1.1 사이킷런과 머신러닝
1.1.1 사이킷런 소개

scikit learn이란 파이썬의 대표적인 머신러닝 라이브러리이다.
scikit learn 의 기능
1. classification : 분류 작업 시행
예를 들어, 고객이 물건을 구매할 것인지, 또는 광고를 클릭할 것인지 아닌지와 같은 분류 작업에 사용된다.

맨 왼쪽줄의 세 input 값에 대한 성능을 비교하고 있는데, 어떤 알고리즘을 사용하는지에 따라 성능이 차이 나는 것을 볼 수 있다.
2. regression: 회귀 ( 관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정)
regression 은물건의 가격을 예측할 때, 또는 광고의 효율, 판매량 등이 얼마나 나올지를 예측할 때 사용한다.

이 외에도 clustering, Dimensionality reduction, Model selection, Preprocessing 등이 있다.
1.1.2 사이킷런 활용 흐름
들어가기 전에 supervised learning 와 unsupervised learning 의 차이점을 알아보자.
supervised learning(지도학습) : 정답이 있는 데이터를 통한 학습
>> classification, regression
unsupervised learning(비지도학습) : 정답이 없는 데이터를 통한 학습
>> clustering, dimensionality reduction
supervised learning(지도학습)

training data 와 training labels 을 통해 반복적으로 학습을 시키는 과정을 모델링이라고 한다.비유하자면, 기출 문제를 푸는 것과 같은 과정이라고 생각할 수 있다.

학습된 모델에 test data 를 넣어 예측을 만들어낸다.
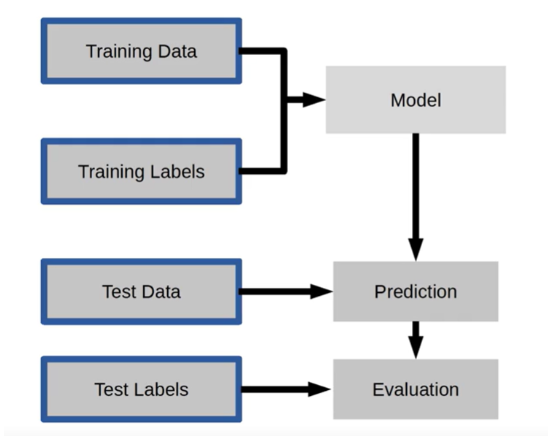
마지막으로 학습된 모델이 실제 상황에서 제대로 prediction 을 했는지 검증하는 단계를 거친다.
시험의 정답이라고 할 수 있는 test labels 를 활용하여 모델이 test data 를 통해 제대로 된 예측을 했는지 평가한다.
이제 그 과정을 더욱 구체화하여서 살펴보자.

clf 로 Randomforestclassifier()를 불러온 후,
clf.fit 로 x_train와 y_train 에 각각 문제와 정답을 넣어 모델을 학습시킨다.

학습된 모델을 통해 clf.predict 로 실제 데이터를 집어넣어 prediction 하는 과정을 거친다.
마지막으로, clf.score에 x_test 에 대응하는 y_test 를 입력하여 우리의 모델이 효과적인 예측을 하는지 evaluation 한다.
unsupervised learning(비지도학습)
위에서 언급했지만 supervised learning 와의 가장 큰 차이점은 정답 데이터 없이 예측에 활용된다는 점이다.
clustering(군집화), dimensionality reduction(차원 축소) 에서 주로 비지도 학습을 하는데
군집화는 주로 쇼핑몰에서 비슷한 고객군에게 물건을 추천을 해주거나, 프로모션을 하는 등 고객을 군집화하여 마케팅 계획을 세울 때 사용한다.

흐름은 위와 같이 training data를 통해 모델을 학습시키면 이 모델이 test data 를 통해 새로운 결과를 만들어낸다.

다음은 비지도학습을 통해 차원 축소를 하는 과정인데 이 때 주로 pca 라는 모델 객체를 사용한다.
Cross Validation (교차 검증하기)
교차 검증은 데이터를 여러 부분으로 나누고, 각 부분을 훈련과 테스트 용도로 번갈아 사용하여 모델을 평가하는 방법으로 이를 통해 모델의 일반화 성능을 더 정확하게 측정할 수 있다.

위 과정을 통해 다섯개의 split으로 쪼갠 후, fold들의 평균 점수를 계산해서 점수가 가장 높은 모델을 찾아낸다.
1.2.1 당뇨병 데이터셋 소개
데이터 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)%2)
- DiabetesPedifreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
kaggle에서 제공하고 있는 피마인디언 당뇨병 데이터가 들어있는 링크입니다.
Pima Indians Diabetes Database (kaggle.com)
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com
*sklearn에서도 피마인디언 당뇨병 데이터셋이 있지만, sklearn에서는 442개, kaggle에서는 768개의 행의 데이터셋을 제공하고 있기 때문에 더 많은 데이터셋을 제공하고 있는 kaggle의 데이터셋 사용을 추천드립니다.
1.2.2 학습과 예측을 위한 데이터셋 만들기
학습 목표: 학습과 예측을 위해 데이터셋을 나누는 방법을 이해합니다.
핵심 키워드
- train 데이터셋
- test 데이터셋
- 슬라이싱
2 필요한 라이브러리 로드

>pandas as pd로 데이터셋 불러오기
>파이썬에서 대표적으로 사용할 수 있는 대표적인 수치 계산용 numpy library 로드하기
>sns로 seaborn을 로드
>matplot.pyplot 로드
*구버전 주피터 노트북에서는 시각화가 표현이 안 되는 경우가 많기 때문에 matplotlib inime 이 필요하다.
*새로운 버전에서는 필요하지 않다.
3 데이터셋 로드
데이터셋은 주피터노트북고 같은 경로에 두어야 관리하는 것이 어렵지 않고 불러올 때 경로 설정하기가 좋은 편이다.
같은 경로에 저장하는 것을 권장한다.

df로 변수 저장 후, shape으로 데이터 개수를 보았다. 768개 행과 9개 열로 되어있는 것을 볼 수 있다.
head를 사용해 데이터를 미리 확인해보았다.

여기서 outcome은 우리가 예측해야 될 데이터이다.
보통 데이터셋을 가져오면 문자나 결측치가 섞여있을 경우 전처리가 필요한데, 불러온 데이터는 모두 숫자로 되어 있어서 따로 전처리를 해줄 필요가 없다.
그래서 우리는 바로 머신러닝 알고리즘을 불러와서 예측을 하면 된다.
4 학습, 예측 데이터셋 나누기
이제 데이터를 학습할 데이터와 예측할 데이터로 나눠주어야 한다.

> shape을 이용해서 768개의 행을 확인하고, 튜플 형태로 행과 열의 개수를 출력한다.

> 0번째 값은 행의 값만을 가져오게 된다.
행의 값에서 0.8을 곱하면 614.4000이라는 값이 나오는데, 소수점을 제외하기 위해서 int를 사용할 것이다.
int로 인해 614라는 정수의 값으로 값이 나오게 된다.
이렇게 나온 값을 split count라는 변수에 담아준다.

> train과 test데이터셋을 나눠줄 때, 614번째의 행을 기준으로 나누어준다.

> df를 통해 모든 데이터를 확인할 수 있었다.
613번 데이터까지만 가져오고 싶다면, 위에서 지정한 split_count를 넣어본다.
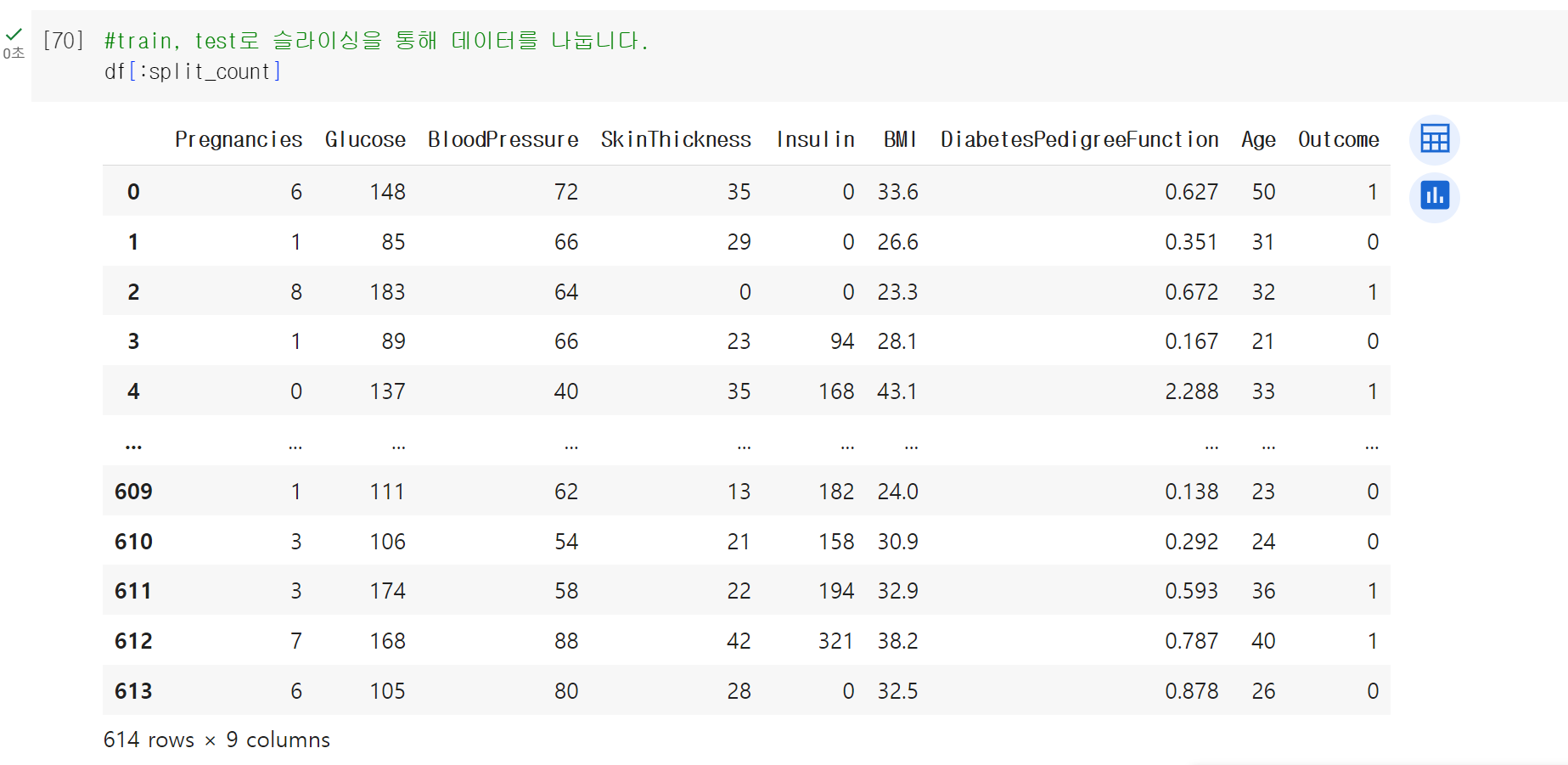
위에서 다룬 값을 train이라는 변수에 담아보았다.
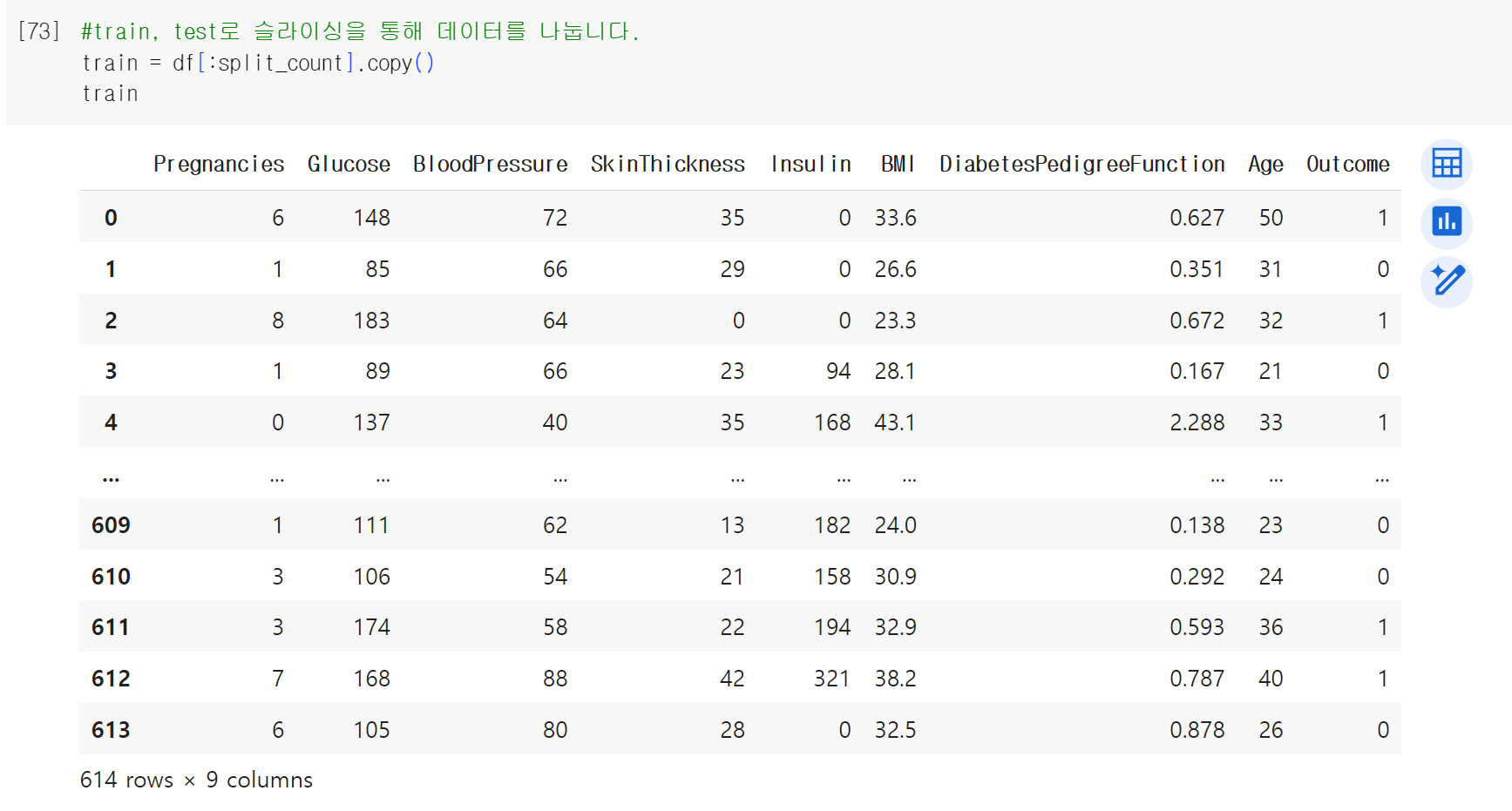
> 새로운 변수에 담을 때 그냥 담아도 되지만, train이라는 데이터에 새로운 열을 추가한다든가, 전처리를 한다든지 이러한 상황들을 위해서 명시적으로 .copy를 통해서 명시적으로 복사를 해주는 것이 좋다.
.copy를 통해서 0번부터 613번까지의 값을 담아주었다.

> 9개의 열이 있는 것을 확인해볼 수 있고, shape찍어보면 614개의 행과 9개의 행을 볼 수 있는 것을 알 수 있다.
test 데이터셋도 마찬가지로 똑같이 슬라이싱을 진행시킨다.
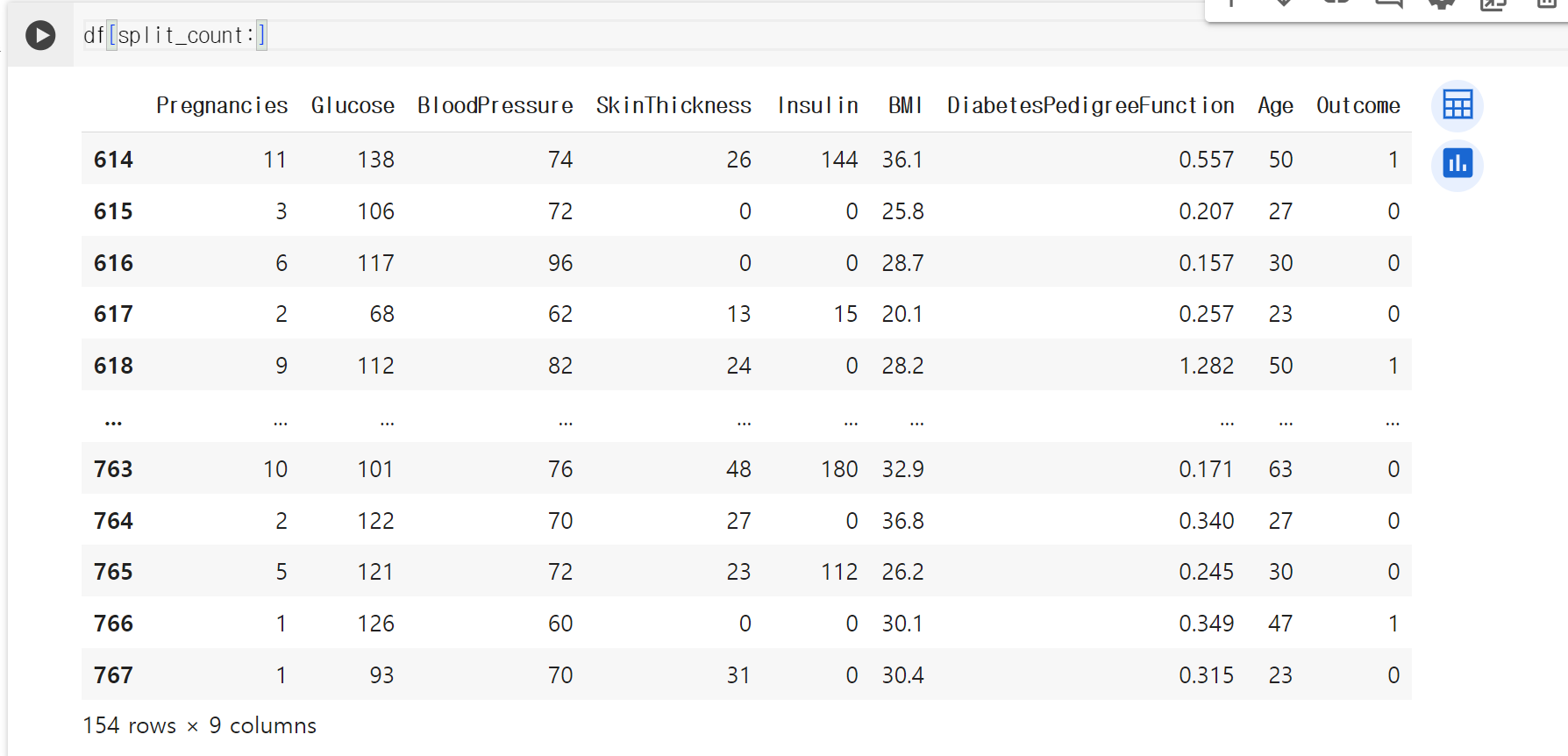
> 이번에는 앞에 split_count를 넣어서 614번부터 767번까지 총 154개의 행을 가지고 왔다. 위에서 데이터 셋을 8:2의 비율로 나눠주기 위해 80퍼센트를 train으로, 나머지 20퍼센트를 test로 만들어주었다.
이렇게 만든 데이터셋을 .copy 해주고 test라는 변수에 담은 후 shape을 보았다.

> 154개의 행과 9개의 열로 이루어진 것을 볼 수 있었다. 학습/테스트 데이터셋을 나눠준 과정이었다.
5 학습, 예측에 사용될 컬럼
이제 학습, 예측에 사용할 컬럼명을 담아주도록 하겠다.

> train_columns를 이용해서 모든 column의 명을 보았다.

> 이 열에서는 outcome을 제외한 모든 열을 정답값으로 사용할 것이기 때문에, 리스트 슬라이싱을 통해 outcome만 제외하여 데이터를 가져와보았다.
또한 리스트의 형태로 바꾸고 싶을 때는 tolist()라는 것을 이용해 리스트 타입의 형태로 데이터를 바꿀 수 있다.

이 데이터를 feature names라는 변수에 담는다.

> feature names에는 학습과 예측에 사용될 데이터들을 담아주었다.
6 정답값이자 예측해야 될 값
정답값이자 예측해야 될 값을 넣어주었다.

train.columns를 이용해 데이터를 본 후, outcome값을 따로 가지고 올 것이다.

outcome만 따로 뺀 값을 label_name에 담아준다.

**여기서 잠깐**
feature_name은 리스트 형태로 만들었는데, label_name은 리스트 형태가 아니냐고 묻는 질문이 있다.
그 이유는 feature_name에는 여러 개의 값을 가지고 올 것이기 때문에 list 형태로 만들어주었고,
label_name은 outcome 하나만 사용할 것이기 때문에 string 형태로 변수에 지정을 해준 것이라고 답할 수 있겠다!
이렇게 데이터 슬라이싱부터 학습/예측에 사용할 컬럼, 정답값/예측해야 될 값을 변수에 지정해주었다.
이제 변수에 저장한 값들을 학습/예측에 사용할 데이터셋을 만들어줄 것이다.
이것은 시험의 기출문제와 시험출제 문제를 만드는 과정과 유사하다고 느낄 수 있을 것 같다.
7 학습, 예측 데이터셋 만들기

> train에는 outcome(예측을 해야 하는 정답값)까지 들어있다.

> feature names라고 위에서 만들었던 col을 train에 지정해주면 이에 해당되는 컬럼을 가져오게 된다.
X_train이라는 변수에 담아보았다.

> .shape을 찍어보면 614개의 행과 8개의 열로 이루어져있다는 것을 알 수 있었다.
head로 미리 데이터를 확인해보았다.
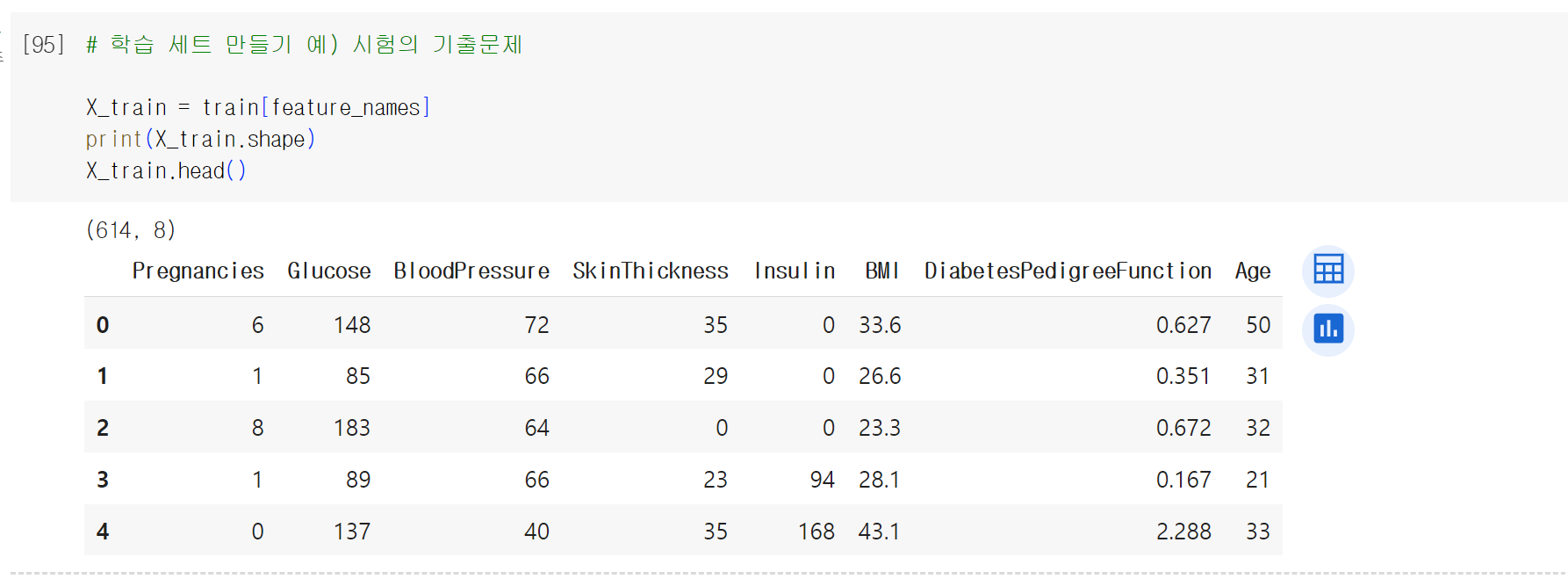
> pregnancies부터 age까지 있는 것을 볼 수 있었다.
이제는 정답값을 만들어줄 차례이다.

> 정답값을 만들어줄 텐데 정답은 기출 문제의 정답 label_name에 outcome을 담아줬었다.
> 따라서 train에 label_name을 담게 되면 0과1로 된 당뇨병일 때는 1, 아닐 때는 0인 값들이 들어있다.
이 값은 y_train이라는 변수값에 넣어주었다.

> head로 미리 보기를 해주고, 개수를 보기 위해 shape을 사용하였다.
**여기서 잠깐**
이때, 우리의 기출문제와 정답의 행의 개수가 똑같아야 한다.
문제가 614개니까 정답도 614개가 되어야 개수가 맞기 때문이다.
그래서 학습에 사용될 기출문제와 기출문제의 정답을 변수에 담아줬다. 문제는 X_train으로 되어있고, 정답값은 y_train으로 되어있는데 이제 X는 행과 열로 되어있고 y는 벡터의 값으로 되어있다는 것을 확인할 수 있다.
이제 기출문제를 만들었으니까, 실전 시험 문제를 들어야 한다.

> 실전 시험문제를 test에서 가져오는데,
기출 문제를 만든 것처럼 feature_names를 넣게 되면 label을 제외한 feature_names의 열들만 가져오게 된다.
> feature_names을 train에서 가져왔던 것처럼 test에서 가지고 와준다.
그리고 X_test라는 변수에 담아주었다.

> shape을 이용해거 154개인 것을 확인했고, head를 통해 미리 데이터를 확인해보았다. prg~age까지 총 8개이다.
> 기출문제에서도 열이 8개였기 때문에 이제 실전문제에서도 열이 8개가 되어야 예측을 비교할 수 있다. 실전에서는 예측의 정답값을 알 수 없다. 하지만 우리는 이미 정답을 알고 있기 때문에, 실전에 적용해보기 전에내가 만든 모델이 얼마나 좋은 성능을 내는지 테스트를 해야 한다.
y_test를 만들어 주고, test 데이터셋에서 label_name을 가져와주었다.

> 출력하면 614번부터 154개의 데이터가 있는 것을 확인할 수 있었다.
다음은 shape을 이용해서 행의 개수가 일치하는지를 확인해주었다.
head로 데이터를 미리 확인해보았다.

이렇게 학습/예측 시 사용할 데이터셋을 만들어보았다.
앞으로는 기출문제와 기출문제의 정답값, 실전문제와 실전문제에 대한 정답값을 데이터셋을 임의로 나누어서 학습이 잘 되었는지 채점을 해보기 위해서 이 값들을 사용해볼 것이다.
1.2.3 의사결정나무로 학습과 예측하기
학습 목표: 의사결정나무(Decision Tree) 알고리즘으로 데이터를 학습하고, 예측할 수 있습니다.
핵심 키워드: DecisionTreeClassifier, fit, predict
8 머신러닝 알고리즘 가져오기
지금까지 데이터셋을 로드해서 데이터셋을 학습과 예측에 사용할 수 있도록 Train Set와 Test Set으로 나눠주었습니다. 이렇게 나눠준 데이터셋을 바탕으로 머신러닝 알고리즘을 사용해서 학습과 예측을 할 수 있습니다.
먼저, DecisionTreeClassifier를 사용하여 scikit-learn에서 머신러닝 알고리즘을 가져옵니다.
당뇨병인지 아닌지 판단하는 문제는 분류하는 문제에 해당하므로 DecisionTreeClassifier를 사용할 수 있습니다.

이때 'random_state' 매개변수는 난수 생성에 사용되는 시드(seed)를 지정하는 매개변수입니다. 이 매개변수를 특정 값으로 설정하면 모델이 항상 동일한 결과를 출력하도록 만들어줍니다.
특히, 결정 나무(Decision Tree) 모델에서 'random_state'를 설정하는 것은 특정한 순서에 따라 모델의 결과가 달라지는 것을 방지하기 위해서입니다. 결정 나무는 데이터를 분할할 때 가장 좋은 피처와 분할 기준을 선택하는데, 데이터의 순서에 따라 결과가 달라질 수 있기 때문에 'random_state'로 시드값을 고정함으로써 모델이 항상 동일한 분할을 선택하게 합니다.
위의 예시처럼, 시드값이 42로 설정되어 있다면 이에 기반하여 항상 같은 순서와 패턴으로 난수를 생성합니다. 이는 모델이 같은 시드값을 사용할 때마다 동일한 결과를 출력하게 만들어줍니다. 이것은 실험의 결과를 재현하거나 모델을 비교하고 튜닝할 때 일관성을 유지하는 데 도움이 됩니다.
결론적으로, 시드(seed)를 지정함으로써 모델의 무작위성을 제어하고 결과를 예측 가능하게 만들 수 있습니다.
난수(亂數): 정의된 범위 내에서 무작위로 추출된 수.
난수 생성에 사용되는 시드(seed): 무작위 수를 생성하는 알고리즘에서 시작점으로 사용되는 값.
9 학습(훈련)

'fit' 메서드는 머신러닝 모델을 훈련시키는 데 사용됩니다. model이 X-train과 y-train 간의 관계를 학습하고, 새로운 데이터에 대한 예측을 수행할 수 있도록 합니다.
10 예측

'model.predict(X_test)'는 학습된 모델을 사용하여 테스트 데이터를 담은 'X_test'에 대한 예측을 수행하는 역할을 합니다.
모델은 주어진 테스트 데이터 'X_test'에 대해 예측을 수행하고, 그 결과를 'y_predict'에 할당합니다. 'y_predict'는 예측된 타겟 레이블 값들을 담은 배열입니다. 즉, 각각의 테스트 데이터에 대해 모델이 예측한 결과가 'y_predict'에 저장됩니다.
'y_predict[:5]'는 'y_predict'의 처음 5개의 요소를 출력하여 모델의 예측값을 간단히 미리 보는 과정입니다.
1.2.4 예측한 모델의 성능 측정하기
- 모델을 시각화하여 분석하고, feature 중에서 모델에 영향을 미친 정도를 확인할 수 있습니다.
- 정확도를 계산하는 방법을 이해합니다.
- 핵심 키워드: plot_tree, feature_importances, accuracy_score
11 트리 알고리즘 분석하기

from sklearn.tree import plot_tree는 scikit-learn에서 제공하는 결정 트리 모델을 시각화하기 위한 함수입니다. 이를 사용하면 학습된 결정 트리 모델의 구조를 시각적으로 확인할 수 있습니다.
차트의 크기가 작아서 잘 보이지 않는 점을 보완하기 위해 plt.figure(figsize=(20, 20))을 설정하여 Decision Tree의 크기를 키워줍니다. (가로 세로 각각 20인치)
filled=True는 트리의 각 노드를 색으로 채우는 옵션으로, 이를 사용하여 클래스별로 노드를 색칠함으로써 시각적으로 분류 결과를 확인할 수 있습니다.
fontsize=10은 시각화된 트리의 글꼴 크기를 10으로 지정하는 옵션입니다.
최종 출력 결과는 다음과 같습니다.

데이터가 많아 시각화한 모델의 내용이 잘 보이지 않을 때는 graphviz를 활용합니다. 이를 활용하면 글자를 확대하여 볼 수 있어 차트의 가시성을 높일 수 있습니다.

1. import graphviz: graphviz를 사용하기 위해 필요한 모듈을 임포트합니다.
2. from sklearn.tree import export_graphviz: Scikit-learn에서 결정 트리를 graphviz 형식으로 내보내기 위한 함수를 임포트합니다.
3. export_graphviz 함수를 사용하여 model을 graphviz 형식으로 내보냅니다. 이때 feature_names를 지정하여 특성의 이름을 제공합니다. 또한, filled=True를 설정하여 노드를 색으로 채우도록 지정합니다.
4. graphviz.Source(dot_tree): 내보낸 graphviz 형식의 결정 트리를 시각화하기 위해 graphviz.Source를 사용합니다.
피처의 중요도 추출하기
feature_importances_ 속성을 사용하여 피처(feature)의 중요도를 확인할 수 있습니다.

위 코드를 실행하면 각 피처에 대한 중요도가 포함된 배열이 반환됩니다. 이 값은 피처가 모델에 얼마나 기여하는지를 나타내며, 값이 높을수록 해당 피처가 모델의 예측에 중요한 역할을 한다는 것을 의미합니다.
특히, 이 값은 결정 트리 모델이 각 피처를 기반으로 어떻게 분할하는지를 이해하는 데 유용합니다. 중요도가 높은 피처는 분류나 회귀 과정에서 더 큰 역할을 하므로, 모델의 해석이나 피처 선택에 활용될 수 있습니다.
피처의 중요도 시각화하기
barplot 함수를 사용하여 피처의 중요도를 시각화할 수 있습니다. 이를 통해 중요도 값과 피처 이름을 매핑하여 막대 그래프로 표시할 수 있습니다.
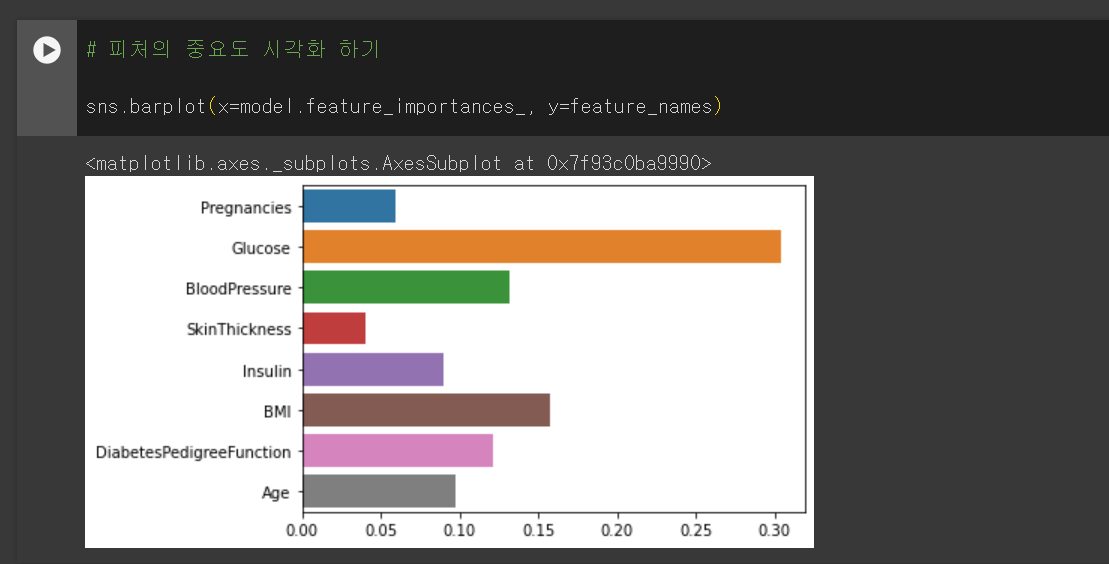
각 막대의 높이는 해당 피처의 중요도를 나타내며, 피처 이름은 각 막대의 위치에 표시됩니다.
이를 통해 어떤 피처가 모델의 예측에 가장 중요한 역할을 하는지를 시각적으로 확인할 수 있습니다.
12 정확도(Accuracy) 측정하기

'y_test - y_predict'는 실제값 y_test에서 예측값 y_predict를 뺀 것입니다. 이를 통해 각 테스트 샘플에 대한 예측과 실제값의 차이를 계산할 수 있습니다.
만약 y_test와 y_predict가 같은 경우에는 차이가 0, 즉 'y_test - y_predict = 0'이 됩니다. 이는 모델이 해당 샘플에 대해 정확히 예측했다는 것을 의미합니다.
하지만 오류가 있다면 '| (y_test - y_predict) | = 1'이라는 결과가 출력됩니다. sum() 함수를 사용하여 이 값들의 합을 구했을 때 나오는 숫자 44는 모델이 예측한 값에서 44개의 오류가 있다는 뜻입니다.
모델의 정확도를 측정하고자 할 때, 100퍼센트 중 몇 퍼센트의 확률로 예측값과 실제값이 일치하는지 백분율로 나타내고자 할 때 다음 세 가지 방법을 이용합니다.
1. 계산으로 구하기

- len(y_test): 테스트 데이터의 총 개수입니다.
- diff_count: 모델이 잘못 예측한 샘플의 개수입니다. 이는 이전에 계산한 예측값과 실제값의 차이를 절대값으로 취한 값입니다.
- (len(y_test) - diff_count): 총 테스트 샘플 중 모델이 올바르게 예측한 샘플의 개수입니다.
- /(len(y_test)): 전체 테스트 샘플 수로 나누어 정확도를 계산합니다. 이는 올바르게 예측한 샘플의 비율을 나타냅니다.
- * 100: 백분율로 표시하기 위해 100을 곱합니다.
2. 미리 구현된 알고리즘 활용하기

scikit-learn에서 제공하는 accuracy_score 함수를 사용하여 모델의 예측 정확도를 계산하는 방법도 있습니다.
1. accuracy_score(y_test, y_predict): y_test와 y_predict를 비교하여 예측 정확도를 계산합니다. 이는 정확하게 분류된 샘플의 비율을 나타냅니다.
2. * 100: 계산된 정확도를 백분율로 변환합니다.
이는 이전에 직접 구현한 방법과 동일한 결과를 제공합니다. scikit-learn의 함수를 사용하면 정확도를 간편하게 계산할 수 있으며, 정확도 이외의 다른 평가 지표도 쉽게 얻을 수 있습니다.
3. DecisionTreeClassifer 모델 자체의 함수를 이용하기

DecisionTreeClassifer 모델 자체의 함수를 이용해서 정확도를 측정할 수도 있습니다. 이 방법은 score 메서드를 사용하여 모델의 점수를 계산합니다.
- model.score(X_test, y_test): X_test 특성 데이터와 y_test 레이블 데이터를 사용하여 모델의 점수를 계산합니다. 이는 주어진 테스트 데이터에 대한 모델의 정확도를 나타냅니다.
- * 100: 계산된 점수를 백분율로 변환합니다.
이는 이전에 사용한 방법들과 동일한 결과를 제공합니다. scikit-learn의 score 메서드를 사용하면 간단하게 모델의 성능을 평가할 수 있습니다.
과제를 하며 어려웠던 점 : 수치형 데이터로 변환, 수치형 데이터가 아닌 컬럼 제외
비만도 데이터 파일은 모든 행이 수치형 데이터였으며, 따로 전처리 과정이 필요하지 않았다.
이와 달리 이번 과제의 데이터는, 'Yes', 'No', 'No phone service'와 같은 문자형 데이터도 포함되어 있었다.
나는 먼저 이분법적으로 나눠지는 'Yes', 'No' 행들을 모두 수치형 데이터로 바꾸어 주는 작업을 하였다.
'Yes'는 1로, 'No'는 0으로 말이다.
코드는 다음과 같다.
# 수치형 데이터로 변환
df = df.replace({'Yes': 1, 'No': 0, 'yes': 1, 'no': 0, 'YES': 1, 'NO': 0})
이렇게 하면 이탈 고객 예측에 아주 중요한 컬럼이 될 지 모르는 'PhoneService' 컬럼이나 'PaperlessBilling' 컬럼 등이 수치형 데이터로 변환되어 회귀 학습을 시킬 수 있게 되었다.
다음은 수치형 데이터로 바꿀 수 없는 컬럼을 제외시키는 과정이다.
'Yes', 'No'와 같이 이분법적으로 나누어지는 행들 말고도 'No internet', 'One year', 'DSL' 등 문자형 데이터가 행으로 나타난 컬럼들도 여럿 있었다. 이들을 모두 제외시켰다.
(다음에는 이들을 모두 제외시키는 것이 아닌, 또다른 숫자형 데이터로 변환하여 회귀모델로 학습시키거나, 문자형 데이터도 학습할 수 있는 다른 모델을 공부해보고 싶다.)
# 수치형 데이터가 아닌 컬럼 제외
df = df.drop(['customerID', 'gender', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaymentMethod'], axis=1)과제하면서 해결하지 못한 의문점: 컬럼 간 종속 관계
주어진 질문들을 바탕으로 과제를 완성하긴 했지만, 그와 별개로 과제 수행 과정에서 해결하지 못한 의문이 있어 정리해본다.
1주차 과제에 사용된 데이터셋의 컬럼과 각 컬럼에 속한 요소들의 set을 살펴보면 다음과 같다.
1. gender: {'Female', 'Male'}
2. SeniorCitizen: {0, 1}
3. Partner: {'No', 'Yes'}
4. Dependents: {'No', 'Yes'}
5. tenure: {0, 1, 2, ... , 72}
6. PhoneService: {'No', 'Yes'}
7. MultipleLines: {'No', 'Yes', 'No phone service'}
8. InternetService: {'Fiber optic', 'No', 'DSL'}
9. OnlineSecurity: {'No', 'Yes', 'No internet service'}
10. OnlineBackup: {'No', 'Yes', 'No internet service'}
11. DeviceProtection: {'No', 'Yes', 'No internet service'}
12. TechSupport: {'No', 'Yes', 'No internet service'}
13. StreamingTV: {'No', 'Yes', 'No internet service'}
14. StreamingMovies: {'No', 'Yes', 'No internet service'}
15. Contract: {'Two year', 'Month-to-month', 'One year'}
16. PaperlessBilling: {'No', 'Yes'}
17. PaymentMethod: {'Electronic check', 'Credit card (automatic)', 'Bank transfer (automatic)', 'Mailed check'}
18. MonthlyCharges: {18.95, 19.8, 20.65, ... }
19. TotalCharges: {'25', '1513.6', '75.45', ... }
20. Churn: {'No', 'Yes'}
회색으로 밑줄 친 요소들에는 공통점이 있다. 바로 해당 요소가 포함된 컬럼은 다른 컬럼들과 독립적이지 않다는 것이다.
'No phone service'가 포함된 컬럼인 'MultipleLines'를 예시로 들면, 'PhoneService' 컬럼의 값에 따라 가질 수 있는 값이 달라진다.
i) 'PhoneService' 컬럼의 값이 'Yes'인 경우:
- 'MultipleLines' 컬럼이 가질 수 있는 값 = {'Yes', 'No'}
ii) 'PhoneService '컬럼의 값이 'No'인 경우:
- 'MultipleLines' 컬럼이 가질 수 있는 값 = {'No phone service'}
위와 같이 'PhoneService'가 'Yes'인 경우 'MultipleLines'는 'Yes'와 'No' 두 가지 값을 가질 수 있는 반면, 'No'인 경우 가질 수 있는 값은 'No phone service' 하나뿐이다.
즉, 다시 말해 'MultipleLines' 컬럼은 'PhoneService' 컬럼에 대하여 종속적인 의미를 지닌다는 것이다.
앞서 부스트코스 강의에서 다룬 데이터셋을 살펴보면 이처럼 직접적으로 종속적인 값을 가지지 않는 경우에 해당한다. 물론 데이터 분석 결과 새로운 상관관계를 찾아낼 가능성이 없지 않지만, 현재 말하고자 하는 컬럼간의 종속 관계는 후차적으로 발견되는 상관관계와는 구분할 필요가 있다고 생각한다.
결론적으로 1주차 과제에서 사용된 데이터셋은 1주차 학습 영상에서 쓰인 데이터셋과 다르게 컬럼간 종속 관계가 명확히 드러났기 때문에, 이를 컴퓨터가 인식할 수 있도록 하는 추가적인 전처리 과정이 필요하다고 생각했지만 방법을 알지 못해 추가적으로 고민해보고 싶다.
'Study > CODE 2기 [프로젝트로 배우는 데이터사이언스]' 카테고리의 다른 글
| [Trillion(1조)] 프로젝트로 배우는 데이터사이언스_2주차 (0) | 2024.03.18 |
|---|---|
| [All in One(2조)] 프로젝트로 배우는 데이터사이언스_2주차 (1) | 2024.03.18 |
| [삼위일체(3조)] 프로젝트로 배우는 데이터 사이언스_2주차 (0) | 2024.03.18 |
| [All in One(2조)] 프로젝트로 배우는 데이터사이언스_1주차 (0) | 2024.03.11 |
| [Trillion(1조)] 프로젝트로 배우는 데이터 사이언스 (0) | 2024.03.10 |



