분류모델의 기초
[1주차]
작성일자: 2024-03-11
팀 구성원: 도우진, 오소민,오현정,정원준,최준헌
1. 1. 1 Scikit-learn 소개
Scikit-learn의 개념
-> Scikit-learn은 파이썬을 대표하는 머신러닝 라이브러리로, '사이킷런'이라고도 부른다. 이 라이브러리는 오픈 소스로 공개되어 있어 누구나 무료로 사용할 수 있다.
Scikit-learn의 기능
1. Classification(분류)
-> 객체가 속한 카테고리를 구분한다.
ex) 물건을 구매할지 안할지, 광고를 클릭할지 안할지 등 구분할 수 있는 값들을 분류로 예측

2. Regression(회귀)
-> 객체와 연관된 연속형 값 속성을 예측한다.
ex) 얼마를 구매할지, 광고의 효율이 어느 정도 나올지 등을 특정 수치로 예측
* Classification(분류) 알고리즘은 명칭이 주로 Classifier로 끝나지만,
Regression(회귀) 알고리즘은 명칭이 주로 Regressor로 끝난다.
cf) Supervised learning과 Unsupervised learning의 차이점
- Supervised learning
-> 정답이 있는 데이터를 맞춘다.
ex) Classification, Regression
- Unsupervised learning
-> 정답이 없는 데이터를 맞춘다.
ex) Clustering, Dimensionality reduction
3. Clustering
-> 유사한 개체를 세트로 자동 그룹화한다.
4. Dimensionality reduction
-> 고려해야 할 무작위 변수의 수를 줄인다.
5. Model section
-> 매개변수와 모델을 비교, 검증 및 선택한다.

6. Preprocessing
-> 특징을 추출하고 정규화한다.

올바른 알고리즘 선택하기

위와 같은 그림을 참고하면 사용하고자 하는 용도, 데이터의 종류, 샘플의 크기 등에 따라 알맞은 알고리즘을 선택해 사용할 수 있다.
1.1.2 사이킷런 활용 흐름
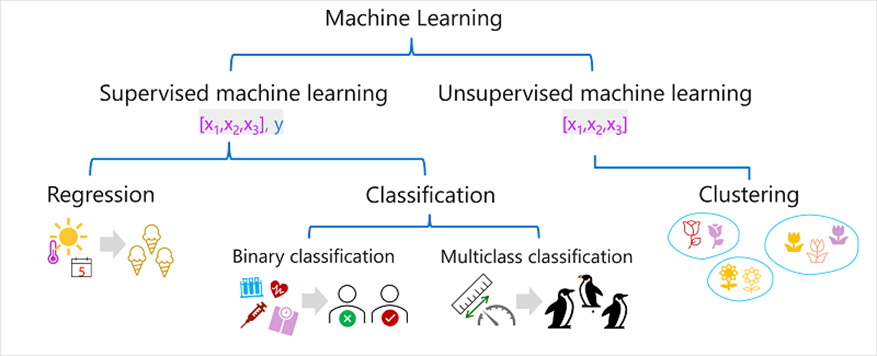
● 지도학습(Supervised Machine Learning)과 비지도학습(Unsupervised Machine Learning) 소개
머신 러닝 알고리즘은 지도학습(Supervised Machine Learning)과 비지도학습(Unsupervised Machine Learning)으로 나뉜다.
지도학습은 학습 데이터에 기능값과 레이블 값이 모두 포함된 기계 학습 알고리즘 용어이다.
기능값은 데이터의 특징이나 속성을 나타낸다. 레이블값은 목표 변수 또는 예측하려는 값이다.

다음 데이터를 활용하여 'study_hour' 에 따라 'grade'를 예측하고자 할때 기능값이 study_hour이고 grade가 레이블 값이다.
지도학습 프로세스는 아래와 같다.

<지도학습 프로세스>
1. Training Data와 Training Labels가 모델에 입력되어 학습된다
2. 모델이 잘 학습되었는지 확인하기 위해 따로 준비된 Test Data를 예측에 활용한다
3. Test Labels 로 예측한 결과가 잘 나왔는지 평가한다
실습에서는 주로 트리 계열 모델을 사용한다.
1. 먼저 모델 객체를 정의한다
#모델 객체 정의하기
model= RandomForestClassifier()
2. 모델객체.fit() 함수를 사용하여 모델 학습을 시킨다
단, 학습데이터와 정답지를 주며 알려줘야한다
#모델 학습시키기
model.fit(X_train,y_train)X_train: Training Data(학습 데이터)
y_train: Training Labels(학습 정답지)
3. 모델로 예측해보기
#예측하기
y_pred=model.predict(X_test)따로 분리해둔 Test Data로 예측 결과를 저장한다
4. 모델 평가하기
테스트 데이터와 정답지를 주며 모델의 성능을 평가한다
#모델 평가하기
model.score(X_test,y_test)
<지도학습의 종류>
1) 회귀: 모델에서 예측한 레이블이 숫자값인 기계 학습의 한 형태
EX) 온도, 강우량 및 풍속에 따라 지정된 날에 판매되는 아이스크림 수
2) 분류: 레이블이 분류 또는 클래스를 나타내는 학습의 한 형태
# 이진분류: 참 또는 거짓으로 레이블을 결정 + 상호 배타적인 두가지 결과 중 하나를 예측
EX) 은행 고객이 소득, 신용 기록, 연령 및 기타요인에 따라 대출을 기본값으로 설정할지 여부(참 또는 거짓)
#다중 클래스 분류: 여러 클래스 중 어느 클래스에 속하는지 고르는 문제
EX) 여러 식물 데이터를 입력받아 어떤 식물 종인지 분류하기
비지도 학습은 레이블 없이 기능값으로만 구성된 데이터를 사용하는 알고리즘이다.
즉, 지도학습과 달리 Test Data(정답 데이터)가 없다는 것이다.
비지도 학습 프로세스는 아래와 같다.
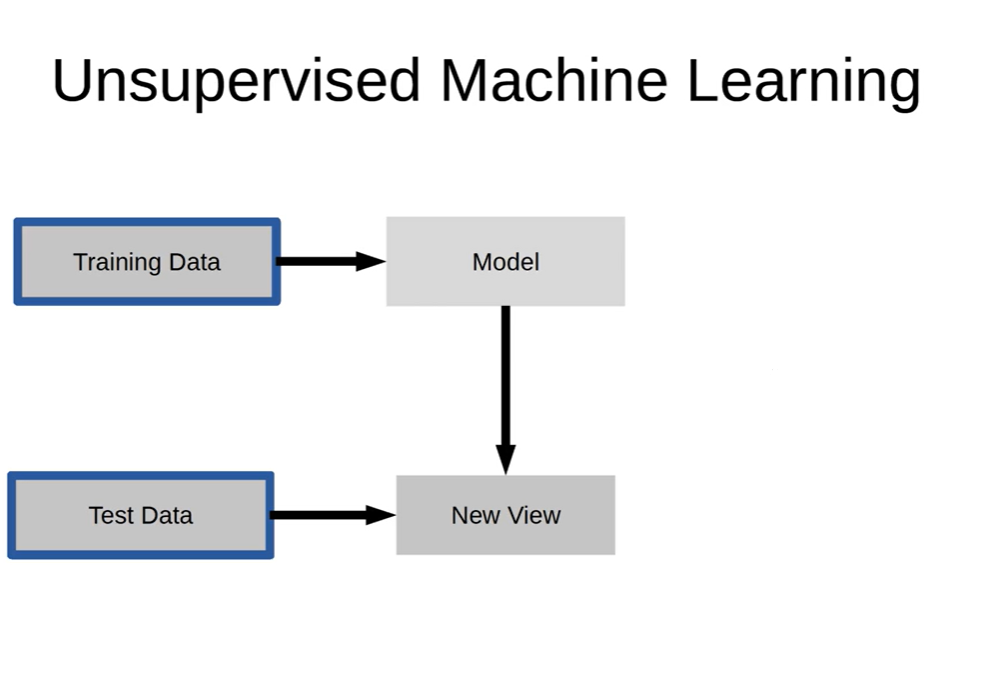
<비지도학습 프로세스>
1. Training Labels 없이 Training Data로 모델을 학습시킨다
2. 학습 모델을 활용하여 Test Data로 새로운 시각 자료를 얻는다
<비지도 학습의 종류>
1. 클러스터링
기능에 따라 관찰 간의 유사성을 식별하고 개별 클러스터로 그룹화한다
EX) 크기, 잎, 수 에 따라 비슷한 꽃을 그룹화한다
2. 차원축소
주로 PCA() 모델 객체를 사용하여 학습함
● 데이터 분할을 위한 Cross Validation(교차 검증) 소개
모델을 학습시킬 때 Training Data와 Test Data로 나눈다고 했는데 이 역시 형성 규칙이 있다.
Cross Validation(교차 검증)은 여러개의 Fold로 데이터를 분할하여 나누고, 각각 부분 집합을 사용하여 모델을 반복적으로 학습 및 평가하는 과정이다.
< Cross Validation 프로세스>
1. 우선 데이터를 여러개의 부분 집합으로 나눈다.
: 주로 k-fold cross validation으로 데이터를 k개의 동일한 크기로 나눈다

2. 학습 및 검증
: 나누어진 데이터 중 하나를 Test Data로 선택하고 나머지를 Training Data로 사용하여 모델을 학습시킨다.

3. 여러가지 경우의 수로 나눠서 2번 과정을 반복한다

4. 성능 측정
:각 반복 파트에서 모델의 성능을 측정한다.
가장 점수가 높은 모델을 선택한다.
● 트리 계열 모델의 이해
마지막으로 트리 계열 모델을 이해할 필요가 있다. 트리 계열은 Decision Tree와 이를 보완하기 위해 만들어진 Random Forests 가 있다.
1. Decision Trees(의사 결정 트리)
- 특정 기준(질문)에 따라 데이터를 구분하는 모델을 결정 트리 모델이라고 한다
- 가지치기를 통해 max_depth나 min_sample_split 옵션을 조정할 수 있다

그러나 트리에 너무 가지가 많으면 Overfitting이 발생 할 수 있다.
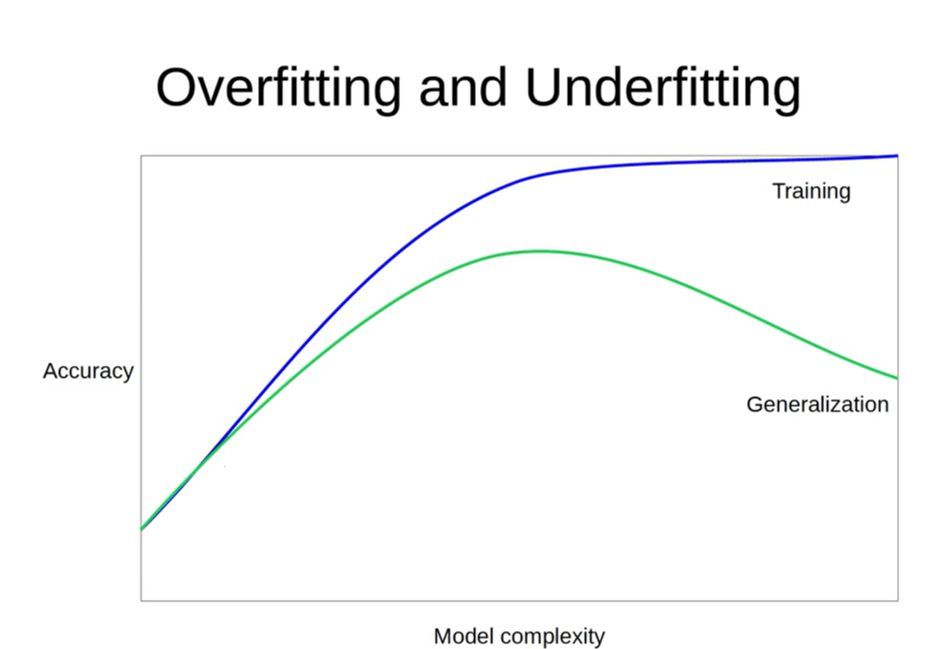
그럼 Overfitting이 무엇일까?
위 그래프에서 볼수 있듯이 Underfitting은 학습 성능이 낮은 부분이고 Overfitting은 학습 성능이 높은 부분이다.

Underfitting 상태에서는 빨간색과 파란색 구역이 잘 구분이 안된 반면

Overfitting 상태에서는 구분이 잘 된 것을 알 수 있다.
다만, Training Data에 익숙해진 모델이 Test Data가 들어오면 제대로 예측을 하지 못할 때도 있다.
따라서 Underfitting과 Overfitting 사이에 적절한 Sweet spot을 찾아주는게 중요하다
2. Random Forests (랜덤 포레스트)
따라서 위 한계를 해결하기 위해 Random Forests는 Decision Tree(의사결정나무)를 여러개 만들어 더욱 강력한 모델을 형성하려고 한다. 각 결정 트리는 부트스트랩 샘플링을 통해 학습한다. 각각 트리가 독립적으로 예측한 결과를 종합하여 Majority Voting을 통해 가장 성능이 좋은 클래스로 최종 예측을 수행한다.다만 Random forests도 트리 기반 알고리즘이어서 적절한 max_depth를 찾아주는게 중요하다.

1.1.3 의사결정 나무 알고리즘에 관한 설명
사이킷런으로 의사결정나무 모델 만드는 방법 소개
사이킷런으로 간단한 의사결정나무 모델 학습하기
from sklearn import tree
X = [[0, 0], [1, 1]]
Y = [0, 1]X에 [0, 0]이 들어오면 결과값인 Y가 0, X가 [1, 1]일 때에는 Y가 1을 가지도록 값을 설정했다.
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)clf.fit(X, Y)를 실행함으로써 위의 X를 넣었을 때 Y가 나오는 것을 보고 DecisionTreeClassifier가 학습을 한다.
>>> clf.predict([[2., 2.]])
array([1])[0, 0]일 땐 0, [1, 1]일 땐 1 이라는 데이터로 학습을 해서 [2., 2.]라는 값을 모델에 넣어줬더니 1이라는 값을 예측했다.
>>> clf.predict_proba([[2., 2.]])
array([[0., 1.]])predict_proba는 각 클래스에 대한 확률을 출력한다. 확률을 출력하므로 당연히 결과값은 0과 1 사이의 값이며, 두 클래스의 합은 1이다.
Iris 데이터셋을 이용한 의사결정나무 모델 학습하기
그러면 이제 사이킷런에 내장된 다른 데이터셋을 이용하여 DecisionTreeClassifier를 사용해보자.
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)이 코드는 iris라는 붓꽃 관련 데이터를 불러와 DecisionTreeClassifier를 학습하는 과정을 나타낸다.
이 붓꽃 데이터를 간략하게 소개하자면 다음과 같다.
- 꽃받침(sepal)의 길이
- 꽃받침의 너비
- 꽃잎(petal)의 길이
- 꽃잎의 너비
Iris 데이터셋의 각 샘플은 이 네 가지 특징에 대한 수치와 그에 해당하는 붓꽃의 품종으로 구성되어 있다.
학습을 한 뒤 붓꽃의 품종을 예측하기 위함이다.
그러면 각 코드가 어떤 역할을 하는지 보다 자세히 알아보자.
from sklearn.datasets import load_iris
from sklearn import tree
X, y = load_iris(return_X_y=True)
X, y이 코드는 교육 영상에서 나온 코드이다. 이 코드를 실행하면 iris데이터셋이 어떻게 이루어져있는지 알 수 있는데,
먼저 X, y = load_iris(return_X_y=True) 가 실행되면, return_X_y=True에 의해서 iris에 들어있는 특징 데이터와 타겟 데이터를 각각 X와 y에 할당된다.
그래서 X에는 각 샘플의 네 가지 특징에 대한 수치를 나타내고 있고, y에는 각 X마다의 품종이 0, 1, 2으로 구분되어 있다.
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)DecisionTreeClassifier를 학습시키는 코드이다. 이전 코드에서 X와 y에 각각 특징 수치와 타겟 데이터를 할당했으므로, clf.fit(X, y)를 통해 X값에 매칭되는 y의 값을 통해서 새로운 X값을 받았을 때 y값(붓꽃의 품종)을 예측할 수 있도록 학습한다.
의사결정나무 모델의 그래프 알아보기 - pyplot
그러면 학습된 모델의 알고리즘. 그래프를 보자.
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
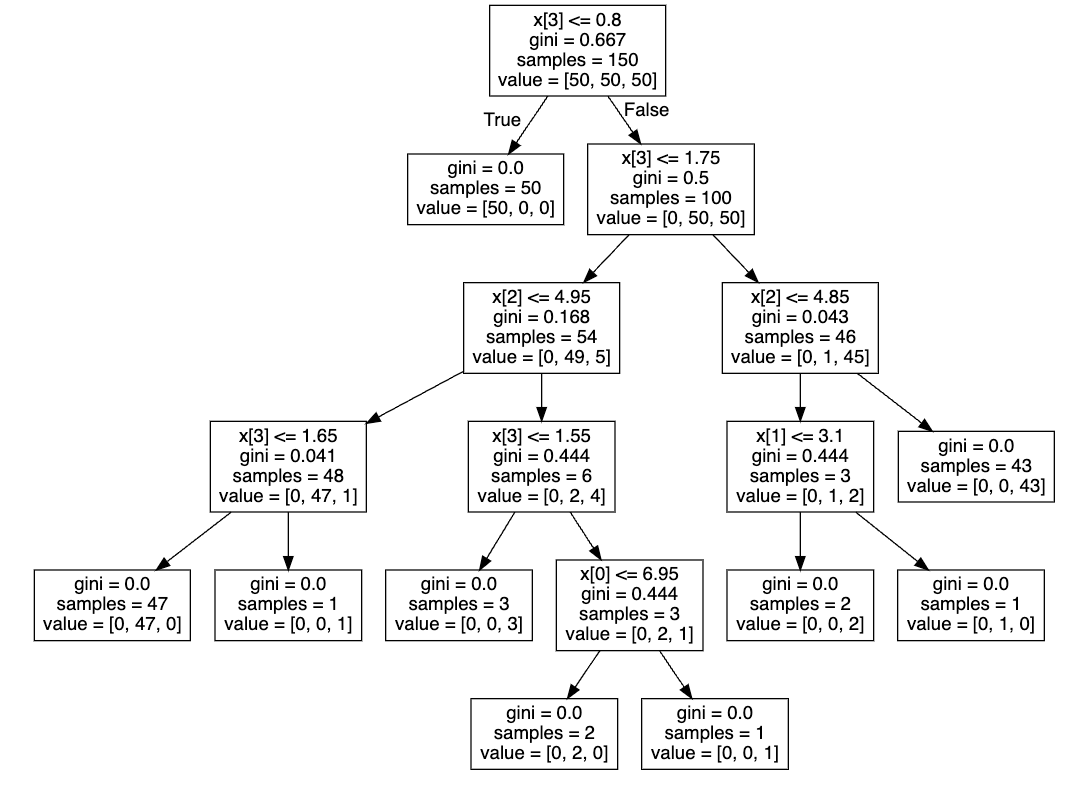
t = tree.plot_tree(clf, filled = True)위 코드를 입력하면 영상에서 봤던 그래프가 나온다.

맨 위 항목에서부터 X[3] <= 0.8 라는 조건에 True/False를 통해 샘플을 나누어 확률을 배정해 갈래가 뻗어나가는 구조가 의사결정나무 모델이다.
의사결정나무 모델의 그래프 알아보기 - graphviz
영상에는 잠깐 나오고 직접 하는 것은 보여주지 않았던 그래프비즈를 활용해 Tree 그래프를 도출해보자.
!apt-get -qq install -y graphviz && pip install -q pydot
import pydot
!apt-get install graphviz libgraphviz-dev pkg-config
!pip install pygraphviz
import pygraphviz구글링해서 찾은 구글 코랩에서 그래프비즈를 사용하기 위한 설치 코드이다.
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("iris")그래프 비즈의 설치가 끝난 뒤 그래프비즈를 불러와 의사결정나무를 그래프로 나타내보자. dot_data라는 변수에 그래프의 데이터를 넣고 ( 이때 데이터는 Graphviz DOT 형식으로 바뀐다.), graph라는 변수에 그래프를 시각적으로 표현할 수 있는 객체를 저장했다. 이후 render 명령어를 통해 iris라는 파일명을 지정했으므로 iris.pdf로 저장된다. 출력을 하고싶다면 graph.render("iris")가 아닌 그냥 graph를 불러내면 볼 수 있다.
그리고 이 그래프가 너무 보기 안 예쁘다면 꾸며줄 수도 있다.
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph이 코드를 이용해 그래프를 출력하면 다음과 같이 생겼다.

1.2.1 당뇨병 데이터셋 소개
Kaggle에서 제공하는 Pima Indians Diabetes Database를 활용하여 분류 모델을 직접 실행해보자.
Datasets은 다음 링크로 들어가 로그인 한 후 다운받아 사용하면 됩니다.
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com
cf. Sklearn에서도 다음과 같이 데이터셋을 제공하고 있지만 행의 개수가 442개로 Kagggle의 768개보다 작으므로 Kaggle 데이터셋을 활용하는 것을 추천한다.
sklearn.datasets.load_diabetes
Examples using sklearn.datasets.load_diabetes: Release Highlights for scikit-learn 1.2 Gradient Boosting regression Plot individual and voting regression predictions Model Complexity Influence Mode...
scikit-learn.org
Pima indains는 현재 애리조나 중부와 남부, 멕시코 북서부 소노라주와 치와와주에 걸쳐 있는 지역에 살고 있는 아메리카 원주민들이다. Pima indains는 세계에서 2형 당뇨병 유병률이 가장 높은 집단 중 하나로 다른 미국 인구 그룹에서 관찰되는 것보다 훨씬 높은 수준이다. 다른 인구 그룹보다는 위험도가 높지 않지만, 피마족은 동질적인 집단을 형성하고 있어서 당뇨병 연구의 중요 대상이 되었다. 아메리카 원주민의 당뇨병 유병률이 일반적으로 증가하는 것은 1984년 인류학자 로버트 페렐(Robert Ferrell)이 제안한 것처럼 유전적 소인(검소한 표현형 또는 검소한 유전자형)과 지난 세기 동안 전통적인 농작물에서 가공 식품으로의 급격한 식단 변화, 신체 활동 감소의 상호작용의 결과로 가설이 제기되어 왔다. 이 데이터는 이러한 pima indians들의 당뇨병과 관련된 데이터들이 정리되어 있는 데이터셋이다. 구체적으로 어떤 데이터들로 구성되어 있는지 다음을 통해 알아보자.
데이터 구성
이 데이터셋은 여러 의료 예측 변수(독립 변수)와 하나의 목표 변수(종속 변수)인 결과(Outcome)로 구성되어 있다. 총 768개의 데이터가 있고 하나씩 자세히 살펴보자면 다음과 같다.
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml), 0이 많은데 결측치에 가까운 수치이다.
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 당뇨병이 아닌 사람은 0, 당뇨병인 사람은 1로 표현되어 있다. 768개 중에 268개의 결과 클래스 변수가 1이고 나머지는 0이다.
1. 2. 2 학습과 예측을 위한 데이터셋 만들기
1. 필요한 라이브러리 로드하기
import pandas as pd # 데이터 분석 및 불러오기
import numpy as np # 수치 계산
import seaborn as sns # seaborn 로드 (시각화)
import matplotlib.pyplot as plt # matplotlib 로드 (시각화)
%matplotlib inline ## 구버전 Jupyter notebook의 경우 시각화가 표시되지 않을 때 설정
데이터 분석 및 불러오기 용 라이브러리와 수치 계산용 라이브러리, 시각화 라이브러리를 로드한다.
구버전 Jupyter notebook의 경우 시각화를 보기 위해서는 %matplotlib inline을 지정해야 한다.
2. 데이터셋 로드
df=pd.read_csv("data/diabetes.csv") # data 파일은 jupyter notebook과 같은 경로에 두는 것을 권장
df.shape(768, 9)
* 데이터와 Jupyter notebook을 같은 경로에 두어야 관리하기도 편하고, 데이터를 불러올 때 경로를 설정하기도 편리하다.
df.head()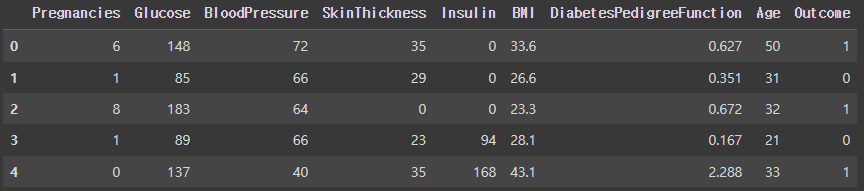
Outcome : 예측해야 하는 데이터
데이터프레임에 존재하는 모든 데이터가 모두 숫자이기 때문에 전처리가 필요하지 않다.
3. 학습, 예측 데이터셋 나누기
데이터셋은 학습 세트와 예측 세트로 나눠줘야 한다.
# 8:2의 비율로 구하기 위해 전체 데이터의 행에서 80% 위치에 해당하는 값을 split_count 변수에 담는다.
split_count = int(df.shape[0] * 0.8)
split_count614df.shape를 통해 튜플로 데이터를 가져오고, [0]이라는 인덱싱을 통해 df의 행의 갯수를 출력한다.
여기서 나온 행의 갯수의 80%만 가져오기 위해 0.8을 곱하고, int() 함수를 이용해 정수 값이 나오도록 하며, 해당 정수 값을 split_count 변수에 담아준다.
# train, test로 슬라이싱을 통해 데이터를 나눈다.
train = df[:split_count].copy()
train.shape(614, 9)' : (콜론)'을 이용해서 슬라이싱을 하여 train과 test로 데이터를 나눈다.
먼저, 0번째 행부터 split_count번째 전까지 슬라이싱 한 행들을 복사하여 train에 넣는다. (데이터의 80% 부분)
test = df[split_count:].copy()
test.shape(154, 9)split_count부터 끝 행까지 슬라이싱하여 test에 넣는다. (데이터의 20% 부분)
4. 학습, 예측에 사용할 값(컬럼) 지정하기
# feature_names 라는 변수에 학습과 예측에 사용할 컬럼명을 가져온다.
feature_names = train.columns[:-1].tolist()
feature_names처음부터 마지막에서 두번째 열까지, 즉 Outcome을 제외한 열을 feature_names로 지정한다.
여러 개의 값을 가지고 올 것이기 때문에 list 형태로 지정한다.

5. 정답값이자 예측해야 될 값(컬럼) 지정하기
# label_name 이라는 변수에 예측할 컬럼의 이름을 담는다.
label_name = train.columns[-1]
label_name
정답값이자 예측해야 될 값으로는 Outcome 컬럼을 사용하고, 이를 label_name으로 지정한다.
사용할 값이 Outcome 1개기 때문에 string 형태로 지정한다.
6. 학습, 예측 데이터셋 만들기
1) 학습 세트 만들기
# 학습 세트를 만들어 준다. 예) 시험의 기출문제
X_train = train[feature_names]
print(X_train.shape)
X_train.head()
feature_names 변수에 들어있는 열만 가져와 학습 세트를 만들어 준다.
2) 정답 값 만들기
# 정답 값을 만들어 준다. 예) 기출문제의 정답
y_train = train[label_name]
print(y_train.shape)
y_train.head()
Outcome 하나만 train에서 가져와 정답 값으로 만들어 준다.
3) 예측용 데이터셋 만들기
# 예측에 사용할 데이터세트를 만들어 준다. 예) 실전 시험 문제
X_test = test[feature_names]
print(X_test.shape)
X_test.head()
예측에 사용할 데이터세트를 만들어 준다.
예측에 사용할 데이터세트(X_test)의 열 개수와 학습 세트(X_train)의 열 개수는 같아야 한다.
4) 예측의 정답값 만들기
# 예측의 정답값을 만들어 준다. 예) 실전 시험 문제의 정답
y_test = test[label_name]
print(y_test.shape)
y_test.head()
예측이 맞았는지 확인하는 정답값, 즉 답안지를 만든다. 이는 학습이 잘 되었는지 비교 및 확인하는 용도로 만든다.
1.2.3 의사결정나무로 학습과 예측하기
머신러닝 알고리즘 가져오기
scikit-learn에서 제공하는 DecisionTreeClassifier를 사용하여 의사 결정 트리 분류기 모델을 생성하는 코드는 다음과 같다. random_state=42는 모델을 학습할 때 무작위성이 있는 부분에 대해 재현 가능한 결과를 얻기 위한 것이다.
# scikit-learn 라이브러리에서 DecisionTreeClassifier 모델을 불러오기
from sklearn.tree import DecisionTreeClassifier
# random_state를 42로 설정하여 DecisionTreeClassifier 모델을 초기화하기
model = DecisionTreeClassifier(random_state=42)
model
학습(훈련)
# X_train은 학습 데이터, y_train은 해당 데이터에 대한 레이블을 나타냄
# fit() 메서드를 사용하여 train 데이터에 맞춰 학습 모델을 학습
model.fit(X_train, y_train)
fit() 메서드는 머신 러닝 모델을 학습시키는 데 사용된다. 모델이 데이터에 적합하도록 학습을 진행하는 과정을 나타냅니다. 이 메서드를 호출하면 모델은 주어진 입력 데이터와 해당하는 출력(목표) 데이터 사이의 관계를 학습하려고 시도한다. X_train은 학습 데이터, y_train은 해당 데이터에 대한 레이블을 나타낸다.
다음에서 fit() 메서드에 대해 더 자세히 알아보자.
fit() 메서드는 일반적으로 다음과 같은 형식을 갖는다.
model.fit(X, y)
● model: 학습시킬 머신 러닝 모델 객체입니다. 이 경우에는 DecisionTreeClassifier를 의미한다.
● X: 입력 특성 데이터(또는 설명 변수)를 나타내는 배열 또는 데이터프레임입니다. 각 행은 하나의 데이터 샘플을 나타내며, 각 열은 해당하는 특성을 나타낸다.
● y: 출력(목표) 데이터(또는 반응 변수)를 나타내는 배열 또는 리스트이다. X의 각 행에 대응하는 출력 값이다.
모델이 fit() 메서드를 호출하면, 입력 데이터 X와 출력 데이터 y를 사용하여 모델 내부의 매개변수(가중치 및 편향 등)를 조정하여 학습한다. 학습된 모델은 이러한 데이터에 대해 예측을 수행하거나 새로운 데이터에 대한 예측을 할 수 있게 된다.
fit() 메서드에는 다양한 옵션을 지정할 수 있다. 다음에서 가장 일반적으로 사용되는 옵션 몇 가지에 대해 알아보자.
■ sample_weight: 각 데이터 포인트의 가중치를 지정한다. 대표적으로 불균형한 클래스 분포를 다룰 때 사용할 수 있다.
model.fit(X, y, sample_weight=weights)
■ class_weight: 클래스 별로 다른 가중치를 지정하여 클래스 불균형 문제를 해결할 수 있다.
model.fit(X, y, class_weight={0: 1, 1: 2})
■ callbacks: 학습 중에 호출할 콜백 함수를 지정한다. 콜백은 각 학습 반복(epoch)이 끝날 때마다 실행된다.
model.fit(X, y, callbacks=[callback1, callback2])
※ 콜백 함수(callback function)는 다른 함수에게 인자로 전달되는 함수를 말한다. 즉, 다른 함수 내에서 호출되는 함수를 의미한다.
■ validation_split: 학습 데이터의 일부를 검증 데이터로 사용하여 모델을 평가할 수 있다. 학습 데이터의 일정 비율을 지정하여 사용한다.
model.fit(X, y, validation_split=0.2)
■ batch_size: 한 번의 학습 반복에서 사용할 데이터 샘플의 수를 지정한다. 더 작은 배치 크기는 메모리 사용량을 줄이고 학습 과정을 안정화시킬 수 있다.
model.fit(X, y, batch_size=32)
■ epochs: 전체 학습 데이터셋을 반복할 횟수를 지정한다.
model.fit(X, y, epochs=10)
■ verbose: 학습 과정의 출력을 조절한다. 0일 경우 출력을 보이지 않고, 1일 경우 진행 상황을 출력하며, 2일 경우 각 에포크마다 한 줄로 출력한다.
model.fit(X, y, verbose=1)
이러한 옵션들을 사용하면 모델 학습 과정을 더욱 세밀하게 조정할 수 있다.
예측하기
위에서 학습한 데이터를 바탕으로 예측을 할 수 있습니다.
# 모델을 사용하여 테스트 데이터(X_test)에 대한 예측 수행
# predict() 메서드를 사용하여 모델을 통해 예측을 수행하고, 그 결과를 y_predict 변수에 저장
y_predict = model.predict(X_test)
# y_predict의 처음 5개 값을 출력
y_predict[:5]
model.predict() 메서드는 테스트 데이터에 대한 예측값을 반환한다. 이 예측값은 모델이 입력 데이터에 대해 예측한 출력값(목표값)이다.
모델이 테스트 데이터에 대해 어떤 예측을 하는지 간단히 확인하기 위해 y_predict[:5]로 예측값 중에서 처음 5개의 값을 선택하여 출력한다.
※ predict는 정답을 옵션으로 넣지 않는다. 현실에서는 정답이 주어지지 않기 때문에, 문제를 푼 후에 정답 데이터와 비교한다. 따라서 기출문제(train data)만 넣어줘야 한다.
1.2.4 예측한 모델의 성능 측정하기
알고리즘 시각화하기
우선 scikit-learn 패키지에서 plot_tree 함수를 불러온다.
> from sklearn.tree import plot_tree
'figsize = (20,20)' 을 통해 차트의 가로와 세로의 크기를 각각 20인치로 설정한 후, plot_tree 함수에 다음과 같은 매개변수를 넣는다.
- model : DecisionTreeClassifier
- feature_names : 우리가 지정한 feature_names
- filled=True : 트리의 각 노드를 채색하여 클래스별로 분포를 나타내는 인수
- fontsize=10 : 트리에서 사용되는 글꼴 크기(기본값은 10)
> plt.figure(figsize=(20,20))
> tree = plot_tree(model,
feature_names = feature_names,
filled=True,
fontsize=10)
결과를 출력하면 아래의 차트로 DecisionTree model이 시각화된다.
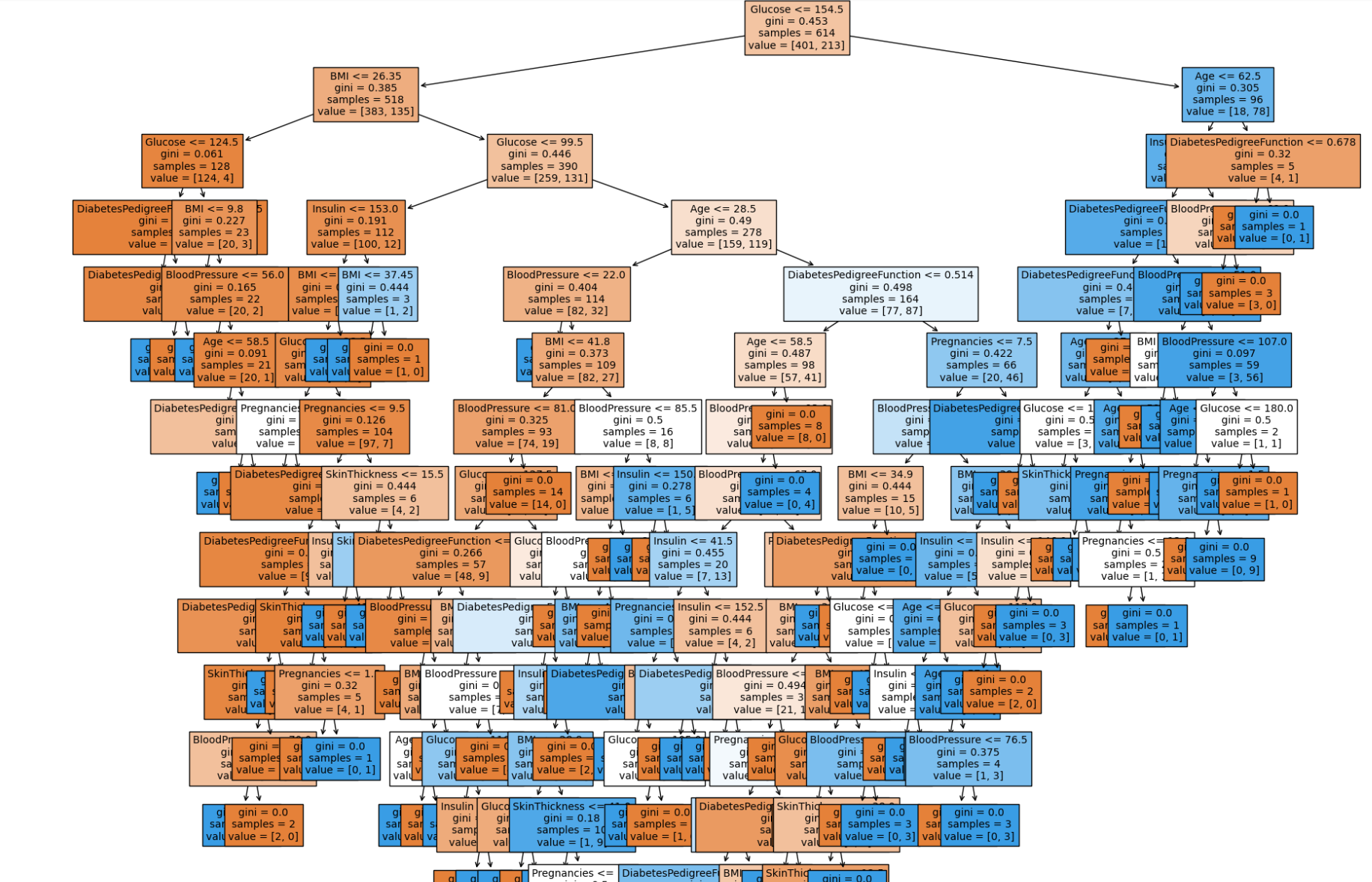
데이터가 많을 시 시각화된 차트 안의 글이 잘 보이지 않는다면 graphviz 패키지를 이용한다. plot_tree 함수를 사용했을 때와 거의 유사한 parameter를 입력하여 가시성이 뛰어난 차트를 시각화한다.
# graphviz 를 통해 시각화 합니다.
# graphviz 는 별도의 설치가 필요합니다.
# graphviz 와 파이썬에서 graphviz 를 사용할 수 있게 해주는 도구 2가지를 설치해 주셔야 합니다.
import graphviz
from sklearn.tree import export_graphviz
dot_tree = export_graphviz(model,
feature_names = feature_names,
filled=True)
graphviz.Source(dot_tree)feature 중요도 측정하기
머신러닝 모델에서 feature의 중요도란 해당 특성이 모델의 예측에 얼마나 영향을 미치는 지를 나타낸다. DecisionTreeClassifer 모델의 경우 feature의 중요도는 해당 특성이 데이터를 분할하는 데에 얼마나 유용한지를 드러낸다.
아래는 각 특성의 중요도를 나타내는 배열을 반환한 코드이다. 각 특성의 중요도를 한 눈에 효과적으로 비교하기 위해 막대 그래프로 시각화 해볼 예정이다.
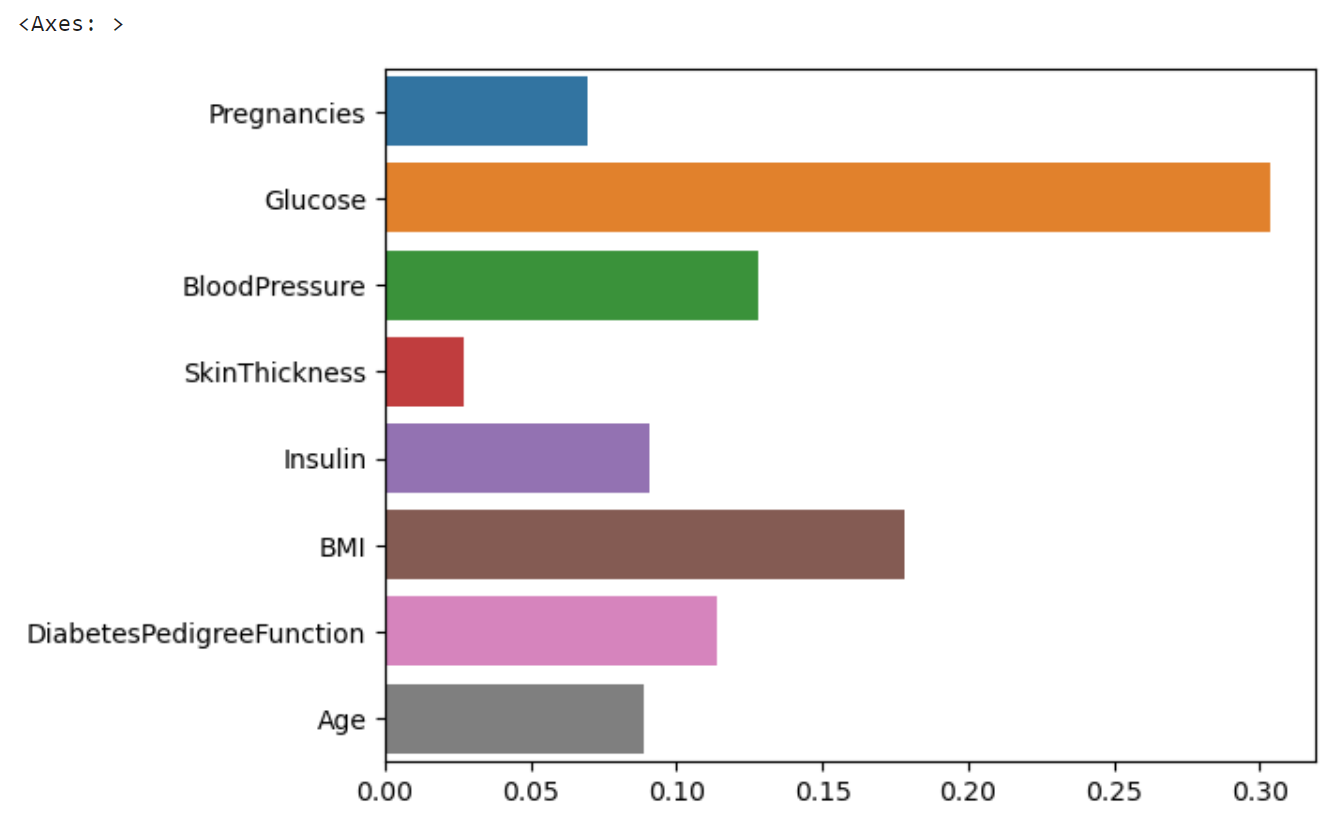
> model.feature_importances_
array([0.06950575, 0.30404191, 0.12781001, 0.02726087, 0.09093848,
0.17793908, 0.11389896, 0.08860495])
seaborn 라이브러리의 'barplot' 함수를 사용하였다. x 축에는 각 특성의 중요도를 설정하고, y 축에는 특성의 이름을 설정한 코드이다.
> sns.barplot(x=model.feature_importances_, y=feature_names)
아래 차트는 feature_names 의 중요도를 색깔별로 다르게 하여 특성의 이름과 함께 막대그래프로 시각화한 결과이다. 각 막대는 해당 특성의 중요도를 나타내며, 차트를 통해 특정 feature가 모델의 예측에 얼만큼 영향을 끼치는지 시각적으로 비교할 수 있다.
모델 정확도 측정하기
앞서 설정한 'y_test' 데이터셋을 토대로 모델의 정확도를 측정한다. 현실에서는 'y_test' 데이터셋, 즉 정답이 없는 경우가 대다수이지만 이 예시에서는 정답을 보유한 경우를 다룬다.
> diff_count = abs(y_test - y_predict).sum()
> diff_count
41우선 모델이 예측한 값에서 오류가 몇 개인지 찾아내는 코드를 만들었다. (y_test - y_predict) 에 절댓값을 씌운 값은 오류가 있는지 여부를 알려준다.
그 이유는 만약에 오류가 없다면 | (y_test - y_predict) |= 0 , 오류가 있다면 | (y_test - y_predict) |= 1 이라는 결과가 출력되기 때문이다. sum() 함수를 통해 이들의 합을 구하면 이 예시에서 설정한 모델은 41개의 오류를 가지고 있다는 해석을 할 수 있다.
우리는 이 모델이 100점 만점 중에 몇점인지, 즉 몇 퍼센트의 정확도를 보이는지 파악해야 한다. 총 세가지 방법으로 모델의 정확도를 구할 수 있다.
> (len(y_test) - diff_count) / len(y_test) *100
73.37662337662337첫 번째 방법은 정답 데이터 셋(y_test) 의 데이터 개수에서 오류의 개수(diff_count)를 뺀 값을 정답 데이터 셋(y_test)로 나눠준 후 백분율을 구하기 위해 100을 곱해주는 코드이다.
> from sklearn.metrics import accuracy_score
> accuracy_score(y_test, y_predict) *100
73.37662337662337두 번째 방법은 scikitlearn 패키지에 있는 함수를 이용하는 코드이다. accuracy_score 라는 함수를 불어온 뒤, parameter로 (정답 데이터셋, 예측 데이터셋) 을 넣은 후 백분율을 구하기 위해 100을 곱해주면 정확도를 구할 수 있다.
> model.score(X_test, y_test) *100
73.37662337662337세 번째 방법은 DecisionTreeClassifer 모델 자체의 함수를 이용하는 코드이다. model.score() 의 parameter로 (실제 데이터셋, 정답 데이터셋) 을 넣은 후 백분율을 구하기 위해 100을 곱해주면 정확도를 구할 수 있다.
<1주차 과제 업로드>
<출처>
프로젝트로 배우는 데이터사이언스 > 1.1.2 사이킷런 활용 흐름 : 부스트코스 (boostcourse.org)
Building a Random Forest Model: A Step-by-Step Guide (analyticsvidhya.com)
Understand Random Forest Algorithms With Examples (Updated 2024)
Learn to use Random Forest and Random forest algorithms in real-world. Tips to implement this machine learning technique, advantages of using it, and more.
www.analyticsvidhya.com
기계 학습 유형 - Training | Microsoft Learn
기계 학습 유형 - Training
기계 학습 유형
learn.microsoft.com
'Study > CODE 2기 [프로젝트로 배우는 데이터사이언스]' 카테고리의 다른 글
| [Trillion(1조)] 프로젝트로 배우는 데이터사이언스_2주차 (0) | 2024.03.18 |
|---|---|
| [All in One(2조)] 프로젝트로 배우는 데이터사이언스_2주차 (1) | 2024.03.18 |
| [삼위일체(3조)] 프로젝트로 배우는 데이터 사이언스_2주차 (0) | 2024.03.18 |
| [삼위일체(3조)] 프로젝트로 배우는 데이터 사이언스 (0) | 2024.03.11 |
| [Trillion(1조)] 프로젝트로 배우는 데이터 사이언스 (0) | 2024.03.10 |



