는 것이 있는지 여부 |
| ~~ : rnd | rnd 내용 키워드와 나머지 키워드중 겹치는 것이 있는지 여부 |
| ~~ count | 지식재산권 개수 및 rnd 참여 연구 개수 |
| Z score, 재무안정성 | 기업의 재무안전성에 대해 나타난 데이터 (건강(2), 불안정(1), 위험(0)의 세 지표) |
피쳐 엔지니어링

피쳐 엔지니어링(Feature Engineering)은 머신 러닝에서 중요한 과정 중 하나로, 주어진 데이터를 분석하고 모델의 성능을 향상시키는 데 유용한 피쳐(특성)를 생성, 선택, 변환하는 과정입니다.
통합된 데이터의 각 컬럼들의 상관관계를 살펴본 결과, 왼쪽 Initial Heat Map과 같이 나타나게 됩니다.
피쳐 선택 과정은 다음과 같습니다.
1. 상관계수가 높은 컬럼 쌍 정리 : (design:rnd, design_score), (mark:rnd, mark_score), (design_score, mark_score) 중 "~~:rnd" 꼴인 컬럼들을 제거
2. 상관계수가 없는 컬럼 제거 : 'patent_score', 'patent:rnd' 제거
그 결과 오른쪽과 Adjusted heatmap이 나오게 됩니다.
생존 분석
생존분석이란 사망, 기계 고장 등의 이벤트 발생까지의 시간을 분석하고 생존함수 및 위험함수를 바탕으로 특정 기간동안의 사건 발생확률을 예측하는 분석법입니다.
의학 분야에서 활용되었던 모델이나, 저희는 위 분석을 기업 RnD 성공 여부에 적용해보았습니다. 이를 위한 예측 모델로써 Random Survival Forest와 Gradient Boosting Survival Analysis 두 모델을 비교하였습니다.
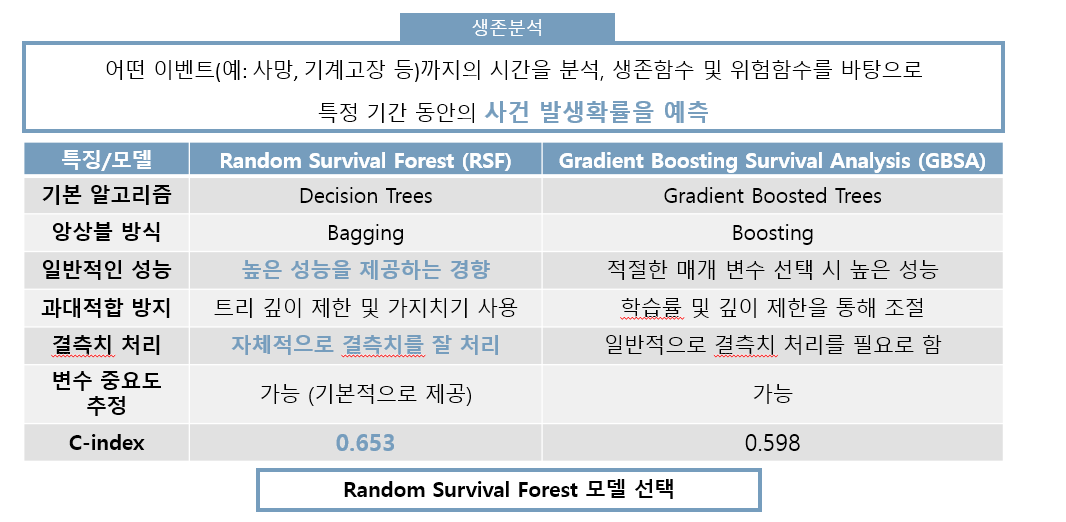
알려져 있는 모델의 성능 및 실제 성능 수치로써 C-index를 비교해본 결과 Random Survival Forest 모델을 선택하게 되었습니다.
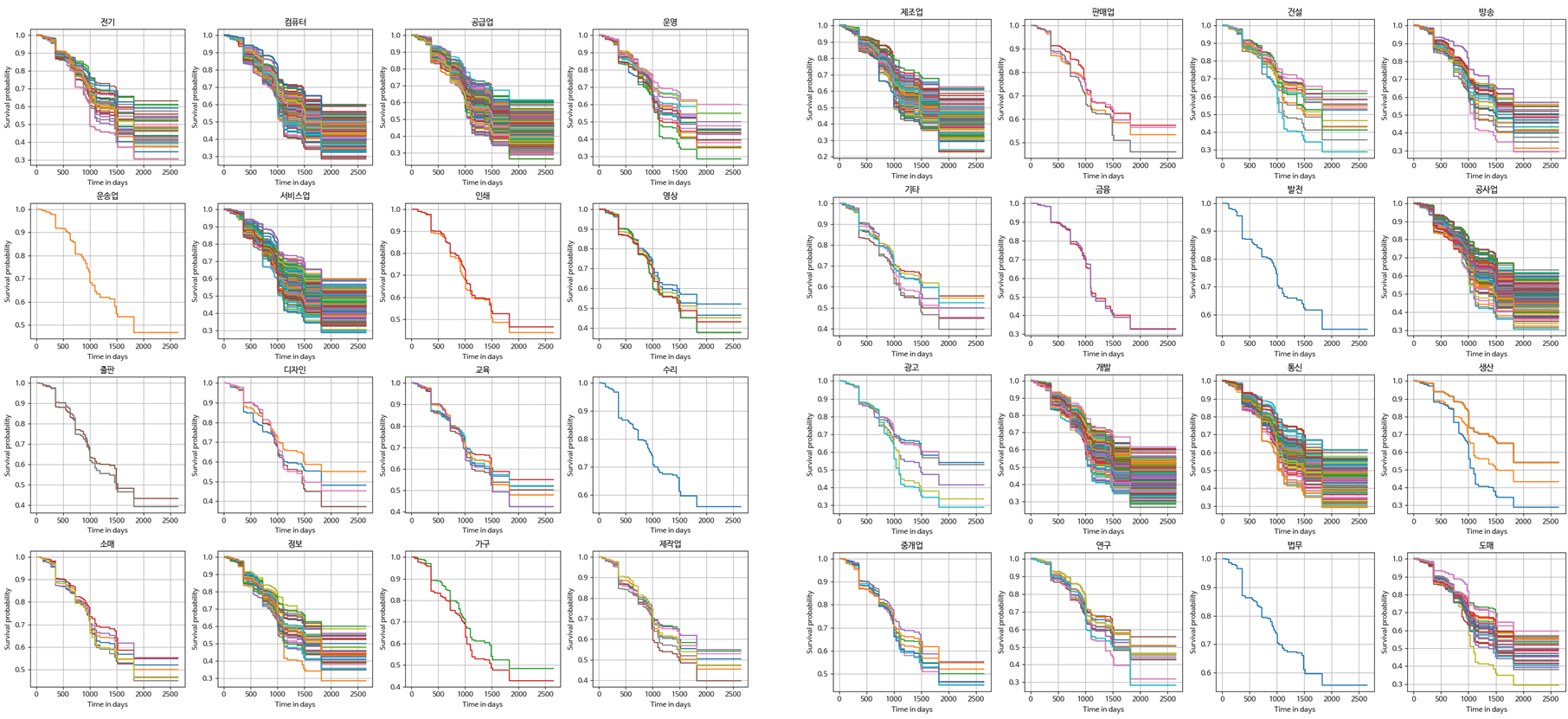
기업 업종 분류별로 나타낸 32개 종류 기업의 2017년 - 2022년 동안 RnD 과제 생존률을 나타낸 그래프입니다.
'출판' 기업의 예시로 설명을 이어가겠습니다.
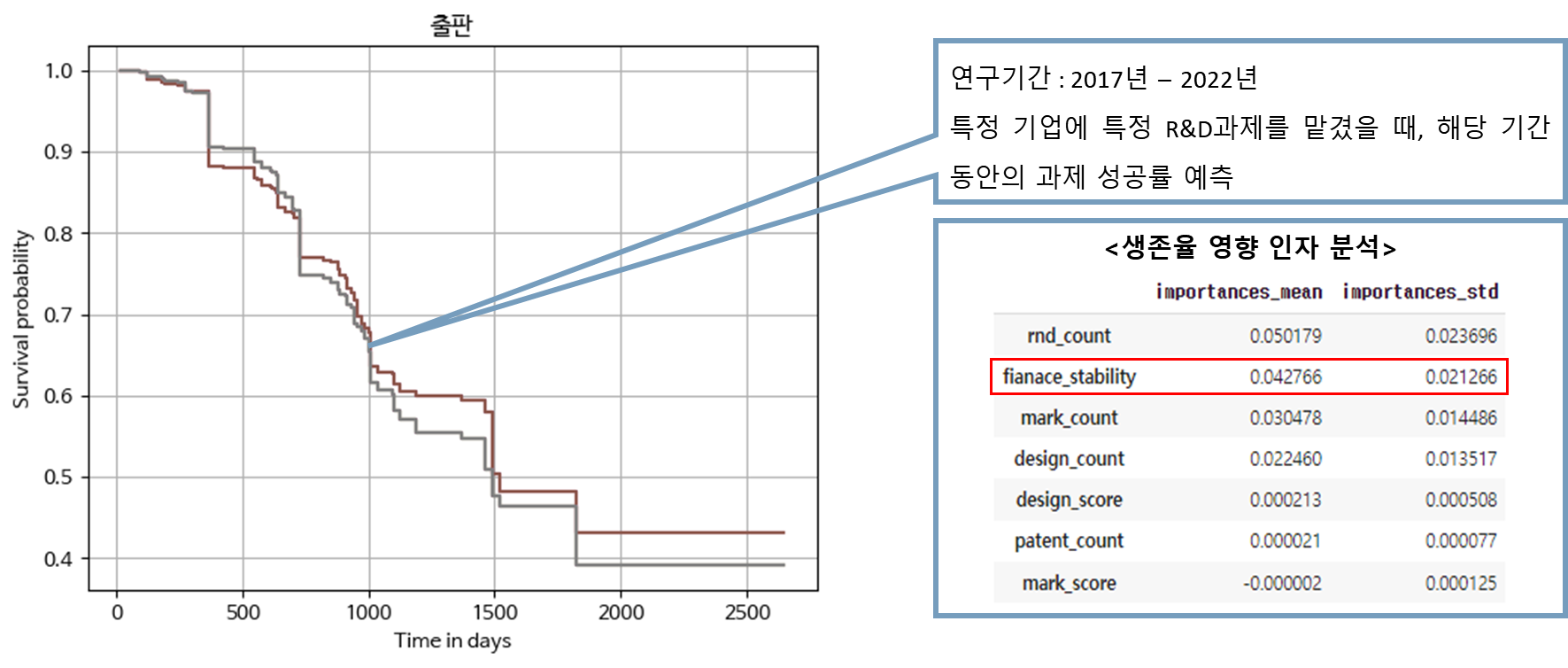
1. 그래프
y축은 생존 확률 즉, RnD 과제가 성공할 확률이며 x축은 프로젝트를 진행하는 일 수입니다. 그래프의 추이를 통해 시기별로 생존률이 급감하는 시기를 예측해볼 수 있습니다.
2. 생존율 영향 인자 분석
rnd_count 즉, 과거 RnD 과제 수행 수를 제외하고 재무 안정성이 가장 높은 영향 요인이었습니다. rnd_count의 경우 당장 수행한 rnd 과제 개수를 늘릴 수 없느데 반 해, 재무 안전성의 경우 외부 투자만 있다면 언제든 개선될 수 있는 수치입니다.
위 분석을 바탕으로, RnD의 성공 확률이 낮아지는 시기에
유효한 투자를 유치하여 중소기업 RnD 과제의 성공 가능성일 높일 수 있습니다.
지금까지 '생존분석 모델을 이용한 국가 RnD 프로젝트의 성공률 예측'을 주제로 한 저의 연구에 대해 소개해 드렸습니다.
긴 글 읽어주셔서 감사합니다...^^
'공모전 > DMC 빅데이터 아이디어 오디션' 카테고리의 다른 글
| 특허상품 개발을 위한 키워드와 추천텍스트마이닝을 활용한 특허 트렌드 분석 (0) | 2023.11.27 |
|---|
