-----------------------------------------------------------------------------------------------------------------------------------------------------------------
팀 구성원
-남유한
-김도균
-윤서현
-임규민
-서장원
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
1.1 사이킷런과 머신러닝
1.1.1 사이킷런 소개
- 사이킷런(Scikit-learn)이란? -
-> 파이썬에 가장 대표적인 머신러닝 라이브러리로, 다양한 기계학습 알고리즘을 제공하고 있다. 또한 이러한 알고리즘들이 최적화되어있어 크고 작은 데이터셋들을 쉽게 시각화하고 구현할 수 있다.
< 구성 >
1. classification(분류)
-사이킷런에서 classification은 분류 작업을 수행한다. 예를 들어서 상품 마케팅 입장에서 A고객이 어떤 상품을 구매할 것인지 아닌지, 나에게 온 메일이 스팸인지 아닌지, B가 광고를 클릭할 것인지 아닌지를 분류해주는 역할을 수행한다.

사이킷런 홈페이지에 있는 classification의 예시 데이터를 대표적으로 한 번 살펴보자.
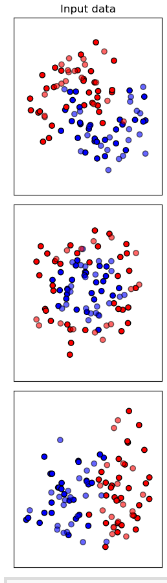
먼저 시각자료 맨왼쪽에 'input data'가 있고,
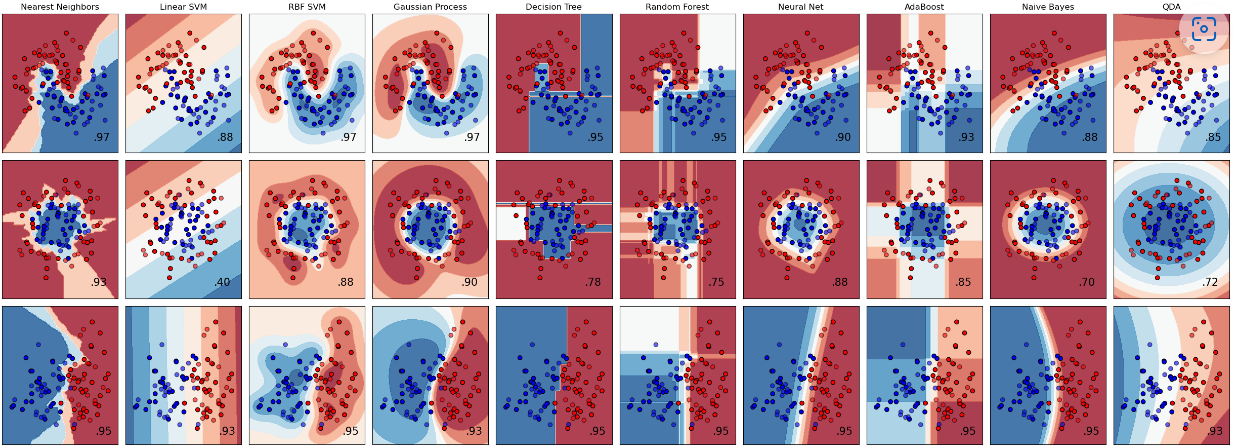
input data옆에는 각각의 상단에 알고리즘 이름이 나오고 각 시각자료 우측 하단에 데이터의 정확도가 나타나고 있는 것을 볼 수 있다. 이러한 머신러닝 알고리즘은 요리할 때의 조리도구이다. 각각의 적절한 조리도구(알고리즘)를 선택해서 어떠한 레시피를 만들어낼 수 있는지가 중요하다.
2. regression(회귀)
-사이킷런에서 regression은 회귀 작업을 수행한다. 예를 들어서 어떤 소비자가 물건을 살 때 얼마를 구매할 것인지, 광고사의 광고의 효율을 평가하자면 그 효율성은 몇 일지 예측하는 역할을 수행한다.
마찬가지로 사이킷런 홈페이지에 있는 예시 자료를 한 번 살펴보자.
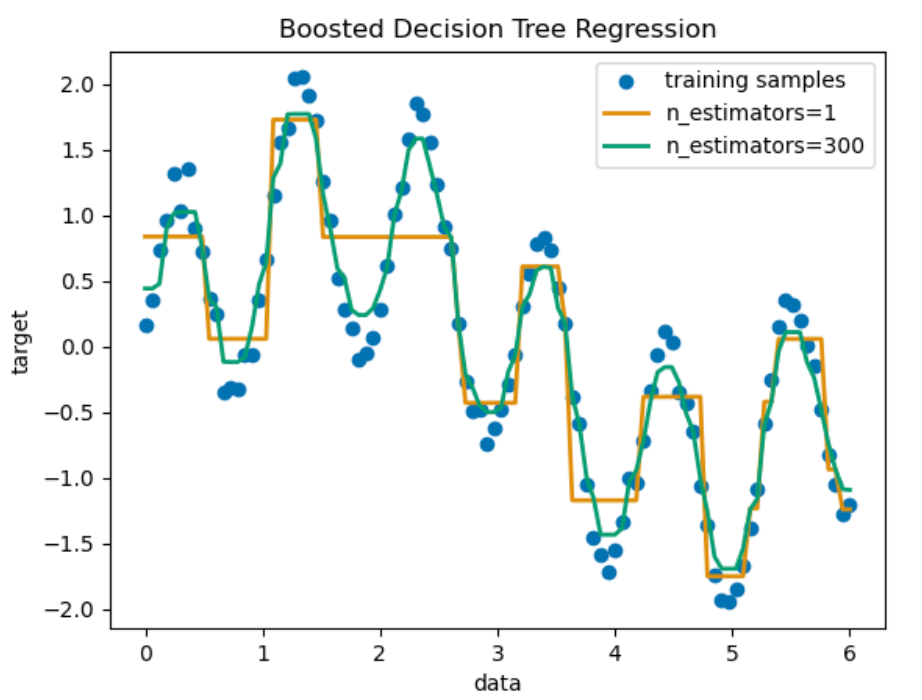
해당 자료에는 그래프에 높고 낮음이 가로선으로 표시되어 있다. 이를 표시한 이유는 물건의 가격 예측, 어떤 물건이 얼마나 판매가 될 것 인지, 그리고 이를 통해 해당 분기에 매출량, 매출액, 재고량은 어떻게 될 것인지를 회귀를 사용해서 분석 및 예측을 하는 것이다.
이 밖에도 clustering, dimensionality reduction, model selection, prepocessing 등의 기능이 포함되어 있어 파이썬에서 다양한 알고리즘을 사용하기 위해 유용하다.
++supervised learning(지도학습)과 unsupervised learning(비지도학습): supervised learning은 정답이 있는 데이터를 맞히는 것을 의미하고( classification, regression 등), unsupervised learning은 정답이 없는 데이터를 맞히는 것을 의미한다( clustering 등).
1.1.2 사이킷런 활용 흐름
(1) SUPERVISED MACHINE LEARNING

앞서 supervised learning은 교수학습으로써 정답이 있는 데이터를 맞히는 것이라고 언급하였다. 해당 과정에 대해서 자세히 알아보자. 먼저 위에 그림에서 Training Data는 기출문제이고 Training Labels는 기출문제의 정답이라고 하자. 그럼 이 기출문제들을 열심히 풀고 답을 체크해서 하나의 모델을 만들어낸다.

그리고 열심히 연습해 만들어낸 모델을 실제 시험장에 가서 시험을 보는 것을 'Prediction'이라고 한다. 즉, 고객이 구매한 데이터(Training Data)와 고객이 구매할지 말 지(Training Labels)에 대한 정답을 알고 있다면 이러한 사례들을 보편화해서 하나의 Model을 만들어내는 것이고, 새로운 고객이 오면(Test Data) 어떤 물건을 구매할지 말 지 분석하여 최대한 구매할 수 있는 방향으로 이끌어내는 과정인 것이다.
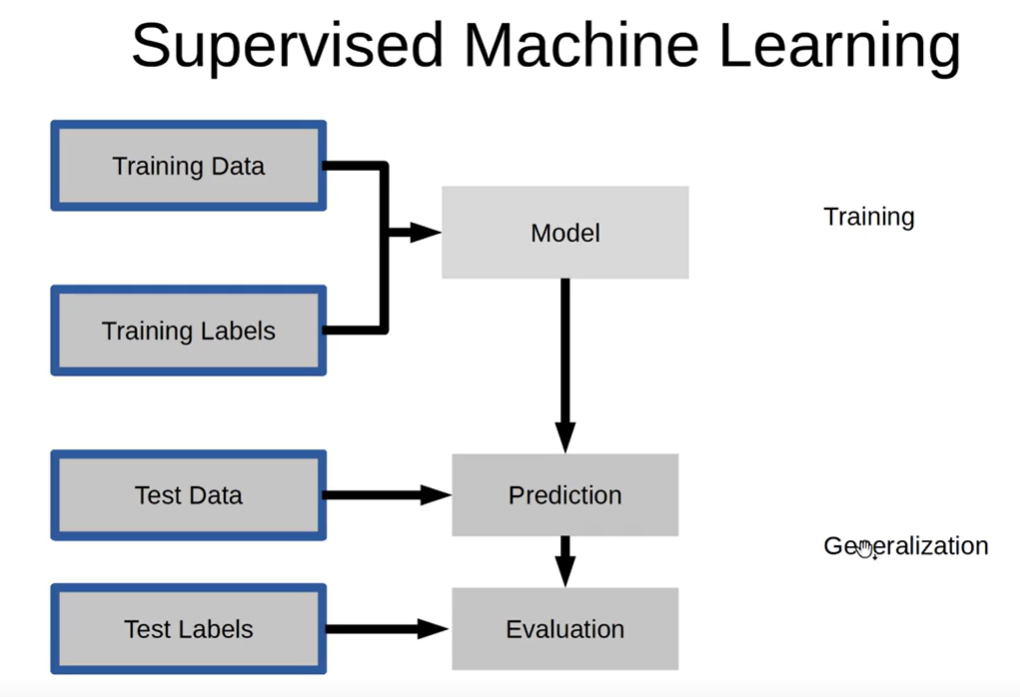
그리고 마지막으로는 우리의 예측과 분석이 제대로 맞았는지 채점해보기 위해서 Test Labels 과정을 통해 우리의 전략에 문제가 없었는지 확인하게 된다.

따라서 우리는 먼저 Model을 만들 때 트리 모델을 사용하는데 바로 위에 랜덤포레스트를 사용할 것이다.
clf를 통해 Randomforestclassifier()를 불러오고 clf.fit을 통해 x_train(문제)와 y_train(정답)을 끌어내어 학습시킴으로써 하나의 모델을 만들어내는 것이다.
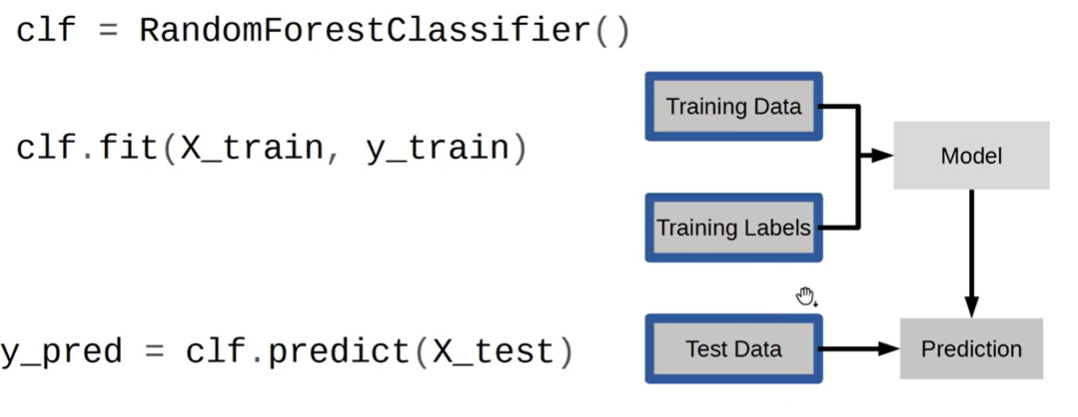
그리고 그 다음으로 clf.predict를 통해 새로운 고객을 대상으로 시험을 해보는 과정을 코딩할 수 있다.

그리고 마지막으로 clf.score를 통해 우리가 시행한 전략이 제대로 먹혔는지 채점해보는 과정을 거침으로써 supervised machine learning 과정이 완성되게 된다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
(2)UNSUPERVISED MACHINE LEARNING

이번에는 unsupervised machine learning의 과정에 대해서도 한 번 살펴보자.
supervised machine learning 과 unsupervised machine learning의 가장 큰 차이점은 '정답 데이터의 유무'이다. 군집화 등이나 차원 축소 과정에 unsupervised machine learning을 이용하는데 군집화의 경우 쇼핑몰에서 고객층을 비슷한 사람들끼리 묶어서 적절한 물건들을 개별적으로 추천하거나 맞춤 프로모션을 진행하는 등의 마케팅 계획을 세울 수 있다.

그리고 차원 축소의 경우에는 PCA를 이용하게 되는데, 시각화 등에 주로 이용한다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
(3)CROSS VALIDATION
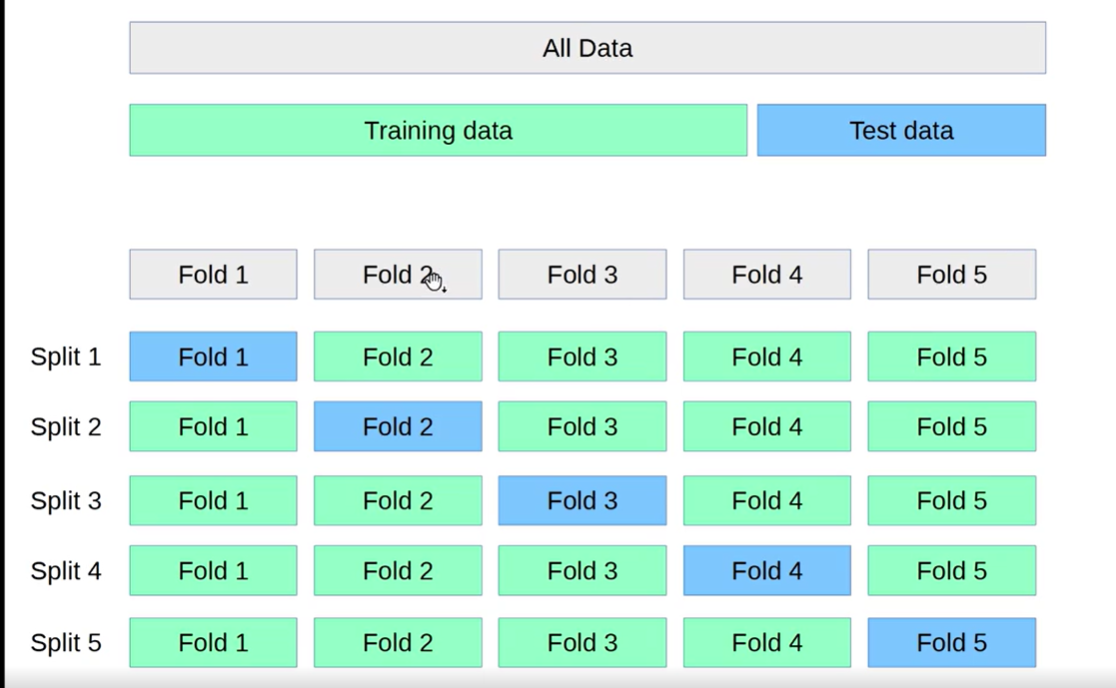
우리는 쌓아왔던 Training data들을 검증하고 싶을 때 CROSS VALIDATION이라는 기법을 사용한다. 검증할 데이터를 한 번 fit 하고 한 번 predict 하면 검증력이 떨어질 수 있기 때문에 여러 개의 split으로 나누어 각각의 fold들의 점수를 합산해서 가장 좋은 점수를 내는 모델을 찾아낸다.
----------------------------------------------------------------------------------------------------------------------------------------------------------------(4)GRID SEARCHES
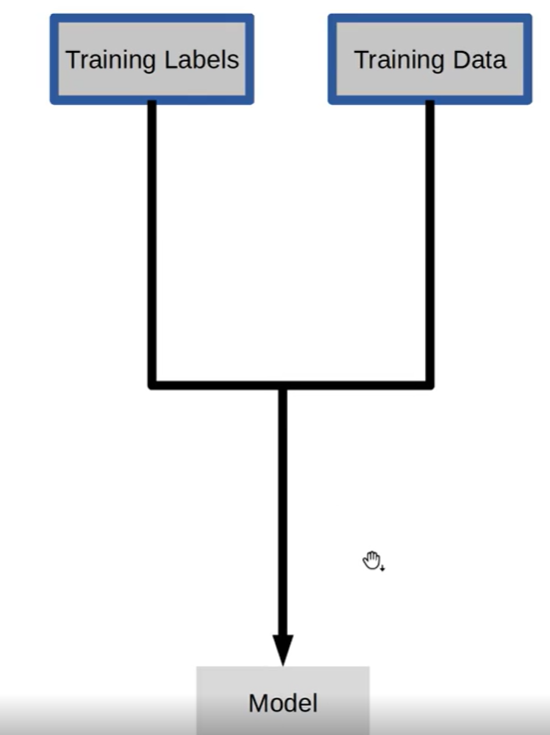
우리는 Training labels와 Training Data를 이용하여 하나의 모델을 만들어낸다.
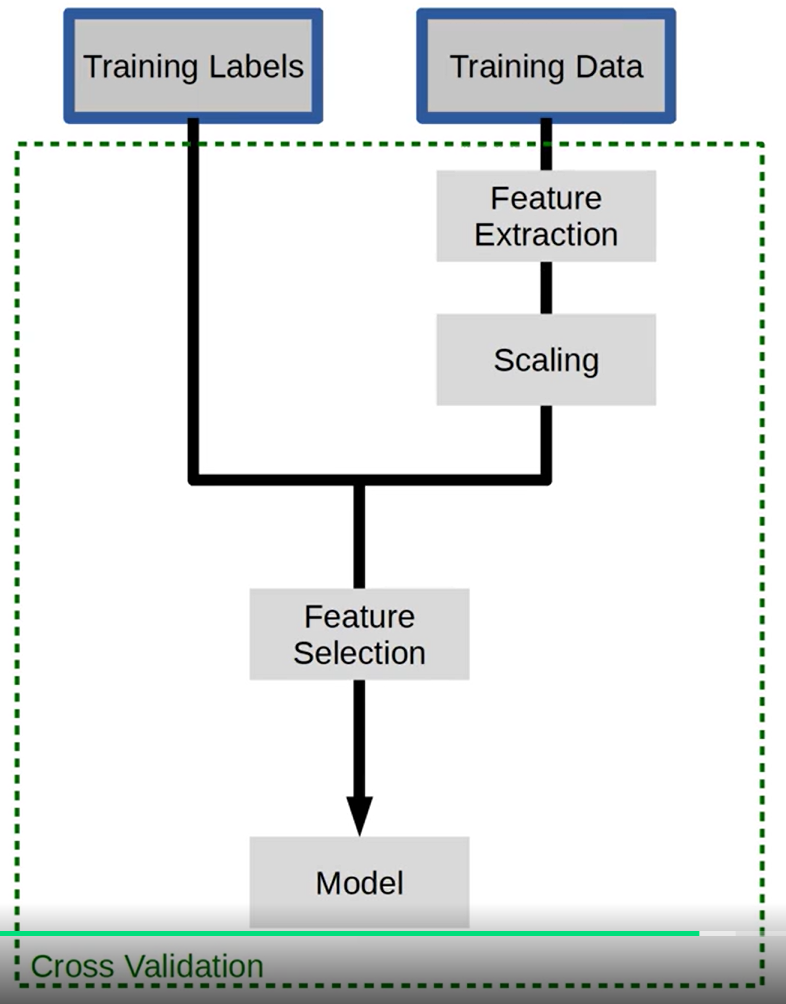
그러나 중간에 feature를 추출하고 scaling하고 feature를 선택하는 과정까지 더하여 최종적인 cross validation을 만들어내게 된다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------(5)OVERFITTING AND UNDERFITTING
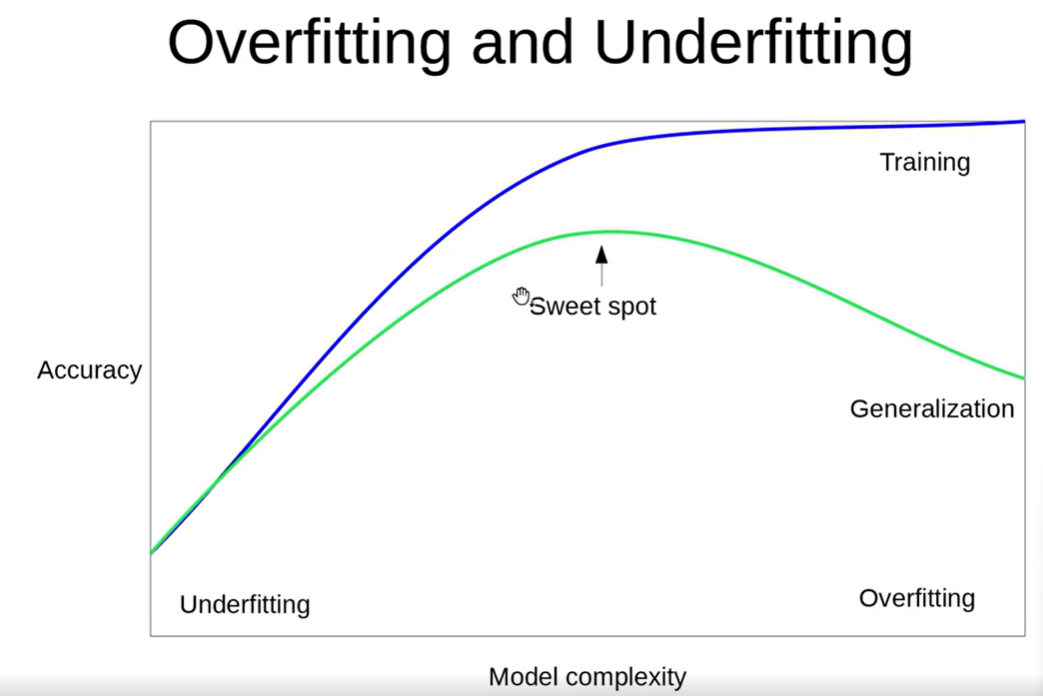
해단 사진에서 X축은 MODEL COMPLEXITY이고, Y축은 ACCURACY이다. 먼저 보라색 그래프를 보자. Y축의 정확도가 낮은 부분은 그만큼 이미 있는 데이터에 대한 학습이 부족하다는 뜻이고, 이미 있는 데이터를 꾸준히 반복하여 학습하다보면 OVERFITTING되어 정확도가 매우 높아져 있는 것을 볼 수 있다. 그러나 실전은 다르다. 녹색 그래프를 보면 보라색 그래프와 마찬가지로 정확도가 낮은 UNDERFITTING부분은 그만큼 학습량이 부족한 상태인데, 점점 학습을 하다보면서 정확도가 커지다가 어느순간 내려앉는 형태의 모습을 볼 수 있다. 따라서 우리는 UNDERFITTING과 OVERFITTING의 적절한 중간 지점인 SWEET SPOT을 찾는 것이 핵심이라고 할 수 있다.
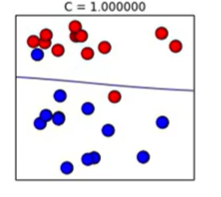
underfitting상태
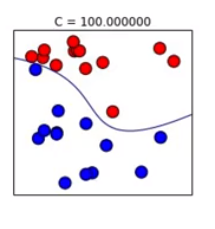
적절한 overfitting 상태
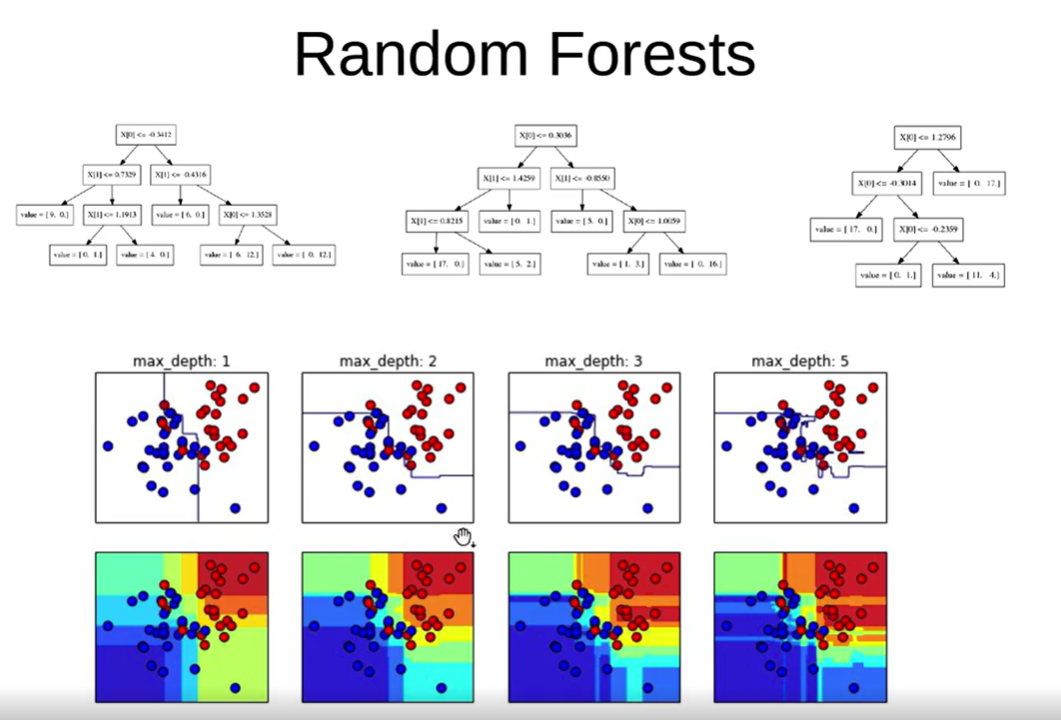
따라서 randomforest는 의사결정나무들을 많이 만들면 더 좋은 성능을 낼 수 있겠다는 아이디어에서 만들어 진 것인데, 여기에서도 너무 underfitting되면 안되고, 반대로 너무 overfitting되도 안되는 그 중간상태를 만드는 것이 가장 좋다.
++TREE-BASED 모델은 분류와 회귀가 모두 가능함.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
(6)SCORING FUNCTIONS
- SCORING FUNCTIONS은 우리가 학습을 했을 때 몇 점정도 받을 것인지를 채점해보는 과정이다.
GridSearchCV, RandomizedSearchCV, cross_val_score을 했을 때 얼마나 높고 낮은지에 대해 그 점수를 구하게 되는데 classification에서는 Accuracy를 사용하게 되고, regression의 경우 R2를 사용하게 된다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
1.1.3 사이킷런의 의사결나무 알고리즘 알아보기
그럼 이제 우리가 중점적으로 배워볼 classification과 regression을 직접 코드 구현을 통해 알아보자.
1. classification
from sklearn import tree
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
-먼저 첫째 줄에서 from ~ import ~ 함수를 통해 사이킷런에서 tree를 사용할 수 있도록 불러와준다. 그리고 x와 y각각에서 x가 0, 0일 때 y는 0이고 x가 1,1일 때 y는 1인 것을 정답값으로 설정해준다.
-그리고 그 다음에 clf.fit()을 하게 되면 여기서 fit은 '학습한다'라는 뜻으로 x와 y의 데이터를 decisiontreeclassifier가 공부를 하게 된다.
clf.predict([[2., 2.]])따라서 여기서 clf.predict([[2., 2.]])을 해주게 되면
array([1])이 출력된다.
clf.predict_proba([[2., 2.]])그리고 여기서 clf.predict_proba를 해주게 되면 array([[0., 1.]])이 출력된다.
그 이유는 predict_proba함수를 써주게 되면 비율로 값이 나오기 때문이다.
그렇다면 'iris'라는 붓꽃 데이터셋을 통해 실습을 진행해보자.
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
X, y = iris.data, iris.target
X, y먼저 아까와 같이 사이킷런을 불러와주고, load_iris()를 통해 붓꽃 데이터셋을 불러와준다.
(array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1],
[5.4, 3.7, 1.5, 0.2],
[4.8, 3.4, 1.6, 0.2],
[4.8, 3. , 1.4, 0.1],
[4.3, 3. , 1.1, 0.1],
[5.8, 4. , 1.2, 0.2],
[5.7, 4.4, 1.5, 0.4],
[5.4, 3.9, 1.3, 0.4],
[5.1, 3.5, 1.4, 0.3],
[5.7, 3.8, 1.7, 0.3],
[5.1, 3.8, 1.5, 0.3],
[5.4, 3.4, 1.7, 0.2],
[5.1, 3.7, 1.5, 0.4],
[4.6, 3.6, 1. , 0.2],
[5.1, 3.3, 1.7, 0.5],
[4.8, 3.4, 1.9, 0.2],
[5. , 3. , 1.6, 0.2],
[5. , 3.4, 1.6, 0.4],
[5.2, 3.5, 1.5, 0.2],
[5.2, 3.4, 1.4, 0.2],
[4.7, 3.2, 1.6, 0.2],
[4.8, 3.1, 1.6, 0.2],
[5.4, 3.4, 1.5, 0.4],
[5.2, 4.1, 1.5, 0.1],
[5.5, 4.2, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.2],
[5. , 3.2, 1.2, 0.2],
[5.5, 3.5, 1.3, 0.2],
[4.9, 3.6, 1.4, 0.1],
[4.4, 3. , 1.3, 0.2],
[5.1, 3.4, 1.5, 0.2],
[5. , 3.5, 1.3, 0.3],
[4.5, 2.3, 1.3, 0.3],
[4.4, 3.2, 1.3, 0.2],
[5. , 3.5, 1.6, 0.6],
[5.1, 3.8, 1.9, 0.4],
[4.8, 3. , 1.4, 0.3],
[5.1, 3.8, 1.6, 0.2],
[4.6, 3.2, 1.4, 0.2],
[5.3, 3.7, 1.5, 0.2],
[5. , 3.3, 1.4, 0.2],
[7. , 3.2, 4.7, 1.4],
[6.4, 3.2, 4.5, 1.5],
[6.9, 3.1, 4.9, 1.5],
[5.5, 2.3, 4. , 1.3],
[6.5, 2.8, 4.6, 1.5],
[5.7, 2.8, 4.5, 1.3],
[6.3, 3.3, 4.7, 1.6],
[4.9, 2.4, 3.3, 1. ],
[6.6, 2.9, 4.6, 1.3],
[5.2, 2.7, 3.9, 1.4],
[5. , 2. , 3.5, 1. ],
[5.9, 3. , 4.2, 1.5],
[6. , 2.2, 4. , 1. ],
[6.1, 2.9, 4.7, 1.4],
[5.6, 2.9, 3.6, 1.3],
[6.7, 3.1, 4.4, 1.4],
[5.6, 3. , 4.5, 1.5],
[5.8, 2.7, 4.1, 1. ],
[6.2, 2.2, 4.5, 1.5],
[5.6, 2.5, 3.9, 1.1],
[5.9, 3.2, 4.8, 1.8],
[6.1, 2.8, 4. , 1.3],
[6.3, 2.5, 4.9, 1.5],
[6.1, 2.8, 4.7, 1.2],
[6.4, 2.9, 4.3, 1.3],
[6.6, 3. , 4.4, 1.4],
[6.8, 2.8, 4.8, 1.4],
[6.7, 3. , 5. , 1.7],
[6. , 2.9, 4.5, 1.5],
[5.7, 2.6, 3.5, 1. ],
[5.5, 2.4, 3.8, 1.1],
[5.5, 2.4, 3.7, 1. ],
[5.8, 2.7, 3.9, 1.2],
[6. , 2.7, 5.1, 1.6],
[5.4, 3. , 4.5, 1.5],
[6. , 3.4, 4.5, 1.6],
[6.7, 3.1, 4.7, 1.5],
[6.3, 2.3, 4.4, 1.3],
[5.6, 3. , 4.1, 1.3],
[5.5, 2.5, 4. , 1.3],
[5.5, 2.6, 4.4, 1.2],
[6.1, 3. , 4.6, 1.4],
[5.8, 2.6, 4. , 1.2],
[5. , 2.3, 3.3, 1. ],
[5.6, 2.7, 4.2, 1.3],
[5.7, 3. , 4.2, 1.2],
[5.7, 2.9, 4.2, 1.3],
[6.2, 2.9, 4.3, 1.3],
[5.1, 2.5, 3. , 1.1],
[5.7, 2.8, 4.1, 1.3],
[6.3, 3.3, 6. , 2.5],
[5.8, 2.7, 5.1, 1.9],
[7.1, 3. , 5.9, 2.1],
[6.3, 2.9, 5.6, 1.8],
[6.5, 3. , 5.8, 2.2],
[7.6, 3. , 6.6, 2.1],
[4.9, 2.5, 4.5, 1.7],
[7.3, 2.9, 6.3, 1.8],
[6.7, 2.5, 5.8, 1.8],
[7.2, 3.6, 6.1, 2.5],
[6.5, 3.2, 5.1, 2. ],
[6.4, 2.7, 5.3, 1.9],
[6.8, 3. , 5.5, 2.1],
[5.7, 2.5, 5. , 2. ],
[5.8, 2.8, 5.1, 2.4],
[6.4, 3.2, 5.3, 2.3],
[6.5, 3. , 5.5, 1.8],
[7.7, 3.8, 6.7, 2.2],
[7.7, 2.6, 6.9, 2.3],
[6. , 2.2, 5. , 1.5],
[6.9, 3.2, 5.7, 2.3],
[5.6, 2.8, 4.9, 2. ],
[7.7, 2.8, 6.7, 2. ],
[6.3, 2.7, 4.9, 1.8],
[6.7, 3.3, 5.7, 2.1],
[7.2, 3.2, 6. , 1.8],
[6.2, 2.8, 4.8, 1.8],
[6.1, 3. , 4.9, 1.8],
[6.4, 2.8, 5.6, 2.1],
[7.2, 3. , 5.8, 1.6],
[7.4, 2.8, 6.1, 1.9],
[7.9, 3.8, 6.4, 2. ],
[6.4, 2.8, 5.6, 2.2],
[6.3, 2.8, 5.1, 1.5],
[6.1, 2.6, 5.6, 1.4],
[7.7, 3. , 6.1, 2.3],
[6.3, 3.4, 5.6, 2.4],
[6.4, 3.1, 5.5, 1.8],
[6. , 3. , 4.8, 1.8],
[6.9, 3.1, 5.4, 2.1],
[6.7, 3.1, 5.6, 2.4],
[6.9, 3.1, 5.1, 2.3],
[5.8, 2.7, 5.1, 1.9],
[6.8, 3.2, 5.9, 2.3],
[6.7, 3.3, 5.7, 2.5],
[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]]),
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]))그럼 그 결괏값은 다음과 같이 나온다.
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
clf그리고 아까와 마찬가지로 의사결정나무에 학습을 시켜준다.
이제는 학습시켜준 해당 의사결정나무를 시각화해보자.
t = tree.plot_tree(clf.fit(X, y), filled=True)해당 코드를 입력해주면

다음과 같은 자료가 나오게 되는데 박스안의 글자가 잘 보이지 않으므로 수정이 필요하다.
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
t = tree.plot_tree(clf.fit(X, y), filled=True)
다음과 같이 figsize를 통해 의사결정나무의 크기를 조절해주고 filled=True를 통해 색감까지 입혀주면서
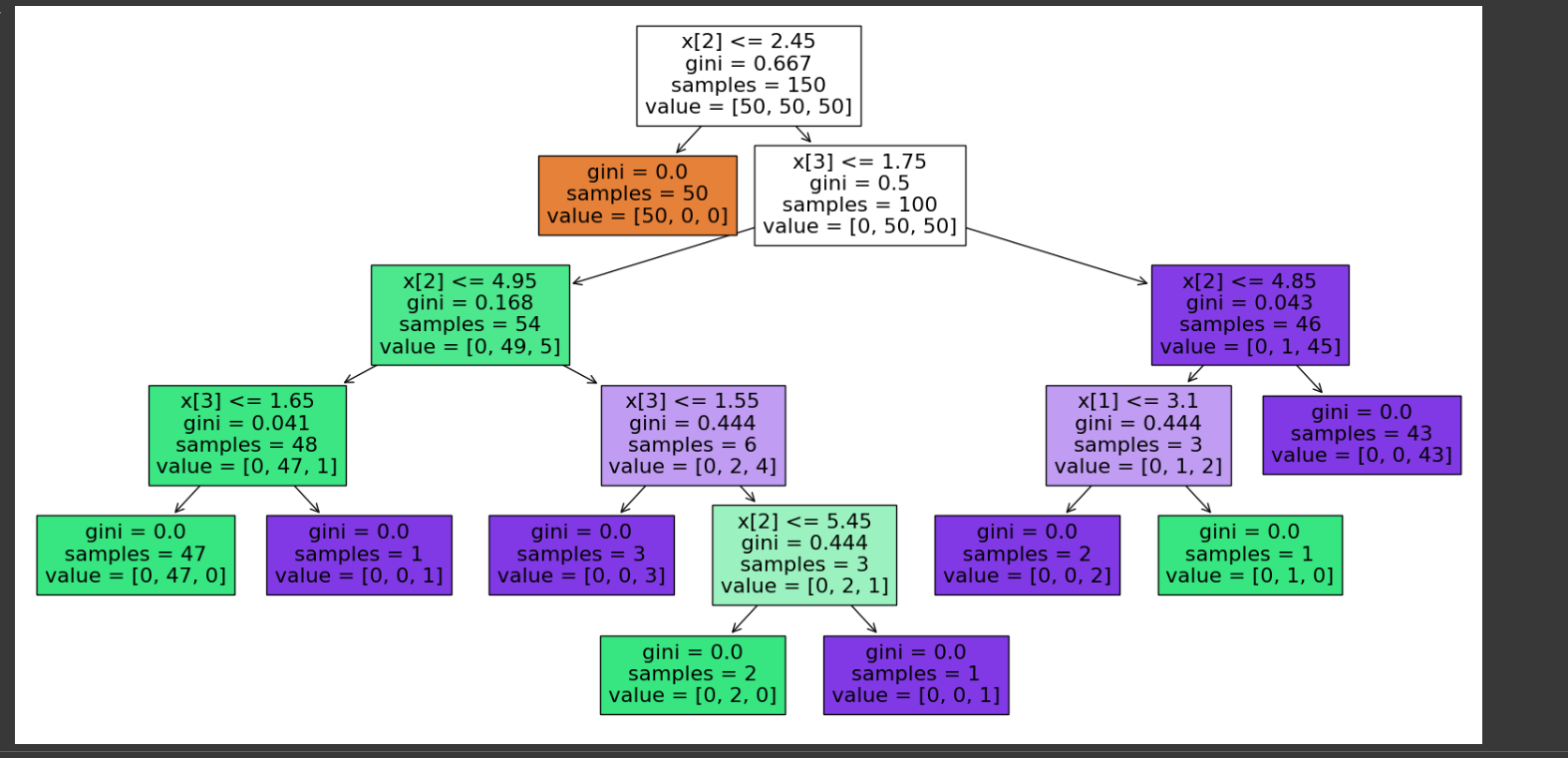
다음과 같이 보기 편하게 바뀌었다.
1.2 의사결정나무로 간단한 분류 예측 모델 만들기
1.2.1 당뇨병 데이터셋 소개
- 피마 인디언 데이터 셋이란? -
미국의 중부 그리고 서부 애리조나 지역에 사는 피마 인디언들이 서구 문명을 받아들이면서 생긴 식습관 변화 때문에 당뇨병 환자들이 증가했다. 여러 피마 인디언들을 대상으로 의료정보 및 당뇨병 여부를 모아 구축한 것이 피마 인디언 당뇨병 데이터셋이다. 이 데이터 세트는 원래 National Institute of Diabetes and Digestive and Kidney Diseases에서 비롯되었다. 이 데이터 셋의 목적은 데이터 셋에 포함된 진단 항목들을 기반으로 환자가 당뇨병을 가지고 있는지 여부를 예측하는 것이다.
이 데이터 셋은 Pima Indians Diabetes Database | Kaggle에 제공되고 있다. 또한 Scikit-learn에서도 관련 데이터셋을 받을 수 있는데, 주의할 사항은 샘플 사이즈가 442개로, Kaggle에서 제공하는 768개의 행보다 양이 적다는 것이다. 그러므로 우리는 Kaggle에서 제공하는 데이터 셋을 사용할 것이다.
- 데이터 탐색 및 시각화 -
데이터 셋에는 다음 9개의 컬럼이 있다.
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm) - 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중(kg) / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 함수 (가족내력를 기반으로 당뇨병 확률을 수치화하는 함수)
- Age : 나이
- Outcome : 클래스 변수(0 또는 1) - 768개 중 268개는 1(당뇨병 환자)이고 나머지는 0


각 컬럼의 분포도를 바그래프로 시각화한 모습
특이사항:
- Insulin을 봤을 때, 0에 해당하는 수치가 굉장히 비중이 높은 것을 볼 수 있다. 여기서 0이라는 수치는 결측치에 더 가까운 수치라고도 볼 수 있다. 이후에 회귀(Regression)을 통해 예측해 볼 계획이다.
- Outcome을 봤을 때, 당뇨병인 사람보다는 당뇨병이 아닌 사람이 좀 더 많다는 것을 확인할 수 있다.
1.2.2 학습과 예측을 위한 데이터셋 만들기
1. 필요한 라이브러리 로드
* 모든 코딩 작업은 라이브러리 및 개발 환경 세팅의 번거로움을 최소화하고 멤버들간 협업을 용이하게 만들기 위해 클라우드 서비스 기반인 Google Colab에서 시행되었다 *
데이터 분석을 위한 pandas, 수치계산을 위한 numpy, 시각화를 위한 seaborn과 matplotlib.pyplot을 로드한다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
2. 데이터셋 로드
Kaggle에서 다운로드 받은 데이터셋을 df라는 변수 안에 불러온다. 저장경로가 다를 경우에는 해당 경로를 read_csv(_____) 안에 입력하면 된다. 구글 코랩에서 오픈한 노트북이랑 같은 경로에 두는 것을 권장한다.
df = pd.read_csv('data/diabetes.csv')
df.info()를 통해 해당 데이터프레임에 관한 정보를 보자.
df.info()
윗 줄을 실행하면 다음과 같은 정보가 나온다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pregnancies 768 non-null int64
1 Glucose 768 non-null int64
2 BloodPressure 768 non-null int64
3 SkinThickness 768 non-null int64
4 Insulin 768 non-null int64
5 BMI 768 non-null float64
6 DiabetesPedigreeFunction 768 non-null float64
7 Age 768 non-null int64
8 Outcome 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
768개의 행과 9개의 열로 이루어진 것을 볼 수 있고, 또한 각각의 배열 원소 타입이 int64 또는 float64으로 숫자형이기 때문에 별도의 전처리 과정은 필요없을 것으로 보인다.
3. 학습, 예측 데이터셋 나누기 및 만들기
- 데이터 나누기 -
위에서 명시했듯이 전체 데이터를 학습 데이터와 학습이 완료된 모델을 테스트하기 위한 예측 데이터로 나눌 것이다.
이때 총 데이터의 80%를 학습 데이터, 나머지 20%를 예측 데이터로 나누기로 했다.
split_count = int(0.8*df.shape[0])
# df.shape[0] = 768
# 0.8 * 768 = 614.4
# split_count = int(614.4) = 61480%에 근접한 614번째 index를 기준으로 나눠줄 것이다.
# 0부터 613번 열까지 포함
# .copy()를 통해 이전 dataframe이 변형되는 일을 방지하자
train = df[:split_count].copy()
이렇게 0번째부터 613번째까지 행을 train이라는 변수 안에 나눠 넣었다.
예측 데이터도 동일하게 test라는 변수에 담아준다.
# 614번째 이후의 열만 포함
test = df[split_count:].copy()
- 학습, 예측에 사용할 컬럼 명시 -
데이터셋 중 우리가 학습 시킬 데이터를 포함한 각각의 컬럼을 feature라고 부른다. Dataframe 중, Outcome 컬럼을 제외하고는 다 우리 학습 및 예측에 사용할 컬럼들이기에 해당 컬럼들의 명칭을 feature_names라는 변수에 리스트로 담는다. 또한 Outcome 컬럼명은 별도로 label_name이라는 변수에 담는다.
# 마지막 Outcome 컬럼은 제외
feature_names = df.columns[:-1].tolist()
# 모델이 예측할 Outcome 컬럼은 label_name에 담는다.
# label_name은 하나의 컬럼명만 포함하기 때문에 .tolist()를 사용할 필요가 없다.
label_name = df.columns[-1]
feature_names와 label_name이라는 변수들을 만든 이유는 dataframe에서 원하는 컬럼들을 일일이 명시하지 않고 좀 더 간편하게 불러오기 위해서다.
- 학습, 예측 데이터셋 만들기 -
이제 위에 만들어준 train, test, 그리고 feature_names, label_name 변수들을 사용하여 학습세트와 정답값, 예측세트와 정답값을 각각 다른 변수에 저장해 줄 것이다.
# 학습 세트 만들기 (총 데이터의 80%)
X_train = train[feature_names]
# 학습 세트에 대한 정답 값 설정
y_train = train[label_name]
# 예측에 사용할 데이터셋 만들기 (총 데이터의 20%)
X_test = test[feature_names]
# 예측이 얼마나 정확했는지 확인할 정답 값 설정
y_test = test[label_name]
여담으로 X_train과 X_test의 X가 대문자이고 y_train과 y_test의 y가 소문자인 이유는 선형 대수 공식에서 행렬은 대문자로, 벡터는 소문자로 표기하는 관습 때문이다. 실제로 각 변수의 .shape을 보면,
# X_train과 X_test는 행렬 형태
>>> X_train.shape
(614, 8)
>>> X_test.shape
(154, 8)
# y_train과 y_test는 벡터 형태
>>> y_train.shape
(614,)
>>> y_test.shape
(154,)위와 같은 것을 확인할 수 있다. 또한 .shape을 확인함으로써 학습 데이터인 X_train과 예측용 데이터인 X_test의 컬럼 수가 8개로 같은 것을 볼 수 있다. 두개의 컬럼이 동일해야만 학습한 내용을 바탕으로 모델이 예측을 할 수 있다.
1.2.3 의사결정나무로 학습과 예측하기
1. 머신러닝 알고리즘 가져오기
알고리즘을 제대로 사용하기 위해서는 내부 메커니즘에 대해 자세히 알 필요가 있지만, 일단은 알고리즘을 사용하면서 친숙도를 높여보자. 우리의 목표는 독립변수들인 feature값들을 사용하여 범주형 종속변수인 Outcome을 예측하는 것이다. 이것은 분류 문제로서 해당 문제를 풀기 위해 우리는 DecisionTreeClassifier라는 알고리즘을 사용할 것이다.
* DecisionTreeClassifier의 내부 메커니즘에 대한 자세한 설명은 링크를 참조
# Scikit-Learn에서 해당 알고리즘 불러오기
from sklearn.tree import DecisionTreeClassifier
# 모델이라는 변수에 담기 (부르기 편하도록)
model = DecisionTreeClassifier()
2. 학습
학습을 위해 DecisionTreeClassifier의 .fit이라는 메소드를 사용할 것이다.
해당 메소드의 사용법을 좀 더 자세히 알기 위해 model.fit?이라는 코드를 실행하면 다음과 같은 설명이 나온다:
* shift+tab키나 '?'를 활용하여 특정 메소드의 사용법을 알 수 있다.
Signature: model.fit(X, y, sample_weight=None, check_input=True)
Docstring:
Build a decision tree classifier from the training set (X, y).
Parameters
----------
X : {array-like, sparse matrix} of shape (n_samples, n_features)
The training input samples. Internally, it will be converted to
``dtype=np.float32`` and if a sparse matrix is provided
to a sparse ``csc_matrix``.
y : array-like of shape (n_samples,) or (n_samples, n_outputs)
The target values (class labels) as integers or strings.
sample_weight : array-like of shape (n_samples,), default=None
Sample weights. If None, then samples are equally weighted. Splits
that would create child nodes with net zero or negative weight are
ignored while searching for a split in each node. Splits are also
ignored if they would result in any single class carrying a
negative weight in either child node.
check_input : bool, default=True
Allow to bypass several input checking.
Don't use this parameter unless you know what you're doing.
Returns
-------
self : DecisionTreeClassifier
Fitted estimator.
File: /usr/local/lib/python3.10/dist-packages/sklearn/tree/_classes.py
Type: method
설명에서 볼 수 있듯이, 우리가 학습하기 원하는 데이터를 X에, 그리고 그 학습한 데이터에 대한 정답을 y에 넣어서 모델을 학습시킬 수 있다. (sample_weight와 check_input 같은 매개변수들은 이후에 차차 살펴보겠다)
# 학습할 데이터와 정답값을 인수로 입력
model.fit(X_train, y_train)위 코드를 실행하면 DecisionTreeClassifier 모델이 학습 데이터를 기반으로 학습을 완료했다.
3. 예측
이제 학습을 완료한 모델을 한번 시험해보자.
.predict에서 y_test를 인수로 넣지 않는 이유는 정답을 알지 못하는 상태에서 데이터만을 가지고 모델에게 예측을 시키는 것이기 때문이다. 시험을 치러 갔는데 답을 다 적어와서 시험을 쳐봤자 수험자의 성과에 대해 어떤 평가를 할 수 있겠는가.
# 예측 데이터만을 입력해 y_predict를 도출
>>> y_predict = model.predict(X_test)
>>> y_predict.shape
(154,)y_predict의 모양를 봤을 때, 위에서 본 y_test의 모양이랑 동일한 것을 볼 수 있다.
1.2.4 예측한 모델의 성능 측정하
1. 트리 알고리즘 분석하기
- 의사결정나무 시각화 -
과연 의사결정나무 모델이 어떤 식으로 데이터에 대한 분류를 했는지 시각화를 통해 알아보자.
Scikit-learn의 plot_tree 모듈을 이용해서 시각화를 했다.
# 시각화 메서드를 불러온다
from sklearn.tree import plot_tree
plt.figure(figsize=(20,20)) # 시각화한 도면의 사이즈를 좀더 보기 쉽게 키움
tree = plot_tree(model, # 우리가 학습한 모델
feature_names=feature_names, # feature명 목록
filled=True, # 색깔 분류
fontsize=10) # 글꼴 키우기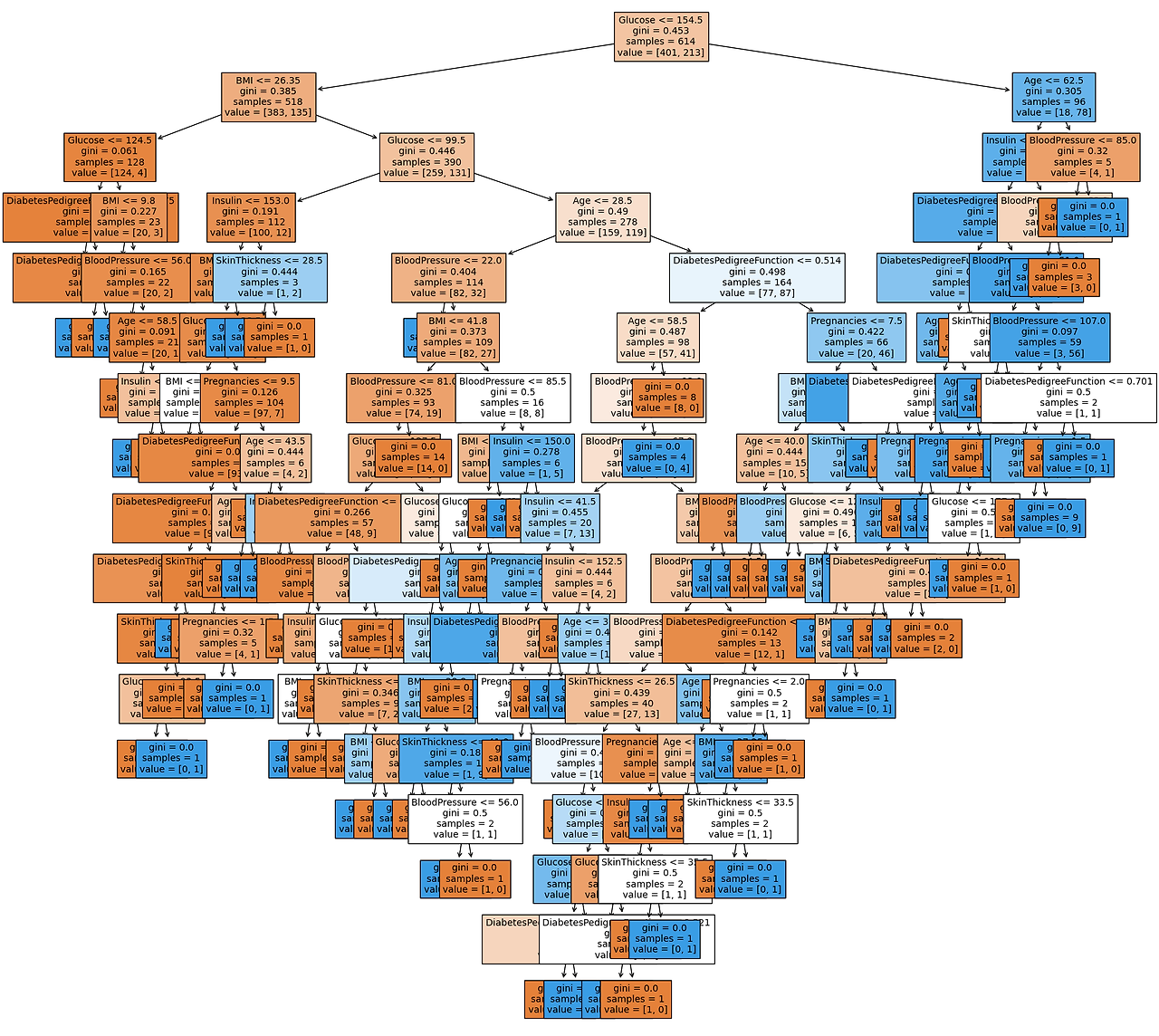
파마 인디언 당뇨병 데이터셋을 학습한 의사결정나무의 시각화
시각화를 해보면 글루코스, BMI 등으로 tree의 가지가 나눠지기 시작한다는 것을 볼 수 있다.
시각화한 의사결정나무를 좀 더 자세히 들여다 보면 각 셀이 다음과 같음을 볼 수 있다.

첫번째 줄: 의사결정이 어떤 feature를 사용해서 어떤 조건으로 가지를 나눴는지
두번째 줄: 지니계수 (지니계수가 낮을수록 데이터 균일도가 높다고 해석한다)
지니계수가 0에 다다르면 나무의 가지치기 과정이 완료했다는 것을 의미한다.
세번째 줄: 해당 결정에서 분류한 총 샘플 수
네번째 줄: 각각의 가지에 몇개의 샘플이 포함되어 있는지
- graphviz를 이용한 시각화 -
너무나 셀들이 겹쳐서 보기 어려운 경우, graphviz를 통해서도 시각화를 할 수 있다. 이때 필요한 코드는 아래와 같다.
다만 graphviz는 별도의 설치가 필요하고 파이썬에서 graphviz를 사용할 수 있게 해주는 도구 2가지 다 설치해 주어야 한다.
import graphviz
from sklearn.tree import export_graphviz
dot_tree = export_graphviz(model, feature_names = feature_names, filled=True)
graphviz.Source(dot_tree)여기서 보이는 시각화는 전체적인 그림을 보기엔 너무 크게 나와 별도의 이미지 첨부를 하지 않았다.
- 피처의 중요도 추출 -
모델이 사용한 각 피처가 의사결정나무의 가지치기 과정에서 얼마나 큰 기여를 했는지를 볼 수 있다.
>>> model.feature_importances_
array([0.06137709, 0.32191331, 0.13929563, 0.0555647 , 0.06103479,
0.14596633, 0.10757799, 0.10727016])
숫자만으로는 기여도를 파악하기 쉽지 않음으로 해당 결과를 바그래프를 이용해 시각화 했다.
여기서 사용된 라이브러리는 seaborn(sns) 라이브러리이다.
sns.barplot(x = model.feature_importances_, y = feature_names)
Seaborn으로 시각화한 각 feature의 중요도
이렇게 시각화해서 보았을 때 Glucose 수치가 대상이 당뇨병 환자인지 아닐지를 판단할 때 가장 크게 작용하는 요소인 것을 볼 수 있다. 이 다음으로는 BMI와 BloodPressure 수치들이 중요하다는 것을 볼 수 있다. 의외로 Insulin 수치가 중요할 것 같았는데, 별로 중요도가 높지 않게 나왔다. 이 점에 대해서는 차후에 데이터를 뜯어보면서 feature 엔지니어링을 통해 정확도를 높일 수 있는지 보도록 하겠다.
2. 정확도(Accuracy) 측정하기
모델의 예측 정확도라 함은 예측해서 나온 결과인 y_predict와 정답인 y_test가 얼마나 같은지를 확인하는 것이다.
우리가 만든 모델이 어느 정도 성능을 내는지 확인하는 방법이다.
y_predict와 y_test가 얼마나 차이나는지 보자:
# 실제 정답과 예측한 정답의 차를 합하여 diff_count 변수에 넣는다
>>> diff_count = abs(y_test - y_predict).sum()
>>> diff_count
44* 모델의 옵션에서 다양한 값들이 랜덤하게 들어가므로 모델을 학습할 때마다 수치는 다르게 나올 수 있다.
총 y_test가 갖고 있는 154개의 샘플 중에서 44개를 잘못 예측했으니 우리의 정확도는:
(154 - 44) / 154 * 100 = 71.42857142857143
대략 71.43%의 정확도를 보인 것이다.
위 계산을 코드로 변환하면 아래와 같다:
>>> (len(y_test) - diff_count) / len(y_test) * 100
71.42857142857143
직접 위처럼 계산해서 정확도를 구할 수도 있지만 이미 사이킷런에 탑재되어 있는 함수들을 사용할 수 있다:
- 사이킷런에 있는 accuracy 메트릭
- 모델에 탑재된 score 함수
# 1번 방식
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict) * 100
# 2번 방식
model.score(X_test, y_test) * 100
똑같은 계산 법을 적용하는 거기에 결과는 둘다 동일하게 71.42857142857143이 나온다.
이로서 피마 인디언 당뇨병 데이터셋을 이용해 의사결정나무로 간단한 분류 예측 모델을 만들어 보았다.
1. 캐글 데이터 Telcom Customer Churn(이탈 고객 분류)
- 분석배경 및 목적
- 신용카드 신청자의 개인정보와 이력데이터(historical data)를 바탕으로 미래의 채무불이행 가능성 또는 신청고객에 대한 신용카드 발급여부를 예측하고자 함
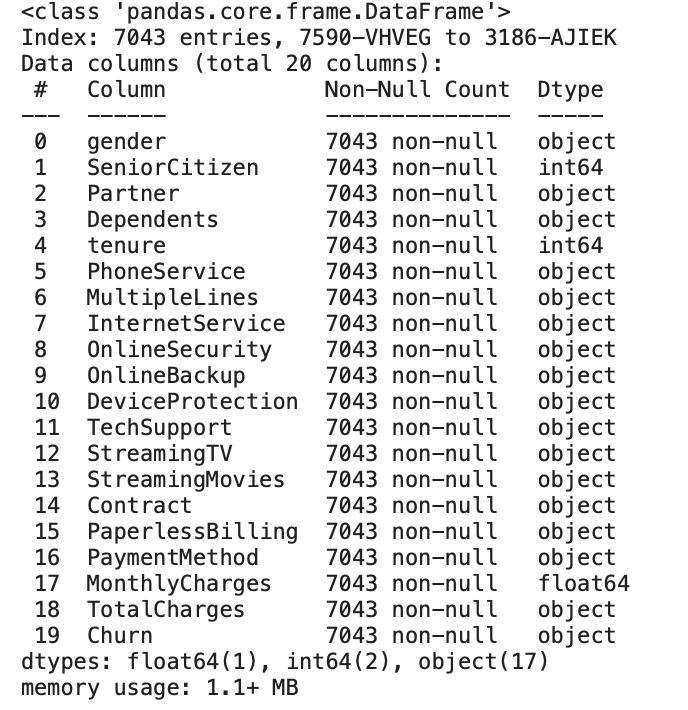
- gender: 고객의 성별
- SeniorCitizen: 고객이 노인 시민인지 여부
- Partner: 고객이 파트너(배우자)가 있는지 여부
- Dependents: 고객이 부양 의무가 있는지 여부
- tenure: 고객이 서비스를 사용한 개월 수
- PhoneService: 고객이 전화 서비스를 사용하는지 여부
- MultipleLines: 고객이 여러 회선을 사용하는지 여부
- InternetService: 고객이 인터넷 서비스를 사용하는 종류
- OnlineSecurity: 온라인 보안 서비스 사용 여부
- OnlineBackup: 온라인 백업 서비스 사용 여부
- DeviceProtection: 기기 보호 서비스 사용 여부
- TechSupport: 기술 지원 서비스 사용 여부
- StreamingTV: 스트리밍 TV 서비스 사용 여부
- StreamingMovies: 스트리밍 영화 서비스 사용 여부
- Contract: 고객의 계약 유형
- PaperlessBilling: 전자 청구 여부
- PaymentMethod: 결제 방법
- MonthlyCharges: 월간 서비스 요금
- TotalCharges: 누적 서비스 요금
- Churn: 이탈 여부
1.1 데이터 전처리
데이터 전처리란 데이터 분석을 위해 수집한 데이터를 분석에 적합한 형태로 가공하는 과정으로 데이터 전처리를 통해 불필요한 데이터를 제거하고, 결측치나 이상치를 처리하여 데이터의 질을 향상할 수 있다. ML 알고리즘은 데이터에 기반하고 있기 때문에 어떤 데이터를 입력으로 가지느냐에 따라 결과도 크게 달라질 수 있다. 데이터 전처리에는 다음과 같은 과정이 있다.
- 결측치 처리
- 데이터에 결측치(누락된 값)가 있는 경우, 이를 처리한다. 일반적인 방법으로는 삭제, 대체(평균, 중앙값, 최빈값 등으로), 예측 모델 활용 등이 있다
- 이상치 처리
- 이상치(outliers)는 다른 데이터와 동떨어진 값으로, 모델의 성능을 낮출 수 있다. 이를 확인하고 처리하는 방법으로는 제거, 대체, 변형 등이 있다.
- 데이터 탐색 및 시각화
- 데이터의 특성을 탐색하고, 시각화를 통해 데이터의 분포와 패턴을 파악한다. 이는 모델의 이해를 돕고 불필요한 특성을 찾는 데 도움이 된다.
- 특성 스케일링
- 다양한 특성 간의 범위를 일치시키기 위해 스케일링을 수행한다. 주로 사용되는 방법으로는 표준화(standardization) 또는 정규화(normalization)가 있다.
- 피처 엔지니어링
- 기존의 특성을 이용하여 새로운 특성을 생성하거나, 특성을 변환하여 모델에 더 유용한 정보를 제공하는 작업을 수행한다.
- 범주형 데이터 처리
- 머신러닝 모델은 주로 숫자로 된 데이터를 다루므로, 범주형 데이터를 숫자로 변환하는 작업이 필요하다. 원-핫 인코딩, 레이블 인코딩 등이 사용된다.
- 데이터 분할
- 전체 데이터를 학습 데이터와 테스트 데이터로 나누어 모델을 훈련하고 검증하는 데 사용한다.
1.1.1 데이터 탐색 및 시각화
먼저 수치형 변수인데 명목형 변수의 타입을 띠거나 그 반대의 경우를 가진 경우, 적절한 타입으로 변환을 하였다. 특히 고객 이탈 여부를 나타내는 Churn 변수 속 yes = 1, no = 0으로 변환해 주었다.

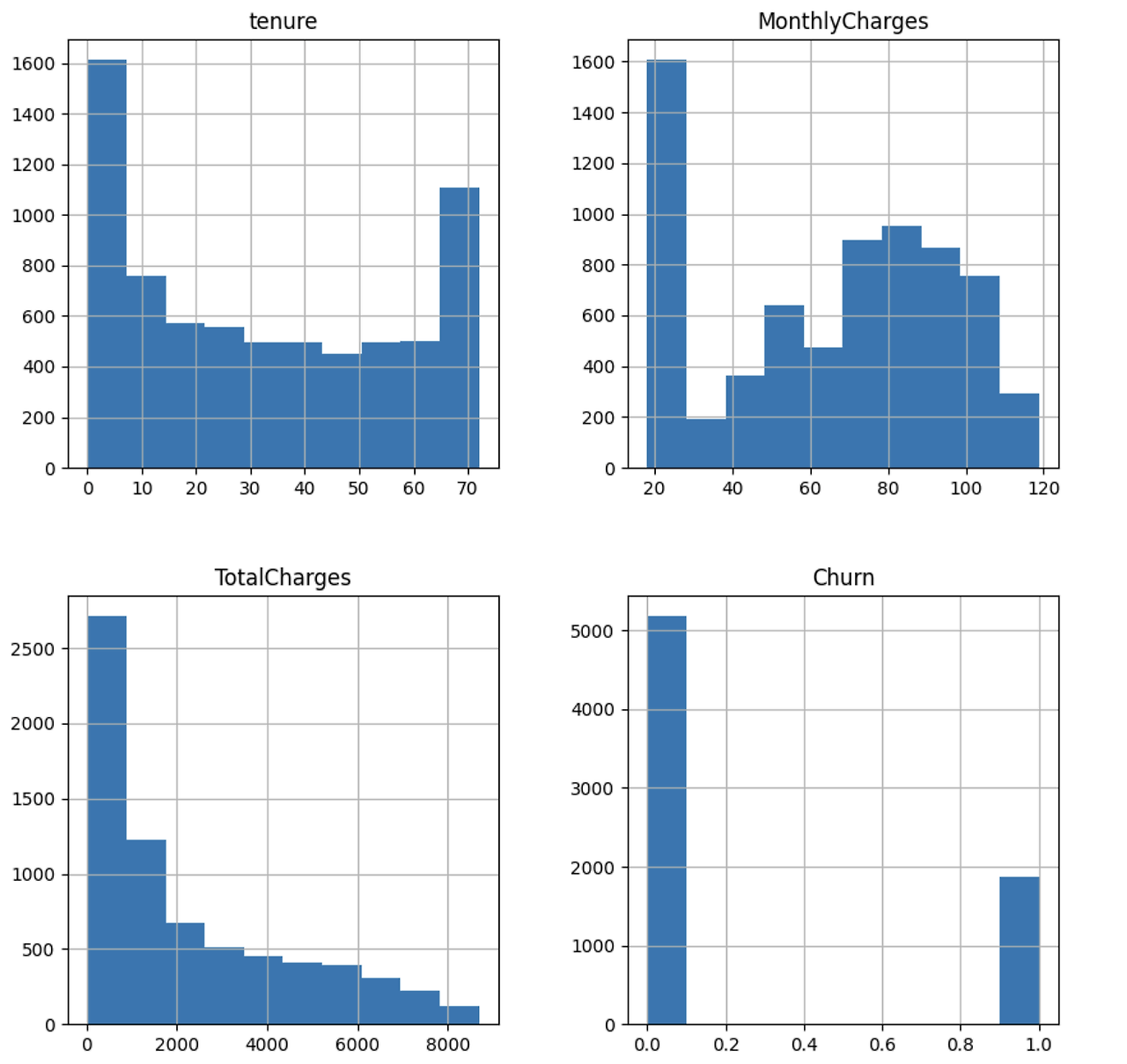
수치형 변수들의 분포를 시각화해 본 결과 한쪽으로 치우쳐지거나 긴 꼬리(long tail)를 가진 것을 볼 수 있다. 일반적으로 데이터가 정규분포의 형태를 가져야 ML 알고리즘의 예측성능이 뛰어나기에 log 변환이나 min-max 변환을 해준다. Churm의 값 또한 불균형하게 분포하고 있음을 볼 수 있다. 만약 선형 회귀와 같은 선형적인 모델을 통해 예측을 수행했다면 반드시 정규분포로의 근사 과정을 거쳐야 한다. 그러나 트리 계열의 모델은 이러한 분포에 크게 영향을 받지 않는다.
1.1.2 결측치 처리
결측값이란 NA,999999, ' '(공백) 등으로 표현되는 것으로 결측값 처리는 전체 작업 속도에 많은 영향을 준다. 결측값 자체의 의미가 있는 경우도 있는데 예를 들어 쇼핑몰 가입자 중 특정 거래 자체가 존재하지 않는 경우와 인구 통계학적 데이터에서 아주 부자이거나 아주 가난한 경우 자신의 정보를 채워 넣지 않기 때문에 결측치를 통해 가입자의 특성을 유추할 수 있다. 따라서 결측치의 처리는 해당 데이터 세트의 특성을 고려하고 활용 목적등을 고려하여 처리해야 한다
결측치 처리방법
1. 단순 대치법(Single Imputation): 결측값이 존재하는 레코드를 제거하거나 관측 또는 실험을 통해 얻어진 데이터의 평균으로 대치한다.
2. 다중 대치법(Mutiple Imputation): 단순 대치법을 한번 하지 않고 m번의 대치를 통해 가상의 완전 자료를 만드는 방법이다.
-수치형 변수의 결측치 처리

위의 타입 변환 과정에서 'TotalCharges'가 11개의 결측치가 존재함을 알 수 있었다. 따라서 두 가지 방식을 사용할 수 있었는데 첫 번째는 데이터들의 중앙값으로 결측치를 대체하는 것이었다. 데이터들의 평균을 이용하지 않은 이유는 'TotalCharges'의 데이터가 정규분포가 아닌 왜곡된 형태를 가졌기 때문이다. 극단적인 값이 존재하는 경우, 평균이 아닌 중앙값이 그 데이터들을 더욱 잘 대표한다. 두 번째는 해당 레코드를 삭제하는 것이다. 이와 같은 방식을 선택할 수 있는 이유는 'TotalCharges' 의 결측치가 11개로 그 수가 적었기 때문이다. 만일 결측치의 수가 많음에도, 해당 레코드들을 삭제한다면 심각한 정보 손실을 야기할 수 있다. 우리 조는 두번째 방식을 선택했다.
1.1.3 데이터 인코딩
사이킷런 의 머신러닝 알고리즘은 문자열값을 입력 값으로 허용하지 않는다. 따라서 모든 문자열 값은 인코딩 돼서 숫자형으로 변환해야 한다. 머신러닝을 위한 대표적인 인코딩 방식에는 레이블 인코딩과 원-핫 인코딩이 있다
1. 레이블 인코딩(Label encoding): 카테고리 피쳐를 코드형 피쳐로 변환하는 것(ex 냉장고:1, 선풍기:2)
2. 원-핫 인코딩(One-Hot Encoding): 피처 값의 유형에 따라 새로운 피쳐를 추가해 고윳값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방식(ex 냉장고[10000], 선풍기[010000])
우리 조는 트리 기반의 ML알고리즘을 이용하기 때문에 레이블 인코딩을 사용하기로 했다. 그러나 인코딩하기 전 거쳐야 할 과정이 있다
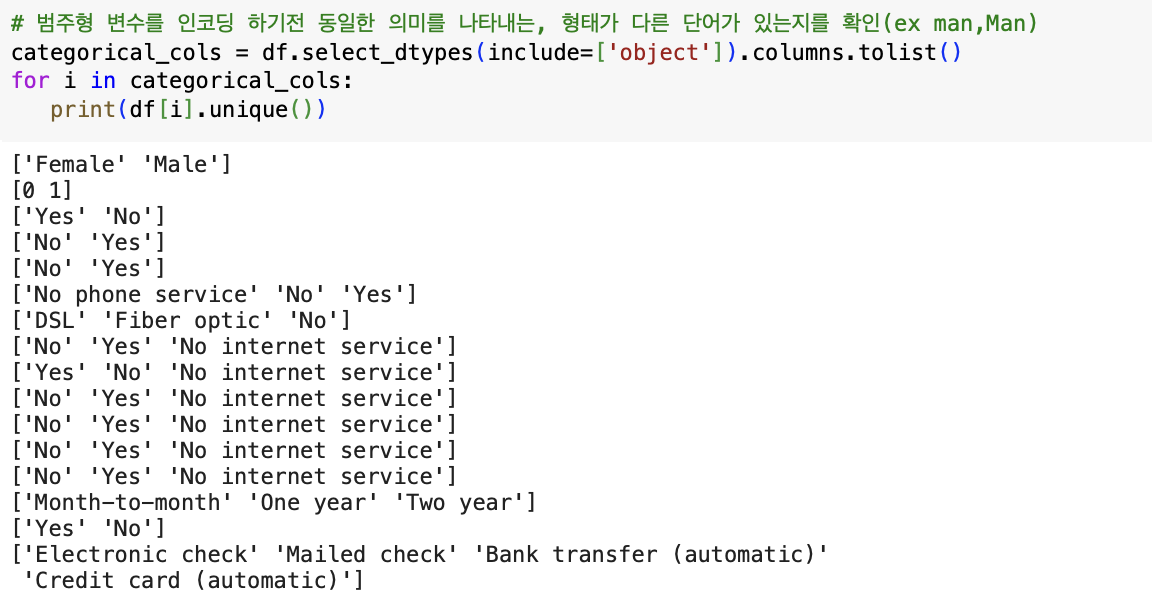
범주형 변수의 경우, 동일한 의미를 나타내지만, 형태가 다른 단어가 존재하는 경우가 있다. 예를 들어, 예전에 분석했던 소상공인 상권 데이터 속 KFC라는 특정 상호명의 경우 kfc, kFC 등 여러 형태의 데이터가 존재했다. 이는 불필요한 중복을 야기하고 모델의 성능을 떨어트리는 요인이 될 수 있다. unique() 함수를 통해 각 범주형 변수의 데이터들을 살펴본 결과, 그러한 형태의 데이터는 존재하지 않았다. 해당 작업을 한 후, 레이블 인코딩을 실시했다. 레이블 인코딩을 실시할 경우, 범주형 변수의 숫자 변환이 단순 코드가 아니라 숫자에 따른 순서나 중요도로 인식되어서는 안 된다는 것을 주의해야 한다. 그러나 앞서 말했듯 트리 계열의 ML알고리즘은 숫자의 이러한 특성을 반영하지 않아 레이블 인코딩을 하여도 큰 문제가 되지 않는다.

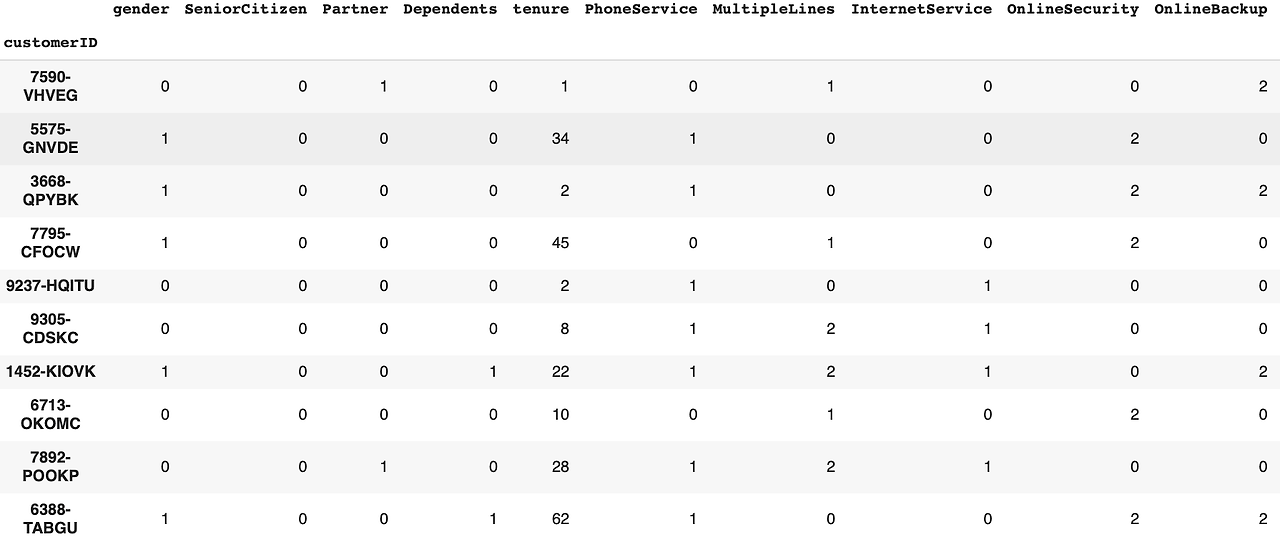
다음은 전처리가 된 최종 데이터 프레임의 일부이다.
'Study > CODE 2기 [프로젝트로 배우는 데이터사이언스]' 카테고리의 다른 글
| [Trillion(1조)] 프로젝트로 배우는 데이터사이언스_2주차 (0) | 2024.03.18 |
|---|---|
| [All in One(2조)] 프로젝트로 배우는 데이터사이언스_2주차 (1) | 2024.03.18 |
| [삼위일체(3조)] 프로젝트로 배우는 데이터 사이언스_2주차 (0) | 2024.03.18 |
| [삼위일체(3조)] 프로젝트로 배우는 데이터 사이언스 (0) | 2024.03.11 |
| [All in One(2조)] 프로젝트로 배우는 데이터사이언스_1주차 (0) | 2024.03.11 |



